Understanding Bravebot: Brave Search's Independent Crawler
Explore Bravebot, the crawler for Brave Search's privacy-focused engine, covering its purpose, user-agent, and AI features.
Introduction
Bravebot is the web crawler that powers Brave Search, a privacy-focused search engine launched by Brave Software in 2021. Unlike most search engines that lean on Google or Bing, Brave Search built its own index from scratch. This necessitated creating a dedicated web crawler to explore and collect web content. Bravebot systematically browses the internet, following links from page to page, and gathering data about what exists online, similar to other search engine crawlers like Googlebot. Without such web crawlers, search engines couldn’t resolve queries or display relevant results. What sets Bravebot apart is its design, centered around privacy, and its operation independent of big tech companies.
What is Bravebot
Web Crawler Operation Overview:
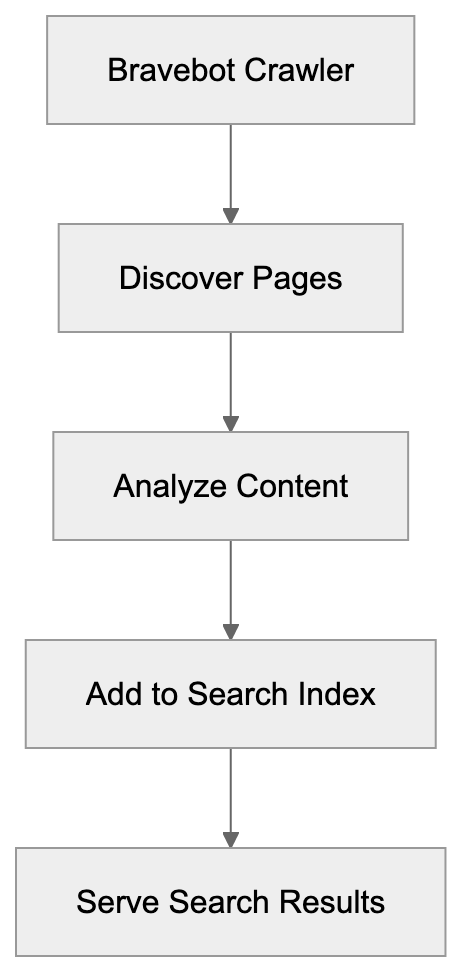
Bravebot is an automated web crawler that gathers data for Brave Search’s search index. It traverses websites across the internet, reading their content and storing information about those pages. The crawler follows inter-page links to uncover new content. Upon discovering a page, it analyzes its text, images, and structure. This data is transmitted back to Brave’s servers, processed, and added to the search index. Bravebot identifies itself with a specific user-agent string: “Mozilla/5.0 (compatible; Bravebot/1.0; +https://brave.com/search/crawler)”, allowing website owners to recognize it and manage access accordingly. They can decide whether to allow or block it from accessing their site by recognizing this user-agent string.
Why Bravebot Exists and Its Purpose
Brave Software developed Bravebot to establish an independent search engine index. Unlike other alternative search engines that depend on Google’s or Bing’s results, Brave sought complete autonomy from big tech platforms. This required crawling the web independently and building a proprietary database of websites. The goal is both simple and ambitious: to create a search engine that doesn’t rely on competitors for data. This independence allows Brave to manage what gets indexed and determine how results are ranked. Moreover, it enables them to implement privacy features free from third-party restrictions. Bravebot runs continuously, exploring billions of pages, discovering new websites, checking for updates on existing ones, and removing obsolete links, ensuring that Brave Search’s index remains fresh and relevant. This constant activity ensures Brave Search’s index remains fresh and relevant. Without their own crawler, Brave Search couldn’t function as a truly independent search engine, remaining reliant on other companies for search results, which contradicts their mission of user privacy and independence.
How Bravebot is Used
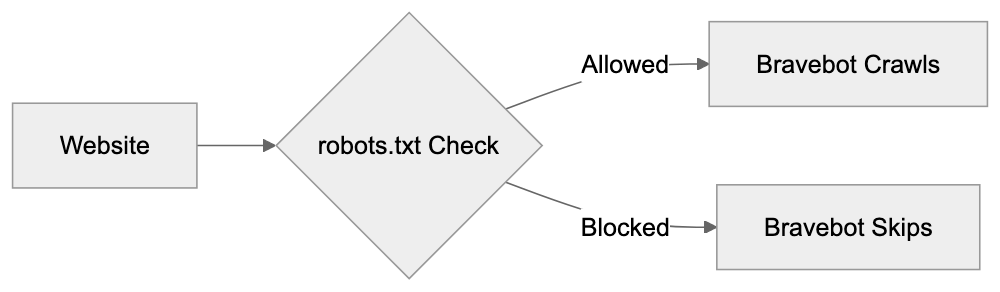
Website owners and developers interact with Bravebot through standard web protocols. The crawler adheres to robots.txt files that instruct bots on what they can and cannot access. If a website’s robots.txt file blocks Bravebot, the crawler won’t access those restricted areas. Brave Search uses the data collected by Bravebot to answer search queries. When a user searches on Brave, the engine checks its index, built by Bravebot, for relevant pages. The results stem directly from Brave’s database, not from Google or Bing. SEO professionals and content marketers need to understand Bravebot to improve search visibility. Being indexed by Bravebot means appearing in Brave Search results, which is increasingly important as Brave Search gains traction. The crawling frequency varies: popular sites with frequently updated content are crawled more often, while smaller or less active sites might experience less frequent visits. Web developers can check their server logs, using the user-agent string, to identify Bravebot.
Bravebot Access Control:
Privacy Aspects and Data Collection
Brave Search promotes itself as privacy-focused, influencing how Bravebot operates. Brave Software asserts that they don’t track individual users through the crawler. Bravebot collects publicly available web content, not personal user data. However, it does encounter IP addresses and server information during site visits. Brave states that this technical data isn’t used to create user profiles. The content collected goes into the search index, a standard practice for search engines. The distinction lies in how Brave handles search query data, claiming not to track or profile users. Although separate from the crawler, it’s integral to their overall privacy approach. Website owners should know that any publicly accessible content can be crawled by Bravebot. To avoid content being indexed, use robots.txt or password protection. Bravebot follows standard protocols and respects technical restrictions, behaving like other major search crawlers in terms of access, as outlined in the Robots Exclusion Protocol.
Blocking Bravebot and Control Options
Website owners can block Bravebot using robots.txt, a standard method for controlling crawler access. Adding “User-agent: Bravebot” followed by “Disallow: /” blocks the entire site. Specific directories or pages can also be restricted:
User-agent: Bravebot
Disallow: /To block specific sections:
User-agent: Bravebot
Disallow: /private/
Disallow: /admin/Some websites block Bravebot to remain indexed exclusively by major search engines, while others block all crawlers except specific ones, based on traffic goals and privacy concerns. Blocking Bravebot prevents your site from appearing in Brave Search results. Although Brave Search has a smaller market share, exclusion might mean missing potential traffic as it grows. An option exists to allow crawling but request not to cache pages, achievable through meta tags or HTTP headers. This permits indexing without storing page copies.
Bravebot and AI Training Data
This topic interests developers and AI researchers. Brave is developing AI features, including a chatbot called Leo. A key question is whether Bravebot collects data for AI training. Brave acquired Tailcat in 2021, contributing to search capabilities. However, specific details about provided technology require Brave’s verification. Brave hasn’t explicitly stated that Bravebot data is used for AI training, but they are developing AI products. It’s plausible that search index data might be utilized for these purposes. Many search engines use crawled data for AI training; Google and Microsoft, for example, use their search indexes for language models. Brave hasn’t made clear public statements about using crawled data for AI training. For website owners concerned about AI training, this uncertainty persists. Standard robots.txt blocking prevents crawling entirely. Currently, there’s no specific directive to allow indexing while preventing AI training for Bravebot. The AI landscape changes swiftly, and companies update their data usage policies. Checking Brave’s documentation for the latest information on data usage is advisable.
Comparison with Other Search Crawlers
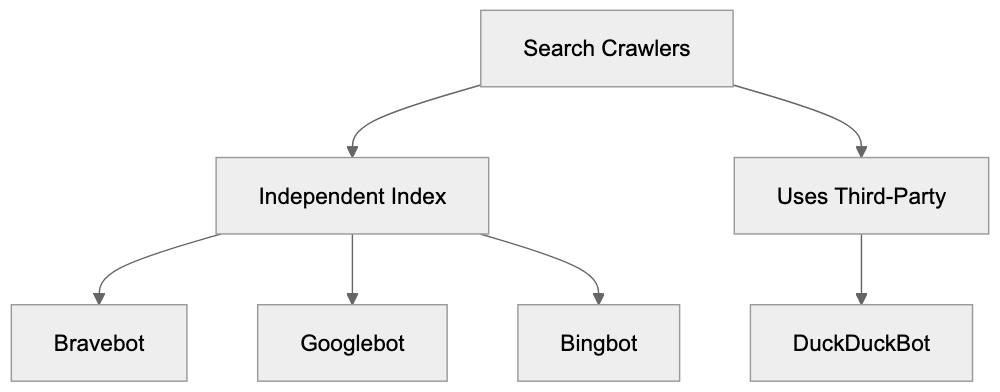
Bravebot compared to other major search engine crawlers:
| Crawler | Search Engine | User-Agent | Independence | Privacy Focus | AI Training |
|---|---|---|---|---|---|
| Bravebot | Brave Search | Bravebot/1.0 | Fully independent | High | Unclear |
| Googlebot | Googlebot/2.1 | Independent | Low | Yes, confirmed | |
| Bingbot | Bing | bingbot/2.0 | Independent | Medium | Yes, confirmed |
| Applebot | Apple | Applebot/0.1 | Independent | High | Limited |
| DuckDuckBot | DuckDuckGo | DuckDuckBot/1.0 | Uses Bing results | High | No, uses others |
Bravebot is newer than Googlebot and Bingbot, with a smaller index and less extensive web crawling. Google’s crawler visits billions of pages daily, while Bravebot’s scale is smaller but growing. Bravebot’s privacy positioning differentiates it from Google and Bing, which extensively use crawled data for ads and tracking. Brave claims not to engage in such practices. Applebot shares a similar privacy focus, but Apple Search isn’t a full public search engine. DuckDuckGo, relying on multiple sources including Bing, doesn’t have a fully independent crawler. Bravebot offers Brave true independence. For blocking purposes, methods are consistent across all crawlers: employ robots.txt with the specific user-agent name. Each crawler respects these standard protocols.
Technical Details for Developers
Crawler Comparison Positioning:
The Bravebot user-agent string is: “Mozilla/5.0 (compatible; Bravebot/1.0; +https://brave.com/search/crawler)”. This appears in server logs when the bot visits your site, with an included URL pointing to information about the crawler. Bravebot respects standard crawl-delay directives in robots.txt; if set, the bot waits the specified number of seconds between requests, preventing server overload from aggressive crawling. The crawler supports standard meta tags like noindex and nofollow, which tell Bravebot (and other crawlers) how to handle specific pages in your HTML. Brave provides a verification process for webmasters, though less developed than Google Search Console, which is expected as Brave Search is newer. The crawler correctly identifies itself and doesn’t disguise its identity, unlike less reputable crawlers that might spoof user-agents. Bravebot follows standard protocols: 404 errors are noted and not indexed, 301 redirects are followed, and 503 errors are treated as temporary, with the bot retrying later.
Impact on SEO and Website Traffic
Brave Search’s market share is minor compared to Google, with estimates putting it below 1% of global search traffic. Consequently, most sites see minimal traffic from Brave Search, but the engine is growing. It’s attracting privacy-conscious users, and for certain niches, like tech and privacy-focused audiences, Brave Search traffic might be more significant. SEO for Bravebot isn’t fundamentally different from general SEO practices: create quality content, use proper HTML structure, and make your site crawlable. These basics apply across all search engines. There’s no evidence Brave’s ranking algorithm diverges heavily from standard approaches; it likely uses factors such as content relevance, links, and site quality. Specific ranking factors aren’t publicly disclosed. Improving specifically for Bravebot isn’t a priority for most businesses yet. Focus on Google and Bing for maximum reach, but don’t actively block Bravebot unless necessary. Allowing the crawl costs little and may bring future traffic as Brave Search grows. Monitor server logs to track Bravebot visits, gaining insights into how Brave assesses your site’s importance and update frequency.
Future of Bravebot and Independent Search
Brave Search signifies a move toward independent search infrastructure. Other projects like Mojeek and Kagi are also building independent indexes, beneficial for web ecosystem diversity. Dependence on Google creates a single control point. Bravebot will likely grow smarter as Brave invests in search technology. Anticipate improved crawling efficiency, better content understanding, and faster index updates. The AI data use question is crucial. As Brave develops AI products, how they use crawler data will matter to website owners and content creators. Will they provide opt-out mechanisms for AI training? Brave Search’s success partially hinges on Bravebot’s effectiveness; a better crawler means a better index, yielding superior search results, encouraging adoption. Developers and site owners should treat Bravebot like any legitimate search crawler; allow access unless there are specific reasons not to, contributing to search engine diversity and competition.
Conclusion
Bravebot is the web crawler driving Brave Search’s independent search index. Operating similarly to other search crawlers, it’s distinguished by its privacy focus. Bravebot visits websites, collects publicly available content, and integrates it into Brave’s search database. Website owners can control Bravebot access via robots.txt files and meta tags. The user-agent string aids in identification through server logs. Although Brave Search currently holds a small market share, it’s growing among privacy-conscious users. The relationship between Bravebot and AI training remains opaque; while Brave develops AI products, they haven’t explicitly stated how crawler data is used for training. This evolving area merits observation. Allowing Bravebot makes sense for most websites, as it incurs minimal cost and may bring future traffic. Independent search engines like Brave, distinct from Google or Microsoft, benefit the web, and Bravebot is essential to achieve that independence.
Frequently Asked Questions
How does Bravebot differ from other web crawlers?
Bravebot is designed to operate independently from large tech companies like Google or Bing, focusing on privacy. While it functions similarly to other crawlers by collecting publicly available web content, it does not track individual user data, setting it apart in the search engine landscape.
Can I block Bravebot from crawling my website?
Yes, you can block Bravebot by using the robots.txt file. You can specify directives such as 'Disallow: /' to prevent the crawler from accessing your entire site or restrict access to specific directories as needed.
What should I consider when allowing Bravebot to crawl my content?
Allowing Bravebot can increase your website's visibility in Brave Search, which is growing among privacy-conscious users. However, if you have concerns about indexing, ensure your content is publicly available and use the appropriate directives in your robots.txt file to manage access.
What impact does being indexed by Bravebot have on my site's SEO?
Indexing by Bravebot might contribute to your site's visibility on Brave Search, which can be beneficial as its user base grows. However, SEO practices for Bravebot generally align with standard methods, focusing on quality content and proper site structure.
Is Bravebot collecting data for AI purposes?
Currently, it's unclear if data collected by Bravebot is used for AI training purposes. Brave has not specifically stated this, so website owners concerned about AI training should monitor updates from Brave regarding their data usage policies.
How frequently does Bravebot crawl websites?
The crawling frequency varies; popular sites with frequently updated content are crawled more often, while less active sites may experience less frequent visits. Monitoring your server logs can help you understand how often Bravebot accesses your site.
Will allowing Bravebot to crawl my site incur additional costs?
No, allowing Bravebot to crawl your site does not incur direct costs. It is a standard practice that can potentially help increase traffic without any financial burden.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.