
Legacy Anthropic-AI Crawler & ClaudeBot Evolution Guide
Learn about the legacy Anthropic-AI crawler, its transition to ClaudeBot, user-agent strings, and how to block it in robots.txt files.
Table of Contents
- What is the Anthropic-AI Legacy Crawler
- Why the Legacy Anthropic-AI Crawler Existed
- The User-Agent String and Technical Details
- Why Robots.txt Files Still Reference the Legacy Crawler
- How to Block Both Anthropic Crawlers
- Comparison with Other AI Crawlers
- Why Website Owners Block AI Crawlers
- The Evolution from Heritage Crawler to ClaudeBot
- Technical Implementation for Developers
- Impact on SEO and Search Engine Crawlers
- Future of AI Crawlers and Web Scraping
- End
- What is the Anthropic-AI Legacy Crawler
- Why the Legacy Anthropic-AI Crawler Existed
- The User-Agent String and Technical Details
- Why Robots.txt Files Still Reference the Legacy Crawler
- How to Block Both Anthropic Crawlers
- Comparison with Other AI Crawlers
- Why Website Owners Block AI Crawlers
- The Evolution from Heritage Crawler to ClaudeBot
- Technical Implementation for Developers
- Impact on SEO and Search Engine Crawlers
- Future of AI Crawlers and Web Scraping
- End
What is the Anthropic-AI Legacy Crawler
The Anthropic-AI Legacy Crawler was a web scraping bot operated by Anthropic, recognized for creating Claude, their AI assistant. The purpose of this AI crawler was to collect web content crucial for training AI models. Similar to other AI crawlers, it navigated through websites automatically to gather text data, enhancing the company’s language models. The original anthropic-ai crawler is now considered heritage as Anthropic transitioned to a new bot named ClaudeBot. Despite this, references to the old crawler still appear in many robots.txt files on the web. Website owners utilized robots.txt to manage crawler access, helping developers make informed decisions about web crawler blocking for both the legacy and new versions.
Crawler Evolution Timeline:
Why the Legacy Anthropic-AI Crawler Existed
AI companies require vast amounts of text data for model training, a process known as web scraping. The anthropic-ai crawler specifically existed to gather AI training data from publicly accessible websites. Without such bots, AI companies would struggle to construct comprehensive language models. Operating like search engine bots, the crawler followed links, read page content, and stored information, distinguishing itself by focusing on data collection for AI training, a practice that has raised ethical concerns in the tech community. This heritage crawler was pivotal in building Anthropic’s initial datasets before Claude gained popularity. Numerous AI companies, like OpenAI’s GPTBot and Google’s Google-Extended, operate similar crawlers to construct varied training datasets, a practice that became industry standard as large language models surged in 2022 and 2023.
The User-Agent String and Technical Details
The legacy anthropic-ai crawler identified itself with a unique user-agent string appearing in web server logs as:
anthropic-ai
While variations might include additional details, “anthropic-ai” remained the core identifier noticeable in access logs. The bot respected robots.txt directives when configured rightly and adhered to standard crawling protocols like rate limiting to prevent server overload. The new ClaudeBot uses a distinct user-agent string:
ClaudeBot
This transition to ClaudeBot in September 2025 aligned with Anthropic’s updated Claude models, making the anthropic bot more recognizable in association with their Claude product. Modern web logs may show both user-agents, with the legacy crawler appearing in historical logs or outdated infrastructure.
Why Robots.txt Files Still Reference the Legacy Crawler
Numerous websites maintain robots.txt rules to block the anthropic-ai crawler for several reasons. First, website owners haven’t updated their files post-addition of the block. Second, administrators retain these heritage rules as a safety measure against potential reactivation of old crawlers. Third, copying configurations from templates often includes outdated entries. A typical robots.txt entry blocking the heritage crawler reads:
User-agent: anthropic-ai
Disallow: /This entry prevents the crawler from accessing any site portion. Some sites use more nuanced rules allowing specific directories while blocking others. This persistence highlights how website configurations often outlast the technologies they control. Many site owners have separately added blocks for ClaudeBot:
User-agent: ClaudeBot
Disallow: /
AI Crawler Blocking Process:
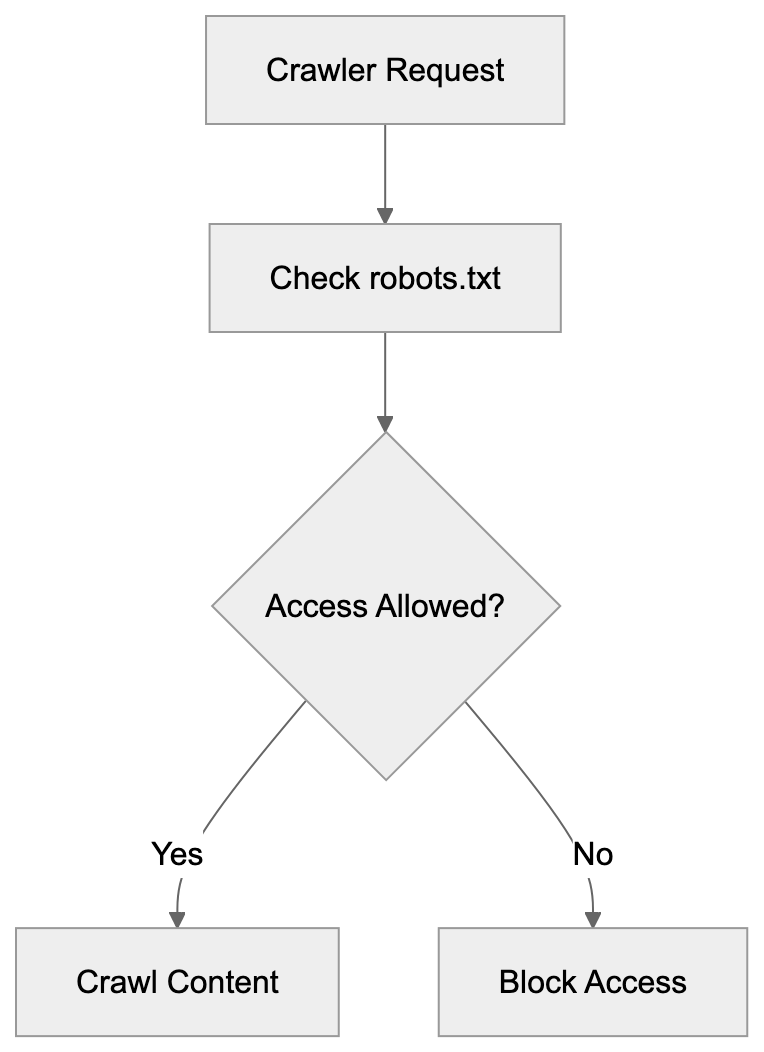
Maintaining both entries ensures protection against both old and new versions, providing a documentation of past blocking decisions and a safety net.
How to Block Both Anthropic Crawlers
To block AI crawlers, edit your robots.txt file located in your website’s root directory. To block both the anthropic-ai legacy crawler and the current ClaudeBot, include these lines:
User-agent: anthropic-ai
Disallow: /
User-agent: ClaudeBot
Disallow: /The slash after Disallow signifies that the entire site is off-limits. Alternatively, block specific sections:
User-agent: ClaudeBot
Disallow: /private/
Disallow: /admin/
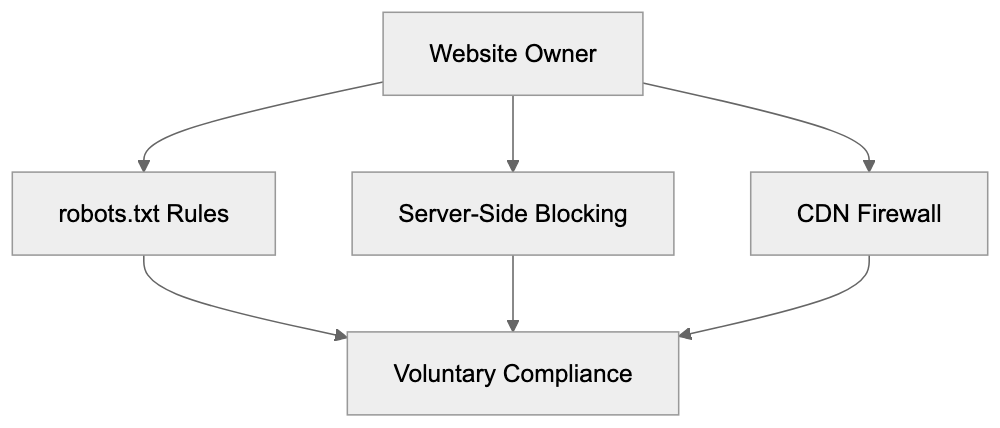
Allow: /public/This method blocks particular directories while permitting others. Note that robots.txt relies on voluntary compliance; well-behaved crawlers respect these rules without technical enforcement. Upon updating robots.txt, changes take immediate effect as crawlers consult this file prior to site access. For web developers using popular platforms, setup varies. WordPress users can edit robots.txt via SEO plugins or file managers, while frameworks like Next.js typically place robots.txt in the public directory. Always validate your robots.txt file to prevent syntax errors that might impede functionality.
Comparison with Other AI Crawlers
Anthropic’s crawlers are not alone in collecting training data. Various AI firms operate similar crawlers. Understanding these assists in making comprehensive blocking decisions. Here’s a comparison of the major AI crawlers:
| Crawler Name | Company | User-Agent | Purpose | Active Status |
|---|---|---|---|---|
| anthropic-ai | Anthropic | anthropic-ai | AI training data | Heritage/Inactive |
| ClaudeBot | Anthropic | ClaudeBot | AI training data | Active |
| GPTBot | OpenAI | GPTBot | AI training data | Active |
| Google-Extended | Google-Extended | AI training data | Active | |
| CCBot | Common Crawl | CCBot | Web archiving/AI data | Active |
| Amazonbot | Amazon | Amazonbot | Search and AI | Active |
Each crawler serves similar functions but is controlled by different companies. GPTBot supports ChatGPT and OpenAI models, Google-Extended assists Bard and Gemini, CCBot enhances the Common Crawl dataset, and Amazonbot aids Alexa and other Amazon AI services. If you decide to block one AI crawler, consider the consistency in blocking all of them:
User-agent: anthropic-ai
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /Web Crawler Management Options:
This extensive approach prevents multiple AI companies from scraping your content. Some site owners might opt for selective blocking depending on the AI services they either support or oppose.
Why Website Owners Block AI Crawlers
Several motivations drive the decision to block AI crawlers such as anthropic-ai and ClaudeBot. Firstly, copyright concerns arise when website content is utilized for commercial AI training without permission or compensation. Secondly, bandwidth and server resources are important, as aggressive crawling can slow websites and increase hosting costs. Thirdly, competitive concerns emerge if AI models might recreate or summarize proprietary content. News organizations and publishers often worry about AI systems potentially replacing site traffic. Fourthly, some website owners reject AI training on principle, opting out of the ecosystem entirely. Fifthly, legal uncertainties surrounding AI training data collection exist, with unclear regulations fostering defensive stances. These concerns have led prominent publishers like The New York Times to implement crawler blocks. Individual bloggers and small businesses also block crawlers to retain control over their content. Ultimately, the decision aligns with each website owner’s priorities and values.
The Evolution from Heritage Crawler to ClaudeBot
Anthropic’s shift from the anthropic-ai crawler to ClaudeBot mirrors the company’s growth and branding efforts. The original crawler was operational during Anthropic’s early, lesser-known phase. As Claude gained recognition, the company aimed for clearer branding. ClaudeBot’s naming convention directly connects the crawler to their flagship product, aligning with industry patterns exemplified by OpenAI’s GPTBot and its link to ChatGPT. The alteration also introduced technical advancements. ClaudeBot likely offers improved rate limiting and more respectful crawling behavior. The user-agent string is now more descriptive and recognizable. From a website owner’s perspective, the change requires rule updates. Rules targeting anthropic-ai need separate entries for ClaudeBot. This created a transitional period where websites blocking the heritage anthropic-ai crawler inadvertently allowed ClaudeBot. This transition to ClaudeBot occurred with the latest Claude models (Opus 4.5, Sonnet 4.5, Haiku 4.5) introduced in September 2025. Maintenance of blocks for both versions persists until Anthropic officially retires the obsolete crawler.
Technical Implementation for Developers
Developers managing websites require efficient methods to block crawlers. Beyond robots.txt, server-side blocking offers stronger control. For Apache servers, block crawlers in the .htaccess file:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} anthropic-ai [NC,OR]
RewriteCond %{HTTP_USER_AGENT} ClaudeBot [NC]
RewriteRule .* - [F,L]This returns a 403 Forbidden response to blocked crawlers, with NC ensuring case-insensitivity. For Nginx servers, include this in your configuration:
if ($http_user_agent ~* (anthropic-ai|ClaudeBot)) {
return 403;
}Node.js applications can implement middleware for user-agent checks:
app.use((req, res, next) => {
const userAgent = req.get('user-agent') || '';
if (userAgent.includes('anthropic-ai') || userAgent.includes('ClaudeBot')) {
return res.status(403).send('Forbidden');
}
next();
});These server-side measures ensure blocking even if crawlers disregard robots.txt. They ensure definitive blocking without relying on voluntary compliance. Content delivery networks like Cloudflare provide bot management features, allowing firewall rule creation to prevent specific user-agent access. For developers utilizing headless CMS or static site generators, robots.txt remains the primary option, often supported through configuration files. Always monitor server logs following block implementation to verify success.
Impact on SEO and Search Engine Crawlers
Blocking AI crawlers does not impact traditional search engine optimization. The anthropic-ai crawler and ClaudeBot are distinct from Google, Bing, or other search engines. Blocking them won’t negatively affect your search rankings. Your robots.txt can allow search engine crawlers while blocking AI ones:
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
User-agent: ClaudeBot
Disallow: /This approach maintains SEO benefits while preventing AI data usage. Google-Extended, for instance, differs from Googlebot, serving specific AI features like Bard. Blocking Google-Extended doesn’t impede regular Google Search indexing. This distinction empowers site owners to choose their level of AI ecosystem involvement. Some SEO tools might flag AI crawler blocks as issues, but these can be ignored intentionally. The practice has grown enough to be seen as standard management. Search engines recognize that blocking AI crawlers is a content owner’s prerogative without penalties for implementation.
Future of AI Crawlers and Web Scraping
The AI crawler landscape is rapidly evolving. As AI technology advances, more companies will likely launch their own crawlers, increasing traffic from new AI startups. Upcoming regulations might necessitate explicit consent for scraping data for AI training. The European Union’s AI Act and similar regulations could influence crawler operations. Industry standards may emerge, providing clearer guidelines for both AI firms and website owners. Some suggest creating compensation systems where AI companies remunerate for training data. Others advocate opt-in models where content creators voluntarily participate. The evolution from anthropic-ai to ClaudeBot showcases adaptive company practices. Anticipate continued rebranding and enhancements from AI companies. Enhanced documentation and transparency might become industry norms, offering more control over content utilization. Currently, robots.txt and server-side blocking remain primary tools. Developers should stay informed about new crawler entries in the market. Regularly updating blocking rules helps retain control over content. The interaction between AI firms and content creators may stay tense until clearer frameworks are established.
End
The heritage anthropic-ai crawler symbolizes a significant phase in AI development history, gathering training data before transitioning to the prominent ClaudeBot. Website owners continue restricting both versions using robots.txt entries and server-side rules. Distinguishing heritage and current crawlers informs developers in decision-making. The broader AI crawler context includes similar bots from OpenAI, Google, and others. Blocking these crawlers doesn’t impede SEO or traditional search engine indexing. Options range from basic robots.txt entries to advanced server-side filtering. As AI technology progresses, expect more crawlers and potential regulations. Sustaining control over your content necessitates staying informed and routinely updating blocking rules. Whether to allow or block AI crawlers depends on personal priorities tied to copyright, bandwidth, and involvement in AI development.
Frequently Asked Questions
What is the primary purpose of the Anthropic-AI Legacy Crawler?
The Anthropic-AI Legacy Crawler was designed to collect text data from the web to train AI models. This web scraping process allowed Anthropic to build comprehensive datasets necessary for developing their language models.
How do I block both the anthropic-ai legacy crawler and ClaudeBot?
To block both crawlers, update your robots.txt file in your website's root directory with the following lines:
User-agent: anthropic-ai. This disallows both crawlers from accessing your entire site.
Disallow: /
User-agent: ClaudeBot
Disallow: /
What are the implications of blocking AI crawlers on my website?
Blocking AI crawlers will not negatively impact your website's SEO or search engine rankings, as AI crawlers differ from traditional search engines. You can allow search engine bots while blocking AI bots by specifying rules in your robots.txt file.
Why do many websites still reference the legacy anthropic-ai crawler in their robots.txt files?
Websites continue to reference the legacy crawler because they may not have updated their files after its deactivation. Some administrators retain these entries as a precautionary measure against potential reactivation, ensuring continued protection.
How can I implement server-side blocking for AI crawlers?
For server-side blocking, you can use configuration files like .htaccess for Apache servers or specific rules in the Nginx configuration. This allows you to return a 403 Forbidden response for requests from specific user agents, providing stronger control than robots.txt.
What ethical concerns are associated with web scraping for AI training?
Ethical concerns primarily revolve around copyright issues when content is used without permission, potential server overload from aggressive crawling, and data privacy. Website owners often worry that AI training models may replicate or summarize their content, leading to lost traffic and revenue.
What future developments can we expect in the landscape of AI crawlers?
The landscape of AI crawlers is expected to evolve with new regulations and potentially more explicit consent requirements for web scraping. As industry standards emerge, we may see enhanced transparency and compensation systems for data usage, alongside the ongoing development and rebranding of existing crawlers.