Claude-SearchBot Guide: Anthropic's Search Indexing Crawler
Learn how Claude-SearchBot indexes web content for Anthropic's search features. User-agent strings, blocking methods, and key distinctions explained.
Introduction
Claude-SearchBot is Anthropic’s specialized web crawler designed for search indexing and collecting web content. This AI crawler bot operates separately from ClaudeBot, which is used for general AI training purposes. The Anthropic search crawler supports search indexing within Claude AI’s assistant. Web crawlers like Claude-SearchBot gather and organize information from the internet for specific purposes. For website owners and developers, understanding how this bot works is crucial for managing server resources and controlling what content gets indexed. The bot respects standard web protocols like robots.txt and provides clear identification through its user-agent string. Knowing the difference between Claude-SearchBot and other Anthropic crawlers helps make informed decisions about allowing or blocking these bots on your site.
What is Claude-SearchBot
Claude-SearchBot is a web crawler operated by Anthropic. It scans websites and collects content to build an index for search functionality. This bot is distinct from ClaudeBot, which crawls the web for training data for Anthropic’s AI models. The AI crawler bot focuses specifically on enabling Claude to retrieve current information. When the bot visits your website, it identifies itself through a specific user-agent string: ClaudeBot (Search). This clear identification allows webmasters to distinguish it from other crawlers. The bot follows standard web crawling etiquette and checks robots.txt files before accessing content. It operates at a controlled rate to avoid overwhelming servers. The crawler collects publicly available web pages, similar to how Google or Bing crawlers work for their search engines.
How Claude-SearchBot Works:
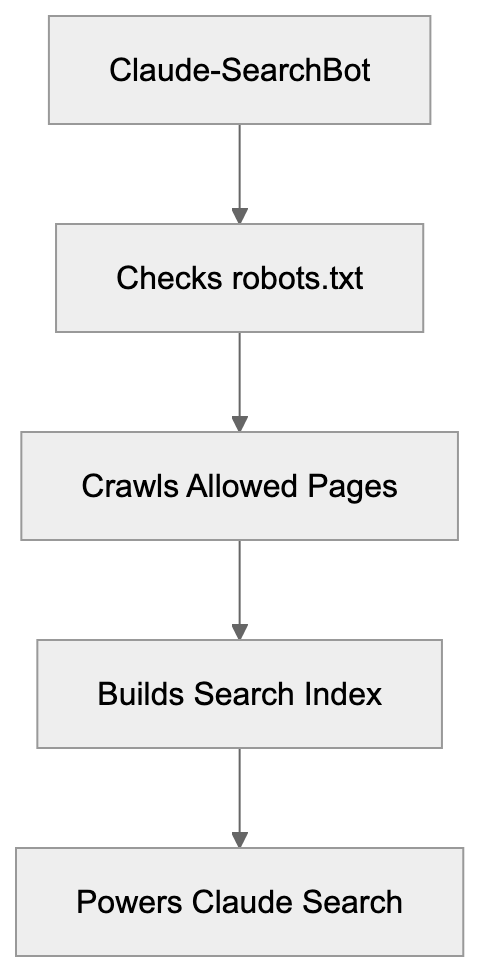
Purpose and Why It Exists
Anthropic created Claude-SearchBot to power search capabilities within their Claude AI assistant. Without such a crawler, Claude would be limited to information from its training data, which has a knowledge cutoff date. The search bot enables Claude to access current information, recent news, updated documentation, and fresh content published after the model’s training period. This makes the AI assistant more useful for queries requiring up-to-date information. Search indexing is a common practice among AI companies developing assistants with real-time information retrieval capabilities. The bot helps Anthropic compete with other AI services that offer web search capabilities. By maintaining their own crawler and index, Anthropic can control the quality and relevance of search results provided to Claude users. The separate crawler also allows different crawling policies compared to their training data collection bot. Website owners can choose to allow search indexing while blocking training data collection, or vice versa.
How Companies and Users Interact With It
Claude-SearchBot vs ClaudeBot:
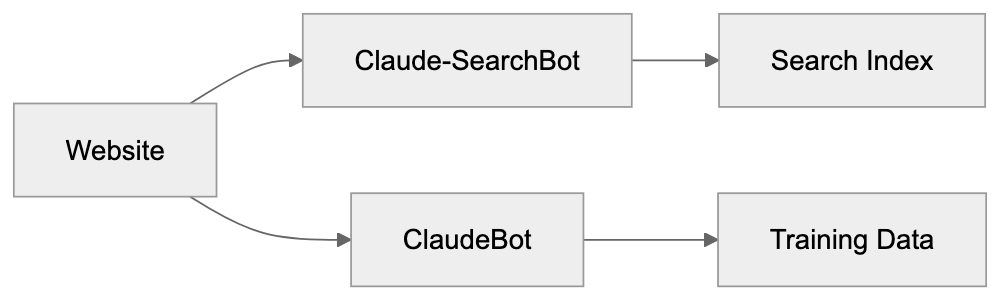
Website owners encounter Claude-SearchBot through their server logs and analytics tools. The bot appears as a visitor with the distinct user-agent string, ClaudeBot (Search). Most websites allow this crawler by default unless specific blocking rules are implemented. When users interact with Claude and ask questions requiring current information, Claude may use the indexed content collected by this bot. The process is invisible to end users, who simply see Claude providing up-to-date information. For businesses running websites, deciding whether to allow Claude-SearchBot involves considering several factors. Allowing the bot can increase visibility within Claude’s responses, potentially driving traffic. Blocking it prevents Anthropic from indexing your content for search purposes. The bot respects standard robots.txt directives, making it straightforward to control access. Companies with content behind paywalls or member-only areas typically block all crawlers or use proper authentication barriers. Public-facing businesses often allow search crawlers to increase discoverability.
User-Agent String and Blocking Methods
The Claude-SearchBot identifies itself with the user-agent string: ClaudeBot (Search). This precise identification is essential for webmasters who want to allow or block the bot selectively. To block Claude-SearchBot specifically, add rules to your robots.txt file. Here’s how to block it:
User-agent: Claude-SearchBot
Disallow: /This directive tells the bot not to crawl any part of your site. You can also block specific directories while allowing others:
User-agent: Claude-SearchBot
Disallow: /private/
Disallow: /members/
Allow: /public/To block both Claude-SearchBot and ClaudeBot (the training data crawler), use separate entries:
User-agent: Claude-SearchBot
Disallow: /
User-agent: ClaudeBot
Disallow: /Server-level blocking is possible through .htaccess files for Apache servers or nginx configuration files. This method provides more control and can return specific HTTP status codes. The bot respects these blocking mechanisms and will not crawl content marked as disallowed. Remember, robots.txt is a public file, so your blocking preferences are visible to anyone. The bot operates separately from ClaudeBot, so blocking one does not automatically block the other.
Comparison With Alternative AI Crawlers
Several AI companies operate web crawlers for similar purposes. Understanding how Claude-SearchBot compares helps website owners make informed decisions about crawler management.
| Crawler Name | Company | User-Agent String | Primary Purpose | Blocking Impact |
|---|---|---|---|---|
| ClaudeBot (Search) | Anthropic | ClaudeBot (Search) | Search indexing for Claude | Blocks search features only |
| ClaudeBot | Anthropic | ClaudeBot | AI training data collection | Blocks training data usage |
| GPTBot | OpenAI | GPTBot/1.0 | AI training data collection | Prevents ChatGPT training |
| Google-Extended | Google-Extended | AI training (Bard/Gemini) | Blocks AI training, not search | |
| Bingbot | Microsoft | Mozilla/5.0 (compatible; bingbot/2.0) | Search indexing and AI | Affects Bing search and AI |
Crawler Blocking Decision Flow:
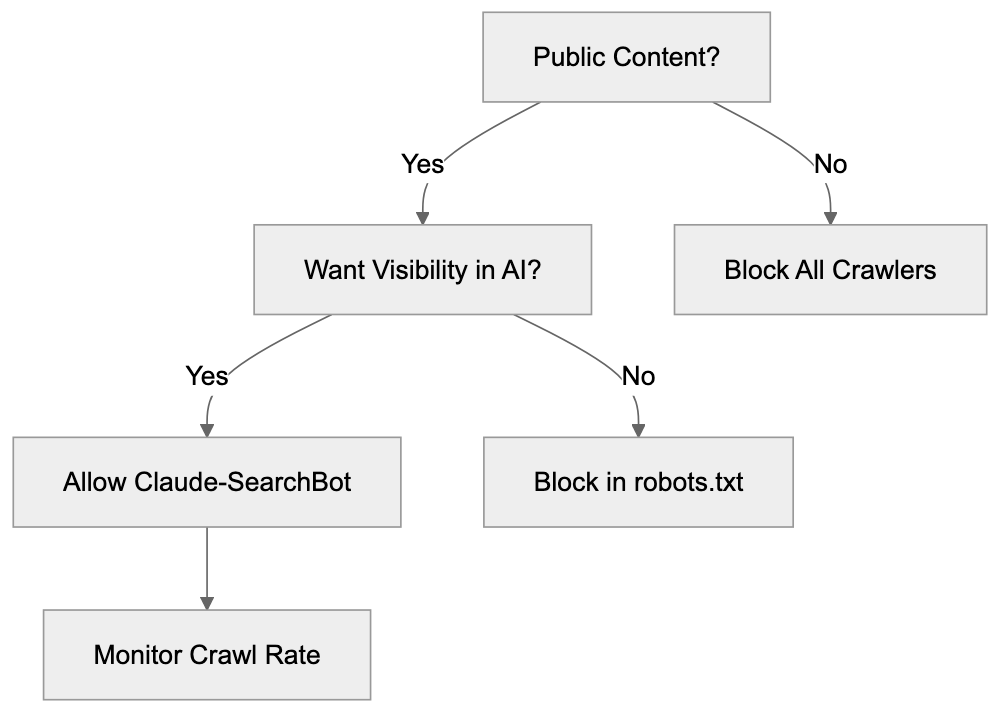
Claude-SearchBot is more specialized than some alternatives. While GPTBot from OpenAI primarily focuses on training data, Claude-SearchBot specifically targets search indexing. Google-Extended is similar in that it separates AI training from regular search crawling. Bingbot serves dual purposes for both traditional search and AI features, making it harder to block selectively. The crawl rate and behavior of these bots vary. Anthropic has stated that their bots respect rate limits and standard web protocols. Most major AI crawlers now provide clear user-agent identification after early criticism about transparency. Website owners increasingly use robots.txt to manage these bots individually based on their specific policies about AI usage.
Technical Details and Best Practices
Claude-SearchBot operates using standard HTTP requests to fetch web pages. The bot sends requests with the identifiable user-agent string and follows redirects appropriately. It processes robots.txt files before attempting to crawl any content from a domain. The crawler respects meta tags, including noindex and nofollow directives. To prevent indexing of specific pages without blocking the entire bot, use meta tags:
<meta name="robots" content="noindex, nofollow">This tells all crawlers, including Claude-SearchBot, not to index that specific page. The bot also respects the X-Robots-Tag HTTP header, which provides crawler directives at the server level. Monitoring your server logs helps you understand crawl frequency and patterns. Look for entries containing Claude-SearchBot/1.0 in the user-agent field. High crawl rates impacting server performance can be addressed by adjusting your robots.txt crawl-delay directive, though not all crawlers honor this consistently. For sites with changing content, ensuring proper caching headers helps crawlers understand content freshness. The bot likely prioritizes pages that change frequently over static content. Structured data markup using schema.org vocabulary may help the crawler better understand your content, though Anthropic has not specifically confirmed this.
Managing Multiple Anthropic Crawlers
Anthropic operates at least two distinct crawlers: Claude-SearchBot for search indexing and ClaudeBot for training data collection. This separation gives website owners granular control over how their content is used. You might want to allow search indexing (Claude-SearchBot) while blocking training data collection (ClaudeBot). This approach lets Claude reference your current content in responses without incorporating it into the base model training. Conversely, you might allow training data collection but block search indexing, though this is less common. The robots.txt file lets you set different rules for each bot independently. Consider your content strategy when making these decisions. News sites and public information resources often benefit from allowing search indexing for maximum visibility. Proprietary content, original research, or premium articles might warrant blocking training data collection. Educational content creators have different considerations than e-commerce sites. Some webmasters choose to allow all legitimate crawlers to increase discoverability, while others prefer strict control over AI systems accessing their content. There is no universal right answer; the choice depends on your specific situation and priorities.
Privacy and Data Collection Considerations
When Claude-SearchBot crawls your website, it collects the publicly available content you publish. This includes text, metadata, and potentially images depending on setup. The collected data goes into Anthropic’s search index for use in Claude’s information retrieval system. Unlike training data collection, search indexing typically means your content can be referenced or cited rather than incorporated into model weights. Website owners should understand this distinction. Content indexed for search remains attributable to your site, while training data becomes part of the model’s knowledge without specific attribution. If your site contains user-generated content, consider whether those users expect their public posts to be indexed by AI search systems. Terms of service and privacy policies should ideally address how public content might be crawled by various bots. For sites in regulated industries like healthcare or finance, verify that publicly accessible pages don’t inadvertently expose sensitive information to crawlers. The bot only accesses what’s publicly available without authentication, but misconfigurations can accidentally expose private content. Regular audits of your robots.txt file and crawler access logs help ensure your blocking preferences are correctly implemented. Remember, blocking crawlers doesn’t delete already-indexed content; it only prevents future crawling.
Summary
Claude-SearchBot is Anthropic’s search indexing crawler, separate from ClaudeBot (training data). It identifies itself as ClaudeBot (Search) and respects robots.txt. Allowing it increases your content’s visibility in Claude’s responses. Blocking it prevents search indexing while still allowing you to permit or block training data collection separately.
Frequently Asked Questions
What is the main function of Claude-SearchBot?
Claude-SearchBot serves the primary purpose of indexing web content to enhance the search capabilities of the Claude AI assistant. This allows Claude to provide users with up-to-date information beyond its original training data, aiding in real-time responses.
How can website owners manage their interactions with Claude-SearchBot?
Website owners can control whether Claude-SearchBot is allowed to crawl their sites using the robots.txt file. By specifying directives within this file, they can either allow or block the bot from indexing specific sections or the entire site.
What should I consider before allowing Claude-SearchBot to index my website?
Consider the potential benefits, such as increased visibility and traffic to your site, versus the risks of exposing content you may want to keep private. Websites with premium or sensitive content should evaluate the implications of allowing indexing more carefully.
Can I block Claude-SearchBot without affecting other crawlers?
Yes, website owners can specifically block Claude-SearchBot by configuring rules in their robots.txt file. This allows for targeted control, enabling management of this bot independently from others like ClaudeBot, which collects training data.
What type of content does Claude-SearchBot collect during its crawling?
Claude-SearchBot collects publicly available content, such as text and metadata, from websites. This information is then used to build Anthropic's search index and is designed to be referenced in Claude's answers rather than incorporated into AI model training.
How does Claude-SearchBot identify itself to webmasters?
The bot identifies itself using the user-agent string `ClaudeBot (Search)`. This clear identification helps webmasters recognize its activity in their server logs and analytics tools.
What are some best practices for managing multiple crawlers?
When managing multiple crawlers, utilize separate blocking rules in your robots.txt file for each bot based on their function. Evaluating the content strategy of your site can guide decisions about which crawlers to allow or block, ensuring compliance with your visibility goals.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.