Cohere Training Data Crawler for Bulk Data Collection
Learn about Cohere's specialized crawler for AI training data collection, how it differs from their chatbot, and how to manage it.
What Is Cohere and Why Training Data Matters
Cohere is an AI company that builds large language models for businesses and developers. They offer AI tools that aid in text generation, classification, and search, enabling businesses to deploy chatbots, search engines, copywriting, summarization, and other AI-driven products. For Cohere, massive amounts of text data are essential to train their models. This is where their Cohere training data crawler comes into play. The crawler automatically visits websites, conducting bulk data collection of text content. This collected data becomes part of the machine learning datasets that enhance Cohere’s AI models. Understanding how this training data crawler works is crucial for website owners and developers. It’s imperative to be aware of the data being collected from your site and how to control it, especially considering the legal implications of AI data collection. The web scraping AI operates separately from Cohere’s general AI bot services, which is important since they have different management requirements.
The Difference Between Cohere’s Crawler and Their AI Bot
Cohere’s Data Collection Approach:
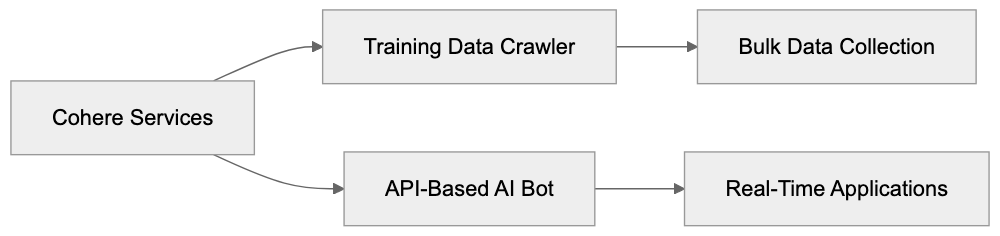
Cohere operates two different types of bots. Their training data crawler is focused on bulk data collection to train models. It visits websites systematically to gather extensive text content, storing it in datasets to train future AI models. The second type is their API-based AI service bot, powering real-time applications and chatbots integrated into business products. The Cohere bot identifies itself with a specific user agent string in its requests. Website owners can block it using robots.txt files or other controls. In contrast, the API bot processes queries in real-time through Cohere’s API endpoints. When you use a website with integrated Cohere AI, that’s the API bot functioning. Meanwhile, the training crawler runs in the background, gathering data without direct interaction. This distinction is often overlooked.
How Cohere Collects Training Data
Cohere’s Two Bot Types:
Cohere’s training data crawler functions like other AI crawlers but with a unique focus. It dispatches HTTP requests to websites, downloading publicly accessible content. The crawler follows links page by page, akin to how search engines index the web, but with a different goal. Rather than creating a search index, it builds machine learning datasets. The crawler targets text content to train language models, including articles, blog posts, documentation, forums, and other text-heavy pages. Typically, the crawler respects robots.txt files, allowing website owners to block it. The user agent string in server logs helps identify the crawler. Administrators can monitor logs to see if the crawler has visited. The collected data undergoes processing and cleaning before use in training, removing duplicates and filtering low-quality text. The scale of the operation is massive, as training modern AI models requires billions of words.
Why Companies Build These Crawlers
AI companies build AI crawlers for a straightforward reason: large language models need vast amounts of text to learn language patterns. Manual data collection is insufficient for the task; hence, automated crawlers gather data at scale. The alternatives—creating training data from scratch or licensing it—are costly and time-consuming. Web crawling provides diverse, real-world text spanning various topics and styles, enhancing the versatility of AI models. Without crawlers, AI companies would face significant challenges in remaining competitive. The quality and quantity of AI data collection impact model performance. Companies like Cohere, OpenAI, Anthropic, and Google use some form of web crawling, standardizing the practice in the industry. However, it raises questions about copyright, consent, and data ownership.
Managing Cohere’s Crawler on Your Website
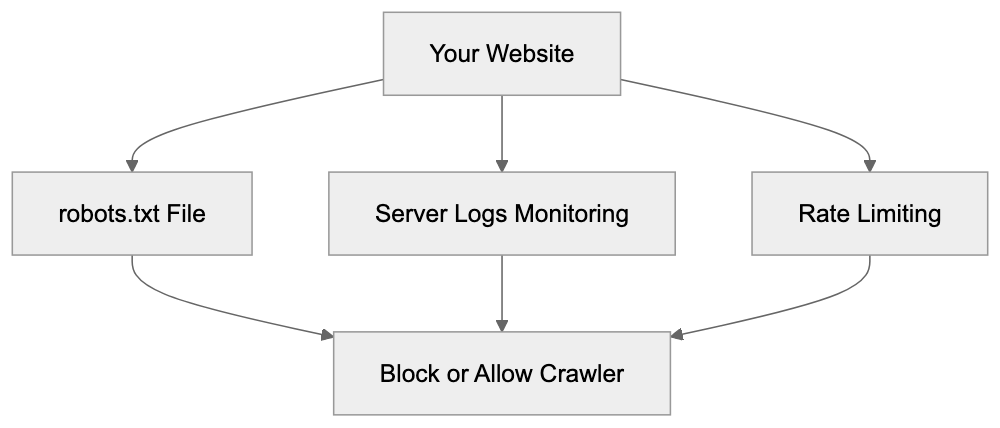
Website owners have several options to control Cohere’s training data crawler. The most common method is updating your robots.txt file, informing crawlers which parts of your site they can access. To block Cohere’s crawler, add specific directives to robots.txt, verifying the exact user agent string from official documentation. Once known, you can disallow it entirely or block specific directories. Another option is monitoring your server logs for crawler activity, helping you track content access frequency. Some owners use rate limiting to manage how fast crawlers access their sites, preventing excessive server load. Meta tags like noindex and nofollow can prevent crawling of individual pages. Remember, these are requests, not enforceable blocks, but major companies like Cohere generally respect these files.
Comparing AI Training Data Crawlers
Cohere isn’t alone in running AI crawlers. Multiple companies operate similar systems. Here’s how they compare:
| Company | Crawler Name | Primary Purpose | Respects Robots.txt | Opt-out Available |
|---|---|---|---|---|
| Cohere | cohere-crawl | Training data collection | Yes | Via robots.txt |
| OpenAI | GPTBot | Training data collection | Yes | Via robots.txt |
| Anthropic | anthropic-ai | Training data collection | Yes | Via robots.txt |
| Google-Extended | AI training (separate) | Yes | Via robots.txt | |
| Common Crawl | CCBot | Public dataset creation | Yes | Via robots.txt |
Website Owner Control Options:
Each crawler has distinct characteristics and collection patterns. Common Crawl creates public datasets used by many AI companies, so blocking it might prevent multiple AI companies from accessing your content. Google-Extended is separate from Google’s search crawler, allowing search indexing while blocking AI training. Opt-out availability indicates recognition of website owner concerns, although smaller AI companies might not offer clear options. Website owners should stay informed about active crawlers, as the AI industry evolves swiftly.
Technical Details About Crawler Identification
Identifying Cohere’s crawler in your server logs requires specific knowledge. The crawler sends a user agent string with each request, identifying the bot and often including contact information. It usually contains the company name and a documentation link. Administrators can search access logs for this string, and log analysis tools filter requests by user agent to reveal crawler activity. Crawler IP addresses may follow patterns, and some companies publish these IP ranges, aiding in distinguishing legitimate crawlers. Training data crawlers typically operate at moderate speeds to avoid server overload. Extremely fast requests may indicate different bots. Pages accessed by the crawler focus on text-rich content, not images or scripts, aiding in decision-making about crawler access.
Privacy and Data Usage Considerations
When Cohere’s crawler collects data from your website, it’s incorporated into their training datasets, raising data usage and privacy concerns. Publicly accessible content is usually considered fair game for crawling, but using it for commercial AI training is a legal gray area. Countries have varying laws about web scraping and data usage. Website owners may have terms prohibiting certain uses of their content, which may not stop crawlers but present potential legal objections. Collected data might include personal information from public pages, raising privacy concerns. AI companies often argue that training on public data falls under fair use or similar doctrines. Content creators disagree, leading some sites to include AI training terms in their policies. Others use technical measures to block crawlers. The debate continues as AI companies and content creators seek a balance.
Best Practices for Website Owners
Website owners should actively manage AI crawlers. Start by updating your robots.txt file with directives for AI crawlers you wish to block. Validate your file using tools to ensure proper functionality. Document your decision on crawler access policies for stakeholder clarity. Regularly monitor server logs for actual crawler visits, as compliance varies. Consider the trade-offs between blocking crawlers and visibility in AI-powered tools. Blocking all crawlers might reduce your visibility in AI results; selectively allow beneficial crawlers. Stay informed about new crawlers and follow industry updates. Review your content strategy concerning AI training practices; consider formats that limit access. Include clear terms of service regarding data usage, offering documented intentions despite crawler ignorance. Balance content protection with web visibility benefits.
The Future of AI Training Data Collection
The landscape of AI training data collection continues to evolve. More AI companies are emerging, each potentially deploying crawlers. Regulatory pressure is increasing, with jurisdictions like the EU developing laws that impact data collection, potentially requiring explicit consent for AI training use. AI companies are also exploring alternative data sources, such as synthetic data generation and licensed content partnerships. However, web crawling remains crucial. The technical arms race between content protection and data collection persists, with new blocking methods and sophisticated crawlers. Website owners must engage with these developments. Content creator and AI company relationships are still defining themselves. Court cases and legislation will shape the future of data collection. Informing yourself helps make better decisions and adapt to the AI era.
Conclusion
Cohere’s training data crawler reflects standard AI industry practices, collecting bulk text data to train language models, separate from their API-based services. Website owners can manage it through robots.txt files and technical measures. Understanding the distinction between different AI bots aids effective management. Similar crawlers from multiple companies offer independent control options, raising questions about web content use. Website owners should decide whether to allow AI crawlers, balancing content protection and AI-powered tool visibility. Regular monitoring and updates to policies maintain control. As the industry evolves, staying informed becomes increasingly vital for online publishers.
Frequently Asked Questions
How can I prevent Cohere's crawler from accessing my website?
You can prevent Cohere's crawler from accessing your site by updating your robots.txt file. Include specific directives that disallow the user agent associated with Cohere's crawler. This is a common method used by website owners to manage crawler access.
What should I do if I notice Cohere's crawler in my server logs?
If you find Cohere's crawler in your server logs and are concerned about its access, you should verify if your robots.txt file is correctly set up to block it. Regularly monitoring logs allows you to assess how frequently the crawler is visiting your site, and you can adjust your policies as needed.
Are there legal implications if my website content is crawled by AI bots?
Yes, there may be legal implications regarding copyright and content use when crawlers collect publicly available data. Different jurisdictions have varying laws on web scraping, and you may want to consult legal counsel if you have concerns about data usage or copyright issues related to AI training.
How does Cohere's crawler differ from other AI bots?
Cohere's crawler is specifically designed for bulk data collection to train language models, whereas their API-based AI bot provides real-time services for applications like chatbots. The crawler collects data passively in the background, while the API bot interacts directly with users.
What are the best practices for managing AI crawlers on my website?
Best practices include updating your robots.txt file to control access, monitoring server logs to track crawler activity, and considering the balance between blocking crawlers and maintaining visibility in AI-powered tools. Regularly reviewing your policies and staying informed about new developments in the AI industry is also advisable.
Can I allow certain crawlers while blocking others?
Yes, you can selectively allow certain crawlers while blocking others by configuring your robots.txt file. This allows you to maintain visibility for beneficial crawlers like search engines while restricting access to AI crawlers you do not wish to allow.
What might happen if I completely block all AI crawlers?
Blocking all AI crawlers may reduce your site's visibility in AI-driven applications and tools, potentially missing out on benefits like increased engagement. It's important to consider the trade-offs and decide what level of accessibility best suits your goals as a website owner.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.