Understanding Cohere's AI Training Crawler: cohere-ai
Explore Cohere's AI training data crawler, cohere-ai. Learn about user-agent handling, blocking, and its role in AI training.
Introduction
Cohere AI is an enterprise-focused AI company that builds large language models for businesses. A key component in training these models is the cohere-ai web crawler. This AI training crawler collects text data from the internet to enhance Cohere AI’s systems. Large language models require vast amounts of AI training data to detect language patterns and generate useful responses, as discussed in Google’s guide on robots.txt files. The cohere-ai crawler visits websites, reads their content, and adds that data to Cohere AI’s training datasets, following the Robots Exclusion Protocol. Unlike consumer-facing AI tools, Cohere AI primarily caters to enterprise clients who need customized language models for their specific business needs. Understanding the functionality of cohere-ai is crucial for website owners wanting control over their content and for developers working with machine learning systems. The main features include standard user-agent identification, adherence to robots.txt protocols, and a focus on publicly accessible web content.
AI Crawler Data Collection Process:
What is the cohere-ai Crawler
The cohere-ai crawler is a bot that automatically visits websites to collect text content for training Cohere AI’s language models. It identifies itself through a specific user-agent string, often “cohere-ai,” in its HTTP requests. This user-agent allows website administrators to recognize and manage its access. While similar to web crawlers like Googlebot, cohere-ai serves a different purpose; instead of indexing pages for search results, it extracts text to teach AI models about language, context, and knowledge. The bot follows links and reads publicly available content without attempting to bypass paywalls or access password-protected areas. Website owners can spot cohere-ai visits in their server logs where the user-agent string appears. The crawler operates continuously to improve and update language models with fresh web data.
Why Cohere’s Crawler Exists and Its Purpose
Crawler Request Flow:

AI language models require enormous amounts of text data to function effectively. They learn by analyzing patterns in billions of words from diverse sources. Cohere AI developed the cohere-ai crawler to build high-quality training datasets for its enterprise clients. Companies deploy Cohere AI’s models for applications like customer service automation, content generation, and document analysis. More accurate AI responses are derived from better training data. The cohere-ai web crawler helps Cohere AI remain competitive by ensuring its models have comprehensive knowledge. The variety of web data offers insights into language usage, factual knowledge, writing styles, and domain-specific terminology. This variety is crucial in creating models that understand different industries and use cases, gathering contextual information on real-world language usage.
How Companies and Website Owners Interact with cohere-ai
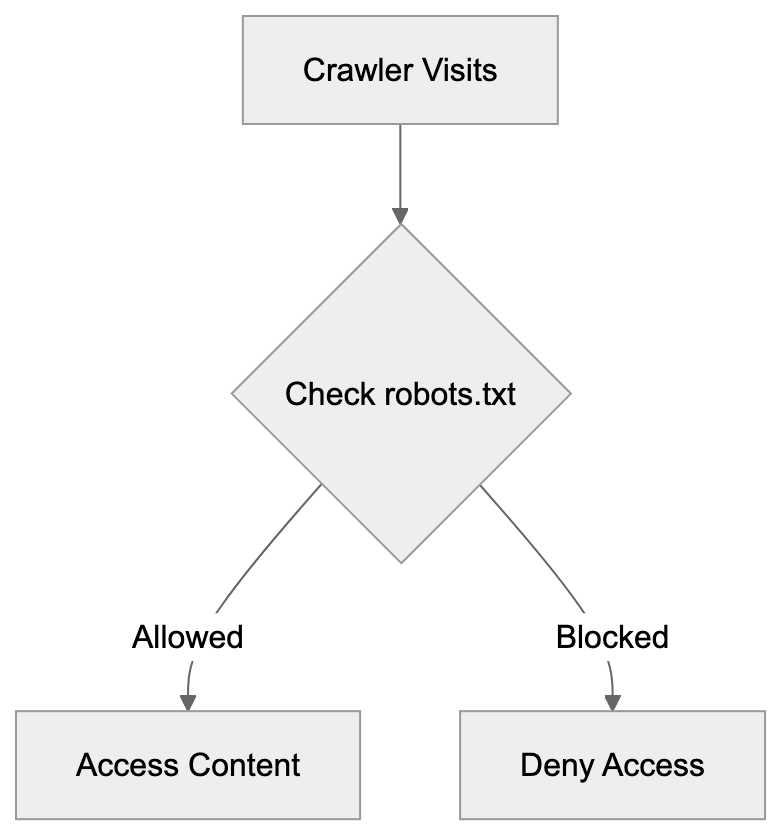
Website owners encounter the cohere-ai crawler through server logs and analytics tools. It appears as traffic with the cohere-ai user-agent string. Many site administrators face decisions about allowing or blocking this bot. Allowing the crawler contributes content to AI training data, which some view positively. Blocking it prevents Cohere AI from using the site’s content for model training. Companies using Cohere AI’s services benefit from data the crawler collects without building their own web crawler infrastructure. For those wishing to block cohere-ai, adding specific rules to their robots.txt file can achieve this. A disallow rule for the cohere-ai user-agent stops the crawler from site access. Decisions about allowing or blocking often align with content licensing terms and perspectives on AI training data collection.
Managing and Blocking the cohere-ai Crawler
To block cohere-ai from your website, modify your robots.txt file, which resides in your website’s root directory and directs crawlers on accessible pages. Use these lines to block the cohere-ai crawler:
User-agent: cohere-ai
Disallow: /This instruction denies cohere-ai access to any of your site’s pages. Adjusting the forward slash to particular directories targets specific sections. Many servers check robots.txt automatically when bots visit, requiring no extra configuration. Verify functionality by accessing yoursite.com/robots.txt in a browser—rules should display as plain text. Remember, robots.txt relies on voluntary compliance, and responsible crawlers like cohere-ai follow these rules. For stricter enforcement, some websites use server-level blocking based on user-agent strings, actively denying specified crawler requests before serving content. Websites often employ content delivery networks and web application firewalls for user-agent blocking. Post-blocking, it may take time for cohere-ai to cease visits as crawlers work through queues. Regular log checks confirm the blocking effectiveness.
Comparison with Other AI Training Crawlers
Managing Crawler Access with robots.txt:
Various AI companies operate web crawlers for data collection. Here’s a comparison of cohere-ai with other AI training crawlers:
| Crawler | Company | User-Agent | Primary Use | Enterprise Focus |
|---|---|---|---|---|
| cohere-ai | Cohere | cohere-ai | Training enterprise language models | Yes |
| GPTBot | OpenAI | GPTBot | Training ChatGPT and GPT models | Mixed |
| Google-Extended | Google-Extended | Training Gemini and AI products | No | |
| CCBot | Common Crawl | CCBot | Building public web archive datasets | No |
| anthropic-ai | Anthropic | anthropic-ai | Training Claude AI models | Yes |
| ClaudeBot | Anthropic | ClaudeBot | Training Claude AI models | Yes |
Cohere AI distinguishes itself with its exclusive enterprise approach, offering API access and custom models for businesses. Unlike common crawlers, Cohere AI focuses on data privacy and model customization for enterprise clients. In contrast, Common Crawl creates public datasets accessible to anyone. Meanwhile, OpenAI’s GPTBot serves both consumer products like ChatGPT and enterprise API customers. Google-Extended aids Google’s AI product development but focuses on search and advertising. Anthropic’s ClaudeBot and anthropic-ai support Claude models, competing directly with Cohere AI in enterprise markets. Each crawler adheres to robots.txt conventions and identifies itself clearly. Websites can block these crawlers using similar robots.txt methods. The primary difference lies in handling the collected data and the beneficiaries of the resulting AI models.
Cohere’s Data Practices and Enterprise Approach
Cohere AI positions itself as a responsible AI company with robust data governance. It ensures customer data submitted through its APIs remains private and segregated from public training models. This clear distinction is vital for enterprises handling sensitive information. The cohere-ai crawler collects publicly available web data separately from customer API usage. Cohere AI offers enterprise customers options to train custom models using their data while keeping this information isolated. This approach addresses concerns around data security and competitive advantage. Cohere AI serves sectors like financial services, healthcare, and legal, where data privacy regulations are strict. Its business model centers on selling API access and custom model development rather than advertising or consumer subscriptions, creating different incentives from companies monetizing through free consumer products. Cohere AI publicizes its commitment to ethical AI development and data collection transparency. Website owners can review Cohere AI’s policies to make informed decisions about allowing the crawler. Cohere AI’s enterprise focus demands high-quality training data while maintaining customer trust in data governance.
Technical Details About the Crawler’s Behavior
The cohere-ai crawler operates akin to other professional web crawlers in its technical execution. It sends standard HTTP requests and processes HTML responses while observing rate limiting to avoid server overload. This responsible behavior maintains website performance for regular visitors. The crawler focuses on text content, disregarding images, videos, or other media files, and extracts text from HTML documents after filtering out navigation elements, advertisements, and boilerplate content. It follows links to discover new content but respects nofollow attributes when specified by website owners. The system likely includes duplicate detection to avoid processing the same content multiple times from different URLs. Crawl frequency varies with the frequency of site updates and their importance to Cohere AI’s training needs. High-value sites with regular updates might experience more frequent visits. The crawler handles different encoding formats and languages to construct multilingual training datasets. It processes robots.txt files before attempting a crawl and meta robots tags in HTML headers influence behavior on individual pages. Website owners can use these tags to prevent specific page processing even where robots.txt allows access.
Impact on Website Performance and Resources
Web crawlers use server resources, including bandwidth, processing power, and database queries. Each request demands a response generation from the server, potentially slowing down smaller sites with limited resources during high crawl rates. The cohere-ai crawler minimizes this impact with rate limiting and respectful pattern following. While most modern sites handle crawler traffic smoothly, very small sites or those on shared hosting might experience effects. Website owners can monitor server logs to note cohere-ai’s visit frequency. If issues arise, blocking the crawler via robots.txt removes the resource usage. Some analytics tools include crawler visits in traffic statistics, possibly skewing data on human visitors. Filtering crawler user-agents from analytics ensures accurate visitor counts. Bandwidth consumed by crawlers matters for sites on metered hosting plans where data transfer incurs costs. Text content uses significantly less bandwidth than images or videos, limiting the impact of text-focused crawlers. Sites utilizing content delivery networks often handle crawler traffic more effectively through caching, eliminating repeated crawler requests to the origin server. For most websites, cohere-ai’s resource impact remains minimal compared to search engine crawlers, which crawl more frequently and extensively.
Legal and Ethical Considerations
The legality of web scraping for AI training is a developing legal area, with jurisdictions differing in regulations for automated data collection from websites. Generally, scraping publicly accessible data is legal, but commercial use might face restrictions. Copyright law adds complexity, as web content usually carries copyright protection. AI enterprises argue that model training on copyrighted content is fair use or equivalent, but content creators and publishers often dispute this, leading to ongoing legal challenges. Terms of service might prohibit scraping, but enforcement proves challenging. Ethically, there’s debate over whether AI companies should compensate content creators whose content trains profitable models. Some argue that publicly posting content implies acceptance of various uses, including AI training, while others assert AI training is a new use case creators didn’t foresee or consent to. Cohere AI’s enterprise focus profits from models trained on freely accessed web data, raising discussions on fair value distribution from AI systems. Responsible crawlers clearly identify themselves and respect robots.txt, providing website owners control over participation. This voluntary system requires active management. The ethical and legal landscape evolves as AI capabilities expand and the value of training data becomes clear.
Conclusion
The cohere-ai crawler is Cohere AI’s data collection tool for training enterprise-focused language models. Understanding its operation assists website owners in making informed decisions about blocking or allowing access. The crawler clearly identifies itself, respects robots.txt protocols, and focuses on publicly accessible web content. Cohere AI differentiates itself with its enterprise positioning and a strong emphasis on data privacy for API customers. Website owners can block the crawler effectively by adding simple rules to their robots.txt file. The broader context involves ongoing discussions regarding AI training data, copyright, and fair content creator compensation. As AI technology evolves, web crawlers will likely remain crucial for companies developing language models. Website administrators should stay informed on which crawlers access their sites and manage access based on their preferences and policies. The cohere-ai crawler signifies a part of the wider ecosystem where AI development intersects with web content creation and ownership rights.
Frequently Asked Questions
What is the main function of the cohere-ai crawler?
The cohere-ai crawler is designed to automatically visit websites and collect text data for training Cohere AI's language models. Unlike typical search engine crawlers that index for search results, it specifically extracts language-related content to enhance AI model performance.
How can I block the cohere-ai crawler from my website?
You can block the cohere-ai crawler by adding specific rules to your robots.txt file located in your website's root directory. Use the directives 'User-agent: cohere-ai' followed by 'Disallow: /' to prevent access to your entire site.
Will blocking the cohere-ai crawler impact data collected by Cohere AI?
Yes, if you block the cohere-ai crawler, it won't be able to access your website's content for its training datasets. This means that any public data you want accessed for AI training purposes will not be collected by Cohere AI.
How does the cohere-ai crawler ensure it doesn't overload my server?
The cohere-ai crawler employs rate limiting to manage its request frequency, minimizing the impact on server performance. It follows a responsible crawling pattern to maintain normal website functioning for human visitors while collecting necessary training data.
How do I know if the cohere-ai crawler is visiting my site?
You can identify visits from the cohere-ai crawler by checking your server logs for entries with the user-agent string 'cohere-ai.' This helps you monitor its traffic and assess your site's interaction with the crawler.
Is using robots.txt enough to control crawlers accessing my website?
While most responsible crawlers, including cohere-ai, respect robots.txt directives, this method relies on voluntary compliance. For stricter control, you may implement server-level blocking based on user-agent strings for more effective protection against unwanted crawler access.
What ethical concerns should I consider regarding data collection by crawlers?
Ethical concerns revolve around the fairness of using publicly posted content for AI training without compensating content creators. There are ongoing debates about the implications of perceived consent through publication and the potential need for compensation or acknowledgment of the original creators in future AI models.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.