DeepSeek Open Source AI Models: China's Impact on AI Industry
DeepSeek's open-source AI models are changing the landscape. Learn about their viral growth, model performance, and economic implications.
DeepSeek: Open source AI models from China
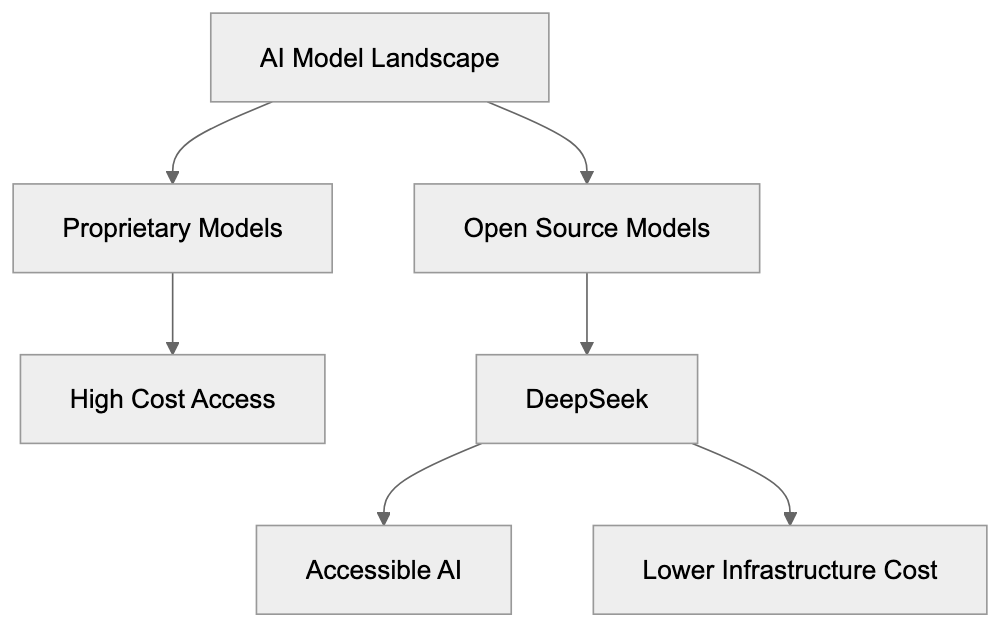
DeepSeek is an AI research company building open-source large language models (LLMs) that rival closed-source alternatives from OpenAI and Anthropic. They focus on cost-effective training methods and release models under permissive licenses, letting developers and businesses avoid expensive API fees.
The company garnered attention with the release of its DeepSeek V3 and DeepSeek R1 models. These models deliver performance comparable to GPT-4 and Claude but are far more affordable to train. Companies like DeepSeek are essential for businesses unable to invest heavily in AI infrastructure, as open-source AI models democratize access to advanced AI capabilities, offering a viable alternative to expensive commercial APIs.
What is DeepSeek
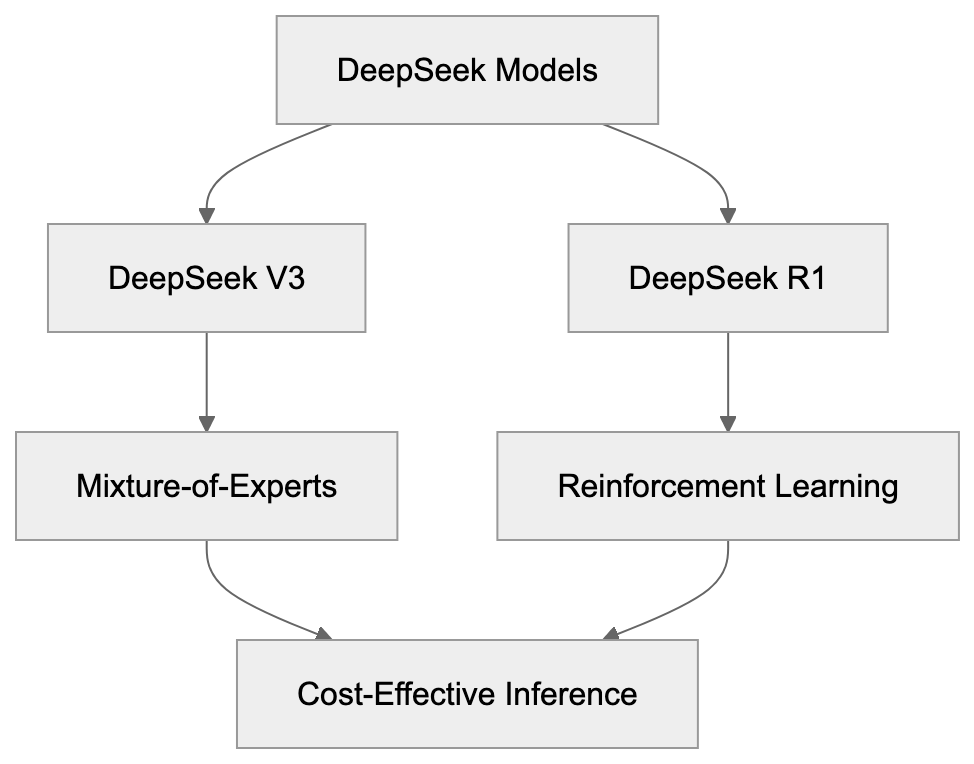
DeepSeek is a Chinese AI research laboratory focused on large language models. Unlike many AI labs, they openly publish model weights and share detailed training methodologies. Their flagship model, DeepSeek V3, has 671 billion parameters using a mixture-of-experts architecture that activates only 37 billion parameters per token, reducing computational costs.
DeepSeek R1, another groundbreaking model, emphasizes reasoning capabilities and employs reinforcement learning techniques similar to OpenAI’s O1 model. DeepSeek’s commitment to transparency is evident in its technical papers detailing training methods and architectural insights, which help other researchers replicate and enhance their work.
DeepSeek Model Architecture Overview:
Purpose of DeepSeek
DeepSeek aims to make advanced AI accessible to all. Commercial AI models, which often require expensive subscriptions, exclude smaller organizations and individual developers. DeepSeek confronts this exclusion by providing models that can be downloaded and operated locally by anyone.
Notably, the cost to train DeepSeek V3 was approximately $5.5 million, a stark contrast to the rumored $100 million spent on GPT-4. This feat demonstrates that effective training methods can rival massive compute budgets. By advancing AI research through open collaboration, DeepSeek allows the research community to build on its work, accelerating innovation across the field.
Applications of DeepSeek Models
Businesses utilize DeepSeek models to avoid vendor lock-in with commercial AI providers, gaining control over data privacy and model customization. Web developers integrate DeepSeek models into applications, using them in place of expensive APIs for tasks like chatbots that process millions of requests. Researchers use these models as baselines for experiments, with open weights allowing deep analysis of model behavior and biases.
AI researchers fine-tune DeepSeek for specific tasks, content marketers generate drafts and content ideas, and small businesses use third-party platforms hosting DeepSeek models. Some cloud providers offer DeepSeek as a cost-effective alternative to pricier options.
Key Facts About DeepSeek
In early 2025, DeepSeek R1 became the number one free app on the United States App Store, signaling a strong demand for AI alternatives. DeepSeek V3 was trained in just two months, using 2048 NVIDIA H800 GPUs. Despite hardware limitations, the model achieved competitive results, with benchmark scores close to GPT-4’s performance. This model runs efficiently, with lower memory usage during inference than similar alternatives, and was released under the MIT license, allowing unrestricted commercial use.
DeepSeek Compared to Alternatives
DeepSeek Development Flow:

Several open-source models compete in the same space, each with unique strengths. Here’s a comparison of key metrics:
| Model | Parameters | Training Cost | MMLU Score | License | Context Length |
|---|---|---|---|---|---|
| DeepSeek V3 | 671B (37B active) | ~$5.5M | 85.6% | MIT | 128K tokens |
| Llama 3.1 405B | 405B | Not disclosed | 88.6% | Llama 3.1 | 128K tokens |
| Qwen 2.5 72B | 72B | Not disclosed | 85.3% | Apache 2.0 | 128K tokens |
| Mistral Large 2 | 123B | Not disclosed | 84.0% | Mistral AI | 128K tokens |
| GPT-4 Turbo | Unknown | ~$100M+ | 86.4% | Proprietary | 128K tokens |
DeepSeek’s transparent low training costs and open licensing are key differentiators. While Llama 3.1 405B excels in performance, its undisclosed training expenses pose a challenge. Qwen 2.5 is another strong competitor, especially among Chinese AI models, while Mistral Large 2 leans toward commercial use. DeepSeek’s mixture-of-experts architecture offers advantages during inference, requiring sophisticated infrastructure compared to dense models. DeepSeek V3 stands out for its cost-effectiveness and accessibility.
Economic Implications of DeepSeek
DeepSeek’s success suggests that massive budgets aren’t the sole pathway to cutting-edge AI models. Algorithmic innovations, as demonstrated by DeepSeek, are equally crucial. This disrupts the AI industry’s economic dynamics, allowing smaller companies and research groups to compete effectively.
Stock market reactions featured price declines for AI infrastructure companies following DeepSeek R1’s launch. Investors questioned the necessity of expensive AI chips given effective models like DeepSeek R1. While these models still require significant compute for training and inference, the cost curve is shifting rapidly.
For businesses, DeepSeek offers a viable alternative to costly API services, moving expenses from API fees to infrastructure investments. This trend hints at the commoditization of basic AI capabilities, with future differentiation coming from data, fine-tuning, and application-specific optimizations.
Technical Architecture and Innovations
DeepSeek V3 employs a mixture-of-experts architecture, activating only eight experts per token. This sparse activation reduces computational demands while maintaining model capacity, thanks to a routing mechanism that learns which experts to activate for different inputs.
DeepSeek enhances performance with multi-token prediction during training, improving sample efficiency. Grouped-query attention reduces memory bandwidth requirements. DeepSeek R1 leverages reinforcement learning from human feedback, producing chain-of-thought outputs for more interpretable reasoning.
DeepSeek publishes comprehensive technical reports, fostering an environment where other researchers can reproduce and expand upon their work, advancing AI research across the field.
Viral Growth and Adoption
DeepSeek’s app soared in app store rankings, surpassing ChatGPT downloads within 48 hours of its launch. The models’ unexpected performance, geopolitical context, and dissatisfaction with ChatGPT’s pricing fueled this viral growth, leading to infrastructure scaling to accommodate the demand. Public scrutiny and questions about data practices followed, underlining the importance of transparency in AI development.
Challenges and Limitations
Despite impressive capabilities, DeepSeek models face several challenges. Running 671 billion parameter models demands significant hardware, even with sparse activation, limiting direct deployment to organizations with substantial infrastructure.
Performance gaps exist compared to top proprietary models on certain tasks, such as coding benchmarks where DeepSeek V3 trails GPT-4 Turbo. Privacy concerns and model biases are ongoing issues, potentially aggravated by open-source fine-tuning.
DeepSeek’s Market Position:
Documentation and community support remain less developed than mature platforms, presenting challenges for developers troubleshooting issues with DeepSeek models.
Future Development and Research Directions
DeepSeek continues to pioneer research into effective training methods and architectures, regularly publishing papers on new techniques and model designs. Future models are expected to push effectiveness boundaries further, possibly extending to multimodal capabilities and improved reasoning.
Collaboration with other open-source AI projects could accelerate development. By sharing techniques and findings, DeepSeek sets an example of transparency influencing other labs, ultimately broadening the impact of AI development innovations.
Summary
DeepSeek provides open-source models with permissive licenses, letting developers and businesses operate without vendor lock-in. Training costs around $5.5 million challenge the assumption that frontier AI requires massive budgets. Benchmark performance places DeepSeek V3 and R1 in competition with models like GPT-4, offering a cost-effective path to advanced AI for developers and businesses.
Frequently Asked Questions
What are the system requirements for running DeepSeek models?
Running DeepSeek models, particularly the 671 billion parameter models, requires substantial hardware resources. Organizations need powerful GPUs and enough memory to accommodate the computational demands, even with the sparse activation feature of the models.
How can I start using DeepSeek models for my projects?
You can download DeepSeek models from their official repository and integrate them into your applications. Detailed documentation and training methodologies are available to guide developers on how to implement and fine-tune these models according to their specific needs.
Are there any limitations to using DeepSeek models compared to proprietary models?
While DeepSeek models offer competitive performance, they may not match proprietary models like GPT-4 Turbo in specific tasks, such as advanced coding benchmarks. Additionally, documentation and community support may be less developed compared to more mature platforms, potentially making troubleshooting more challenging.
What types of applications are best suited for DeepSeek models?
DeepSeek models are suitable for a variety of applications, including chatbots, content generation, and AI research experiments. Businesses seeking to maintain control over data privacy and customizability find these models especially advantageous as they can be run locally.
What are the primary benefits of using open-source AI models like DeepSeek?
The main benefits of using open-source models include cost savings, greater accessibility, and avoidance of vendor lock-in. Developers can modify and optimize the models for specific applications without incurring significant API fees associated with commercial alternatives.
How does DeepSeek's training cost compare to other AI models?
DeepSeek's V3 model was trained at a significantly lower cost of approximately $5.5 million, contrasting sharply with the estimated $100 million spent on training GPT-4. This demonstrates that effective training methods can yield high-quality models without the need for massive budgets.
What future developments can we expect from DeepSeek?
DeepSeek plans to continue advancing its AI models by exploring new training methods and enhancing their architectures. Collaborations with other open-source AI initiatives are also anticipated to accelerate development and broaden the impact of these innovations across the field.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.