Understanding Claude-Web: Anthropic's Real-Time Browsing Bot
Learn about Claude-Web by Anthropic, its real-time browsing capabilities, user-initiated actions, and key differences from ClaudeBot.
What is Claude-Web and Why It Matters
Claude-Web is a browsing tool developed by Anthropic, known as the Anthropic browsing bot, that enables real-time AI browsing for the Claude AI assistant. Unlike traditional web crawlers, this bot operates only when users specifically request information from the web. This allows Claude to fetch current information, read web pages, and provide up-to-date answers. Claude-Web is crucial because AI models have knowledge cutoff dates, but this bot bridges that gap by accessing live content.
This bot uses a specific user-agent string identified as “Claude-Web,” appearing in server logs. Anthropic’s Help Center provides guidance on managing bot access. Understanding this tool is essential for website owners and developers as it affects server traffic patterns. For businesses using Claude, real-time browsing expands the AI’s capabilities beyond its training data. TechCrunch discusses this feature in detail. The main difference from other bots is its user-initiated nature rather than automated crawling.
How Claude-Web Works and Its Purpose
Claude-Web Operation Model:
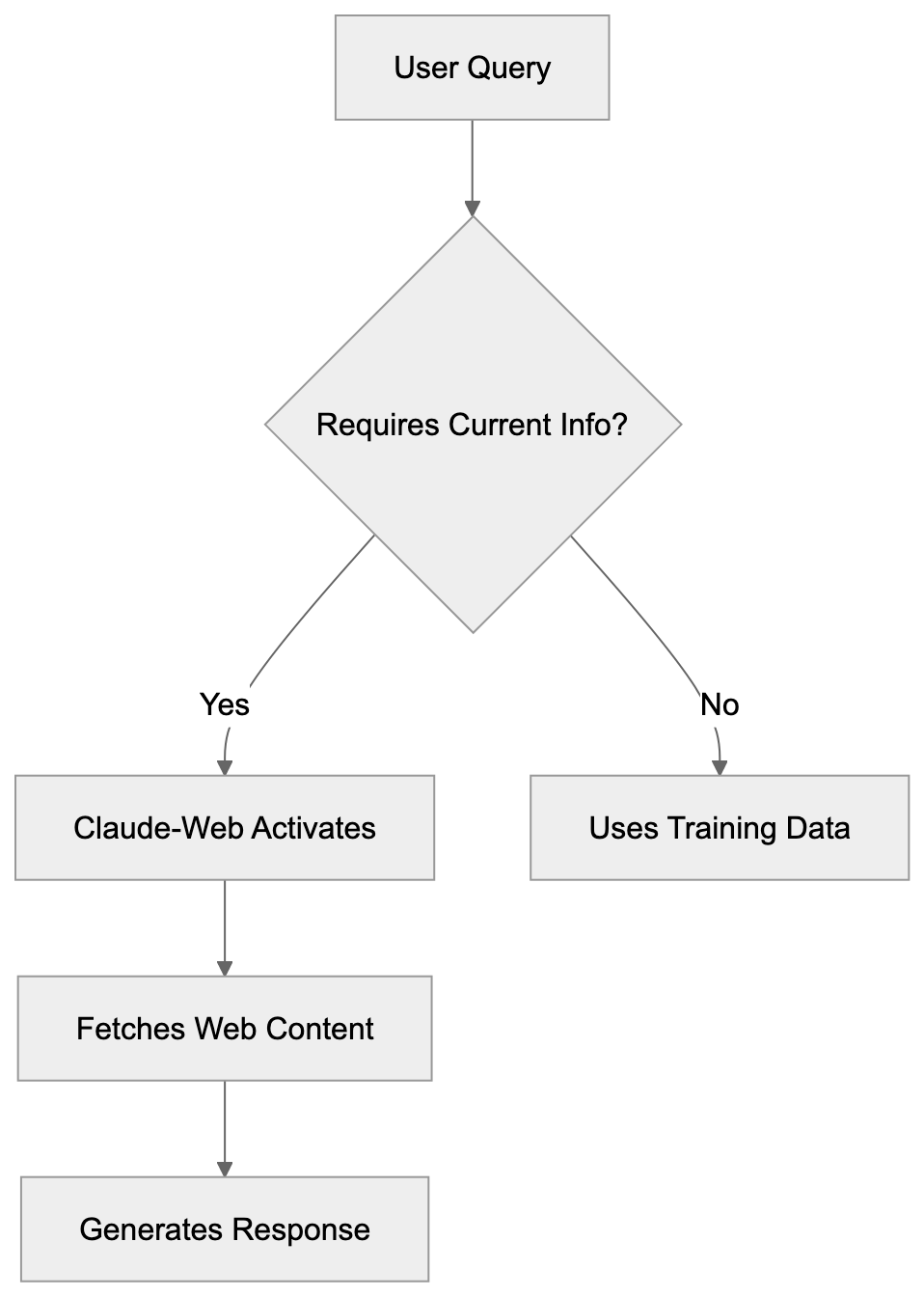
Claude-Web extends Claude AI’s knowledge beyond its training cutoff date. When a user asks Claude a question requiring current information, Claude can trigger a web browsing session. The Anthropic browsing bot then fetches relevant web pages, reads the content, and uses that information to formulate responses in real-time during the conversation.
Claude-Web does not publicly disclose a specific user-agent string for its tool, and there is no evidence confirming “Claude-Web/1.0.” Website administrators can identify these requests through their standard logging systems. The bot respects robots.txt files and standard web protocols. It sends HTTP requests similar to regular browsers but identifies itself clearly. The browsing occurs only when necessary for answering specific user queries, distinguishing it from background crawlers that systematically index websites. Thus, it operates on-demand rather than continuously scanning the internet.
User-Initiated Actions vs Automated Crawling
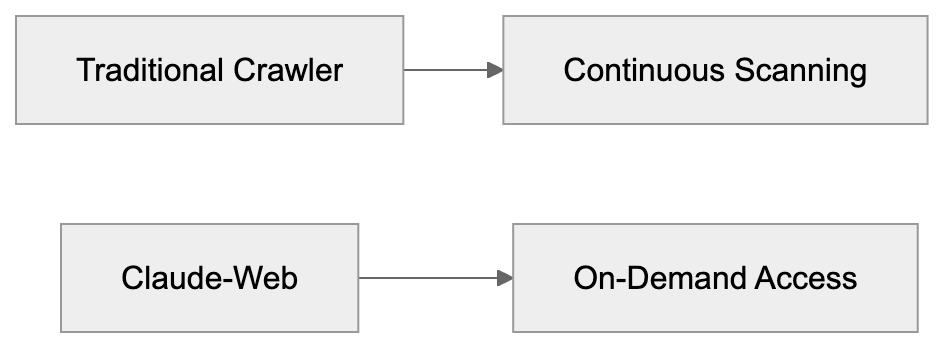
Claude-Web’s operation fundamentally differs from traditional web crawlers. Traditional crawlers like Googlebot or Bingbot continuously scan websites to build search indexes, operating 24/7 regardless of user activity. Claude-Web only activates when a Claude user asks a question requiring web access, meaning its traffic correlates directly with user queries.
Website owners won’t experience constant traffic from this bot. They’ll see sporadic requests linked to actual human exchanges with Claude. The volume of Claude-Web requests depends entirely on how many users ask Claude questions about that specific website. This creates a different traffic pattern in server logs. For developers, the bot’s behavior is less predictable than regular crawlers. You cannot schedule around it or expect consistent visit patterns. The user-initiated model means the bot visits pages users find relevant rather than systematically crawling entire sites.
Traditional Crawler vs User-Initiated Bot:
Technical Details and User-Agent String
The Claude user-agent identifies itself clearly in HTTP headers. No official documentation specifies the exact user-agent string as “Claude-Web/1.0,” and Anthropic has not publicly detailed it. Website administrators can search their access logs for this string to identify Claude-Web traffic.
The bot makes standard HTTP/HTTPS requests to web servers, processing HTML content similar to how browsers render pages. It can follow links within pages if necessary to answer user questions and respects standard HTTP status codes like 403 Forbidden or 404 Not Found. The bot also honors robots.txt directives if website owners want to block it.
Server-side blocking can be implemented using the user-agent string in configuration files. For Apache servers, this can be done in .htaccess files; Nginx servers can block it through server block configurations. The technical setup follows standard web protocols without requiring special handling. Response times from Claude-Web requests are typically similar to regular browser requests.
Blocking Claude-Web from Your Website
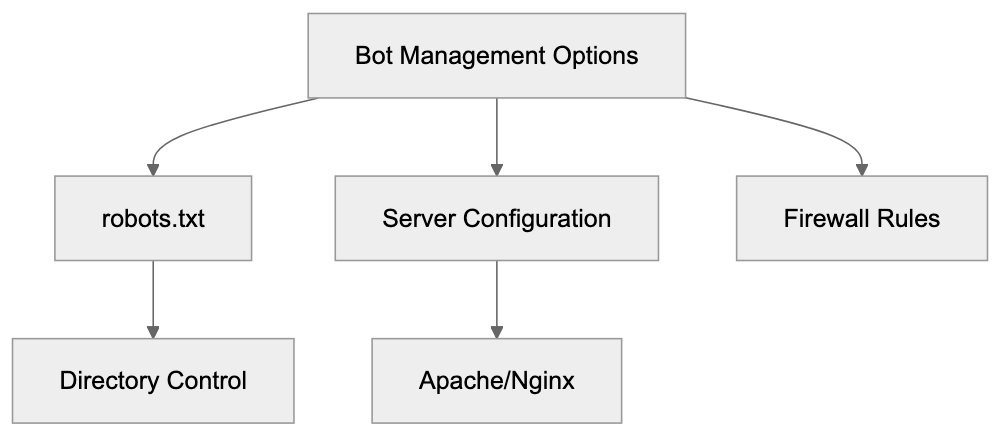
Website owners have multiple options to block Claude-Web if desired. CNET provides insights into managing bot access. The most common method is using the robots.txt file. However, website owners cannot reliably block via robots.txt using “Claude-Web” as no such user-agent is officially documented by Anthropic, indicating to the bot not to access certain parts of the site. For more granular control, specific directories can be blocked while allowing others.
Server-level blocking provides another option through configuration files. Apache users can add directives to block requests containing the Claude-Web user-agent string; Nginx configurations can return 403 errors for matching user-agents. Firewall rules can also block based on user-agent strings. Content delivery networks often provide bot management features to block specific user-agents.
The choice of blocking method depends on server setup and technical requirements. Note that blocking prevents Claude users from accessing your content through the AI assistant, potentially reducing content visibility among Claude users. Consider whether the reduced server load justifies the potential decrease in reach.
Claude-Web vs ClaudeBot: Key Differences
Claude-Web and ClaudeBot, both from Anthropic, serve different purposes. ClaudeBot is a traditional web crawler that systematically indexes websites for training data, operating continuously to build datasets for AI model training. Although Anthropic’s crawler employs “ClaudeBot,” there is no separate “Claude-Web” user-agent documented, indicating that web access integrates with Claude models.
ClaudeBot’s crawling pattern resembles other search engine bots, regularly visiting websites to find and index content. Claude-Web, however, activates only during active user sessions with Claude AI and does not build permanent indexes or datasets. Typically, the traffic volume from ClaudeBot is higher and more consistent, while Claude-Web traffic is sporadic and linked to specific user queries.
Website owners need to configure separate blocking rules for each bot. Blocking ClaudeBot prevents your content from being used in AI training, whereas blocking Claude-Web prevents real-time access during user conversations. While both bots respect robots.txt, they require different user-agent specifications. Understanding this distinction aids website administrators in making informed decisions about bot access.
Comparison with Alternative AI Browsing Bots
Several AI platforms now offer real-time AI browsing capabilities through specialized bots. Here’s how Claude-Web compares to similar tools:
| Bot Name | Company | Trigger Type | User-Agent | Primary Purpose |
|---|---|---|---|---|
| Claude web browsing | Anthropic | User-initiated | (Undisclosed) | Real-time answer enhancement |
| GPTBot | OpenAI | Automated crawling | GPTBot | Training data collection |
| ChatGPT-User | OpenAI | User-initiated | ChatGPT-User | Real-time browsing for answers |
| Bingbot | Microsoft | Automated crawling | Bingbot | Search indexing |
| PerplexityBot | Perplexity AI | User-initiated | PerplexityBot | Real-time search answers |
Claude-Web fits in the user-initiated category alongside ChatGPT-User and PerplexityBot. These bots activate only during active user sessions. In contrast, automated crawlers like GPTBot and Bingbot operate independently of user queries. User-initiated bots generally create less server load but more unpredictable traffic patterns.
Website owners concerned about AI training data should focus on blocking automated crawlers, whereas those concerned about real-time access should consider blocking user-initiated bots separately.
Use Cases for Businesses and Developers
Website Blocking Methods:
Businesses engage with Claude-Web in diverse ways depending on their roles. Companies using Claude as a productivity tool benefit from its real-time browsing feature, enabling employees to ask about current events, recent product releases, or updated documentation. This allows users to access information without leaving their Claude conversation.
Marketing teams can inquire about competitor websites or industry news, while developers can check current API documentation or framework updates, reducing context switching and improving workflow efficiency. On the contrary, website owners hosting content must consider Claude-Web’s impact.
E-commerce sites might notice Claude-Web requests when users compare products, and news websites could receive traffic from users seeking recent articles. Documentation sites may experience requests when developers ask Claude technical questions. SaaS companies should monitor if users are accessing their help centers through Claude. Deciding to allow or block Claude-Web depends on business goals and server capacity.
Privacy and Data Considerations
When Claude-Web accesses a website, it retrieves publicly available content just like a regular browser. The bot doesn’t bypass authentication or access private areas without credentials. If a page requires login, Claude-Web cannot access it unless the user provides the necessary information.
This protects password-protected content from unauthorized access, although publicly accessible pages can be read and processed by the bot. The content retrieved is used to answer the specific user query, governed by Anthropic’s privacy policy during interactions. Website owners should review content accessibility if privacy is a concern, ensuring sensitive information isn’t published on publicly accessible pages.
The bot respects standard security measures like HTTPS encryption. Server logs will show Claude-Web requests akin to other bot traffic, and website analytics tools can track these visits if configured to record bot traffic. For compliance purposes, organizations may need to assess whether allowing Claude-Web aligns with their data policies.
Impact on Server Resources and Performance
Claude-Web requests consume server resources similarly to regular browser requests, requiring processing power, bandwidth, and potentially database queries. Unlike automated crawlers that might overwhelm servers with rapid requests, Claude-Web traffic is limited by actual user queries, not sending thousands of requests per minute. Instead, requests arrive sporadically as different users interact with Claude.
Server load from Claude-Web is generally minimal for most websites. High-traffic sites with thousands of daily visitors likely won’t notice a significant impact. Smaller sites with limited server resources, however, might want to monitor Claude-Web traffic patterns. Server logs can help identify the frequency and volume of these requests.
If server performance degrades, administrators can implement rate limiting specific to the Claude-Web user-agent. Most modern web servers handle this bot traffic without special improvements, and content delivery networks and caching solutions work normally with Claude-Web requests. The bot respects standard HTTP caching headers to minimize redundant requests.
Future Developments and Trends
Real-time AI browsing represents a growing trend across the AI industry, with multiple companies now offering similar capabilities through their AI assistants. This pattern suggests Claude-Web will likely see further development and increased usage in the future.
Future versions might include more sophisticated browsing capabilities or improved performance. The user-agent string might evolve with version numbers indicating updates. Website owners should stay informed about changes to bot behavior and identification. The balance between AI accessibility and website control will continue to evolve.
Industry standards for AI bot management are still developing, and organizations like the Internet Engineering Task Force may eventually establish formal guidelines. Website administrators should regularly review their bot management policies. As more users adopt AI assistants, the volume of AI browsing bot traffic will likely increase, making understanding and managing these bots increasingly important for web developers and system administrators.
Conclusion
Claude-Web serves as Anthropic’s real-time browsing solution for the Claude AI assistant. Operating on a user-initiated basis, it activates only when users request current web information. Anthropic does not disclose a specific “Claude-Web/1.0” user-agent string for identification in server logs.
This aspect distinguishes it from ClaudeBot, which functions as a traditional web crawler for training data collection. Website owners can block Claude-Web through robots.txt files or server configurations, as it respects standard web protocols and security measures.
Compared to alternatives like ChatGPT-User and PerplexityBot, Claude-Web serves similar real-time information retrieval purposes. Businesses benefit from improved Claude capabilities, while website owners must balance accessibility with server resources. Understanding Claude-Web helps developers and administrators make informed decisions about bot access policies.
As AI browsing tools become more prevalent, managing these bots will become a standard part of web administration.
Frequently Asked Questions
What is the main difference between Claude-Web and traditional web crawlers?
Claude-Web operates on a user-initiated model, meaning it only activates when users ask specific questions that require web access. In contrast, traditional web crawlers continuously scan and index websites irrespective of user activity.
How can website owners block Claude-Web from accessing their sites?
Website owners can block Claude-Web using the `robots.txt` file or through server-level configurations. However, the exact user-agent string for Claude-Web isn’t formally documented, so implementing server-level blocking or firewall rules may be more effective.
Is the information retrieved by Claude-Web confidential?
No, Claude-Web only accesses publicly available content. It cannot access password-protected areas unless credentials are provided and does not bypass security measures like HTTPS encryption.
What impact does Claude-Web have on server performance?
Claude-Web requests typically consume server resources similar to regular browser requests. For high-traffic sites, the impact is generally minimal, but smaller sites should monitor their server load to assess the effect of these sporadic requests.
What should businesses consider when using Claude-Web?
Businesses should weigh the benefits of real-time browsing capabilities against the potential impact on server resources and content visibility. Balancing accessibility with performance, especially in resource-limited environments, is crucial.
What types of queries might trigger Claude-Web?
Claude-Web is activated by user queries that require current information, such as recent news articles, updates on competitors, or technical documentation. The bot fetches relevant content in real-time to respond accurately to these queries.
How does Claude-Web compare to other AI browsing bots?
Claude-Web is similar to user-initiated bots like ChatGPT-User, activating only during user sessions, unlike automated crawlers that operate independently. This results in sporadic traffic from Claude-Web compared to the more consistent requests from automated bots.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.