Understanding Archive.org_bot: Wayback Machine Crawler
Learn about Archive.org_bot, the Internet Archive crawler that preserves the web. Discover its purpose, how it works, and how to manage it.
Introduction
The Archive.org_bot is the web crawler that powers the Internet Archive’s Wayback Machine bot. This bot systematically visits websites across the internet to create snapshots and engage in web preservation for future generations. Web archiving tools like this exist because the internet is constantly changing. Websites get updated, redesigned, or shut down completely. Without preservation efforts, valuable information would disappear forever. The Archive.org_bot has been crawling the web since 1996, building one of the largest digital libraries in existence, including over 866 billion web pages as of 2024. It collects billions of web pages, creating a historical record of how the internet has evolved over nearly three decades. Understanding this Internet Archive crawler helps website owners and developers make informed decisions about web archiving.
What is the Archive.org_bot
The Archive.org_bot is an automated web crawler operated by the Internet Archive. It systematically browses websites and saves copies of web pages to build the Wayback Machine archive. The bot identifies itself in its user agent string, making it easy to detect in server logs.
When the crawler visits a website, it downloads the HTML content, images, stylesheets, and other resources needed to reconstruct the page later. The crawling process happens continuously, with the bot revisiting sites at different intervals based on various factors. Some high-profile sites get crawled more frequently than personal blogs or static pages.
Web Crawling Process:
The bot respects standard web protocols like robots.txt files that tell crawlers which parts of a site to avoid. Website owners can control whether Archive.org_bot indexes their content through these configuration files. The crawler operates from multiple IP addresses and servers to handle the massive scale of website crawling.
Why Archive.org_bot Exists and Its Purpose
The primary purpose of Archive.org_bot is digital preservation. The internet loses content every day when websites go offline, get redesigned, or delete old posts. Researchers need access to historical web content to study how information spreads, how websites evolved, and how culture changed over time. Journalists use the Wayback Machine to verify facts and recover deleted statements from public figures. Legal professionals reference archived pages as evidence in court cases.
The Internet Archive is a nonprofit organization dedicated to universal access to knowledge. Their mission includes preserving cultural artifacts in digital form. The web represents a significant portion of human knowledge and culture in the modern era. Without systematic archiving, this knowledge would vanish as servers shut down and domains expire. The bot makes this preservation possible by automatically capturing snapshots before content disappears. It creates a public resource that anyone can access for free, unlike commercial archiving services.
How Businesses and Users Interact with Archive.org_bot
Digital Preservation Mission:

Most website owners never actively interact with the Archive.org_bot. The crawler works in the background, visiting public websites without requiring permission. However, businesses can control the bot’s access through several methods. The robots.txt file allows site administrators to block specific crawlers or restrict access to certain directories.
Website owners who want to prevent archiving can add rules that exclude the Archive.org_bot specifically. Some companies choose to block the crawler for competitive reasons or to protect proprietary information. Others accept archiving as a way to preserve their digital history and brand evolution.
Individual users interact with the Internet Archive primarily through the Wayback Machine interface. They search for archived versions of websites by entering URLs. The service shows a calendar view of available snapshots across different dates. Users can browse historical versions of pages to see how sites looked years or decades ago. The Internet Archive also allows users to request immediate archiving of specific pages through their “Save Page Now” feature. This proves useful when someone wants to preserve a particular version of a page before it changes.
Technical Details and Configuration
The Archive.org_bot identifies itself with a specific user agent string in HTTP requests. The current user agent includes “archive.org_bot” along with additional information about the crawler. Server administrators can check their access logs for this string to monitor crawler activity. To block the bot, website owners add specific directives to their robots.txt file. A simple rule like “User-agent: archive.org_bot” followed by “Disallow: /” blocks the entire site. More granular control allows blocking specific directories while permitting access to others.
The Internet Archive respects these restrictions and will not archive blocked content. Website owners can also request removal of already archived pages through the Archive.org website. The removal process requires verification that the requester controls the domain. Legal requests like DMCA takedowns can also result in content removal from the archive.
The crawler operates at a respectful rate to avoid overwhelming web servers. It does not attempt to bypass authentication or access private areas of websites. The bot only archives publicly accessible content that any visitor could see.
Comparing Archive.org_bot to Similar Web Crawlers
Several organizations operate web crawlers for different purposes. Understanding how Archive.org_bot compares helps contextualize its role in the broader ecosystem.
| Crawler | Primary Purpose | Commercial | Respect robots.txt | Public Access |
|---|---|---|---|---|
| Archive.org_bot | Web preservation | No | Yes | Yes |
| Googlebot | Search indexing | Yes | Yes | No |
| Bingbot | Search indexing | Yes | Yes | No |
| Common Crawl | Dataset creation | No | Yes | Yes |
| Applebot | Search indexing | Yes | Yes | No |
Googlebot and Bingbot crawl the web to build search engine indexes. They focus on current content rather than historical preservation. These crawlers visit sites more frequently than Archive.org_bot to keep search results fresh. The crawled data remains proprietary and serves commercial search products.
Web Crawler Comparison:
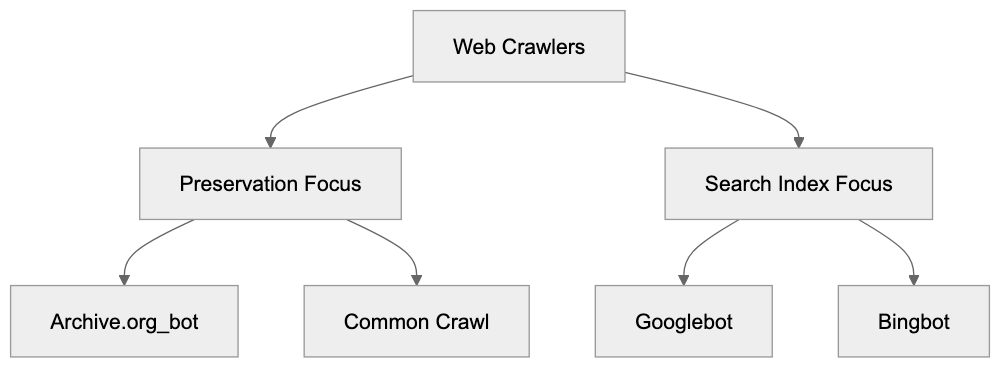
Common Crawl operates similarly to the Internet Archive, but focuses on creating open datasets for research and AI crawlers. Their archives get used extensively in machine learning applications. The data is freely available, but requires more technical knowledge to access compared to the Wayback Machine. Applebot powers Apple’s search features and Siri responses. Like other commercial crawlers, it prioritizes current content over historical archiving. All these crawlers respect robots.txt directives, though their specific behaviors vary slightly.
Legal and Ethical Considerations
Web archiving raises important legal questions about copyright and ownership. The Internet Archive operates under the belief that preserving public web content serves the public interest. Courts have generally sided with this interpretation, though specific cases vary by jurisdiction. Website owners retain copyright over their content even when archived. The Archive.org_bot does not claim ownership of crawled material. Some countries have legal deposit laws that explicitly permit web archiving by national libraries.
The United States does not have complete legislation specifically addressing web archiving. This creates some legal uncertainty around the practice. The Internet Archive has faced lawsuits over specific archived content, particularly regarding copyrighted materials. They respond to legitimate removal requests and legal challenges. Privacy concerns also arise when personal information gets archived. Old blog posts, forum discussions, or social media pages may contain information people later want removed. The Internet Archive balances preservation with privacy by accepting removal requests for sensitive personal data. Ethical web archiving means respecting both the historical record and individual privacy rights.
Excluding Pages from Archive.org_bot
Website owners have several options for controlling what Archive.org_bot archives. The most common method uses the robots.txt file located at the root of the domain. Adding a specific user agent rule for “archive.org_bot” tells the crawler which paths to avoid.
A complete site exclusion looks like this in robots.txt format. The user agent line specifies the crawler, followed by disallow rules for paths. Excluding everything uses a forward slash after the disallow directive. More selective exclusion specifies particular directories or file patterns. The crawler checks the robots.txt file before accessing any pages on a site. Changes to robots.txt take effect on the next crawl, but do not remove already archived content.
For removing existing archives, website owners must submit a request through the Internet Archive website. The exclusion request form requires the URL and verification of domain ownership. Processing removal requests can take several weeks depending on the volume of submissions. The Internet Archive also honors meta tags in HTML that indicate archiving preferences. The noarchive meta tag signals that a page should not be cached or archived. This provides page-level control beyond the site-wide robots.txt configuration.
The Impact of Web Preservation
The work of Archive.org_bot has created a very useful resource for researchers, journalists, and the general public. Academic studies regularly cite archived web pages as primary sources. Historical research increasingly relies on digital records preserved by services like the Wayback Machine.
The archive has documented major world events as they unfold online. News websites, social media reactions, and official statements get preserved even after deletion or modification. This creates accountability for public figures and organizations. Deleted tweets, revised press releases, and disappeared blog posts remain accessible through the archive.
Cultural preservation extends beyond news and politics. The Internet Archive captures web design trends, online communities, and digital art that might otherwise vanish. Early versions of major websites show how internet culture evolved from simple text pages to complex multimedia experiences.
Educational value comes from seeing how information presentation and user interfaces change over time. The archive also serves practical purposes for web developers and businesses. Companies can review their historical branding and marketing approaches. Developers can study how successful websites implemented features across different technological eras.
End
The Archive.org_bot is the primary crawler for the Internet Archive’s web preservation mission. It systematically captures snapshots of public websites to build the Wayback Machine archive. This free resource provides access to billions of archived web pages dating back to 1996. The crawler respects standard web protocols and allows website owners to control archiving through robots.txt files. Understanding how Archive.org_bot works helps website administrators make informed decisions about their digital preservation.
The bot differs from commercial crawlers by focusing on historical preservation rather than search indexing. Legal and ethical considerations surround web archiving, but the practice generally serves the public interest. Website owners can exclude content through technical configurations or removal requests. The resulting archive provides immense value for research, accountability, and cultural preservation. As the web continues evolving, systematic archiving becomes increasingly important for maintaining our digital history.
Frequently Asked Questions
How can I check if my website is being crawled by Archive.org_bot?
You can monitor your website's server logs for the user agent string that identifies Archive.org_bot. Look for entries that include 'archive.org_bot' to see when the crawler accessed your site.
Are there ways to prevent Archive.org_bot from archiving my content?
Yes, you can use the robots.txt file to specify rules that instruct Archive.org_bot not to crawl or archive certain parts of your website. Additionally, you can use meta tags such as 'noarchive' for specific pages.
What should I do if I want to remove an archived page from the Internet Archive?
You can submit a removal request through the Internet Archive's website. You'll need to provide the URL of the page you want removed and verify that you own the domain.
Can I manually request that a page be archived right now?
Yes, the Internet Archive offers a 'Save Page Now' feature that allows users to request immediate archiving of specific pages. This can be useful to capture a version of a page before it changes.
How often does Archive.org_bot revisit my site?
The frequency with which Archive.org_bot crawls your site varies depending on several factors, including the site's prominence and the rate of content change. Popular sites are generally crawled more often than less frequented ones.
Is there a legal framework governing web archiving?
While there are legal considerations regarding copyright and privacy, the Internet Archive operates under the belief that archiving public content serves the public interest. Courts have typically upheld this in various jurisdictions, but laws can vary.
What types of content are generally archived by Archive.org_bot?
Archive.org_bot primarily archives publicly accessible web pages, which can include text, images, stylesheets, and other resources. It does not archive content behind paywalls or authentication.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.