Maximizing Data Extraction with Diffbot: Complete Guide
Learn about Diffbot's structured data extraction, AI features, Knowledge Graph, and applications for businesses needing web scraping solutions.
What is Diffbot and Why Data Extraction Matters
Diffbot is an automated data extraction service that transforms unstructured web content into structured data. This AI-powered web scraping service reads and understands web pages similarly to humans. For businesses needing to gather extensive web data, Diffbot offers web scraping API and crawling services to extract information without manual coding for each site.
Data extraction bots like Diffbot exist to process massive amounts of web information rapidly. Marketing professionals use these tools to monitor competitor pricing while SEO experts gather content ideas from thousands of pages. Software developers integrate structured data into their apps. Without such tools, teams would manually copy and paste data—a non-scalable, impractical solution. Diffbot automates this using computer vision and natural language processing to identify and extract specific data fields from web pages.
How Diffbot Works as a Web Scraping Solution
Diffbot Data Extraction Process:
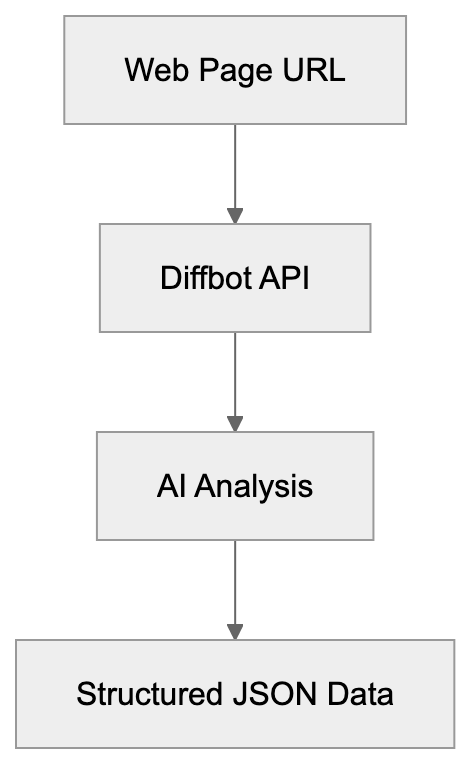
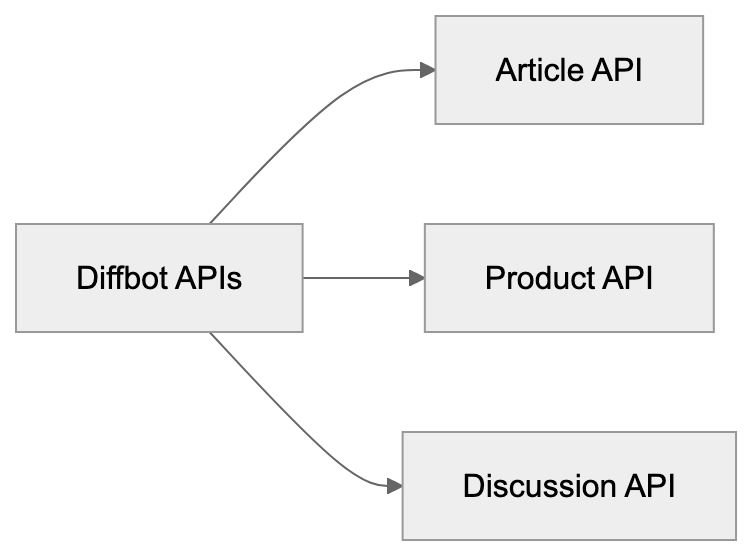
Diffbot offers several API endpoints targeting various web content types. The Article API extracts text, images, authors, and publication dates from news articles and blogs. The Product API retrieves product names, prices, descriptions, and availability from eCommerce sites. The Discussion API captures comments, forums, and reviews, analyzing the visual layout and HTML structure to identify data fields.
The technology utilizes machine learning models trained on billions of web pages. Sending a URL to a Diffbot API involves rendering the page, analyzing its structure, and returning JSON formatted data. This method contrasts traditional web scraping where developers write custom code for each site. Diffbot’s models generalize across sites, enabling one API call to work on most similar pages without site-specific customization.
Web developers can integrate Diffbot using REST API calls. You send an HTTP request with the target URL and your API token. The response provides extracted fields as structured data, with rate limits and pricing based on subscription tiers. Diffbot’s service handles JavaScript rendering, making it effective for extracting data from dynamic single-page applications that pose challenges for traditional scrapers.
Diffbot Knowledge Graph Explained
Diffbot API Types:
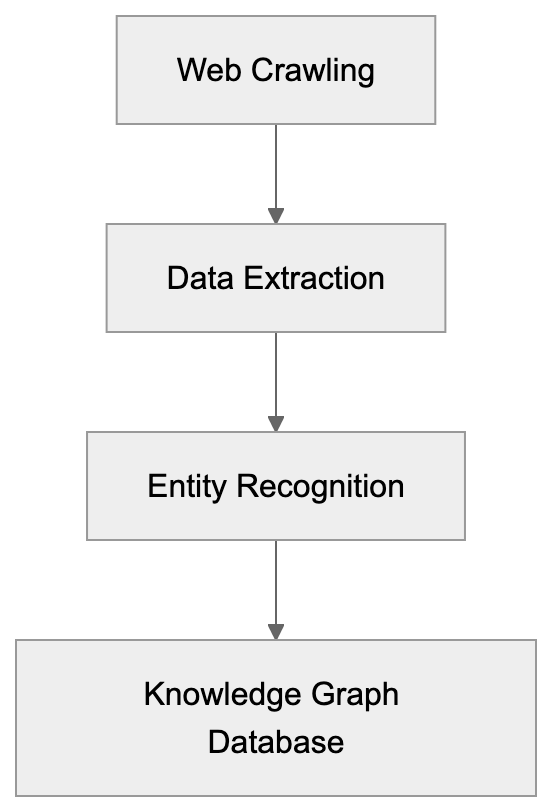
The Diffbot Knowledge Graph is a vast database of structured information about entities like organizations, people, products, and locations. Continuously crawling the web, Diffbot builds this graph by extracting data through its APIs. Containing billions of entities and their relationships, companies use it for market research, lead generation, and competitive intelligence.
Access to the Knowledge Graph occurs via a separate API and query language, allowing searches for companies in specific industries, people with certain job titles, or product catalogs across the web. The data is regularly updated as Diffbot recrawls sources, differing from static datasets that quickly become outdated.
Small business owners might use the Knowledge Graph to find potential customers or partners, while marketing professionals could identify companies recently launching products in a category. Content marketers find trending topics and related entities for content planning. The graph structure reveals connections, such as which executives work where or which products belong to which brands.
Diffbot User Agent and Bot Blocking
Diffbot identifies itself with specific user agent strings while crawling websites. The most common user agent is “Diffbot/2.0,” though variations exist for different services. Website owners can spot Diffbot traffic in server logs by looking for these strings. Some sites block Diffbot’s data extraction, while others allow it to increase content visibility in data applications.
To block Diffbot, add rules to your robots.txt file. Block user agent strings like “Diffbot” and “DiffbotCrawler.” Alternatively, configure your web server or firewall to reject requests from Diffbot’s IP ranges. The company provides documentation for website administrators wanting to manage access.
Blocking involves tradeoffs. If your business wants products or content discoverable through data services using Diffbot, blocking limits exposure. eCommerce sites often permit price comparison bots as they drive traffic, whereas news publishers may block them to protect exclusive content. The decision depends on your API business model and data sharing preferences.
Knowledge Graph Structure:
Diffbot API Business Model and Pricing Structure
Diffbot operates on a subscription and API call pricing model. Free trials typically offer a limited number of API calls for testing. Paid plans scale based on monthly requests and accessed APIs. The Knowledge Graph requires separate licensing, with custom pricing for enterprise needs.
The business model focuses on serving companies needing data at scale. While individual developers can use the APIs for small projects, larger data companies and enterprises form the core customer base. They might process millions of pages monthly for price monitoring, content aggregation, or market intelligence platforms.
Revenue comes from API subscriptions and Knowledge Graph access fees. Diffbot also offers custom crawling services to build dedicated datasets for specific clients, differing from one-time data purchases. The recurring revenue model aligns with ongoing data needs as web content constantly evolves, requiring fresh extraction.
Comparing Diffbot to Alternative Data Extraction Tools
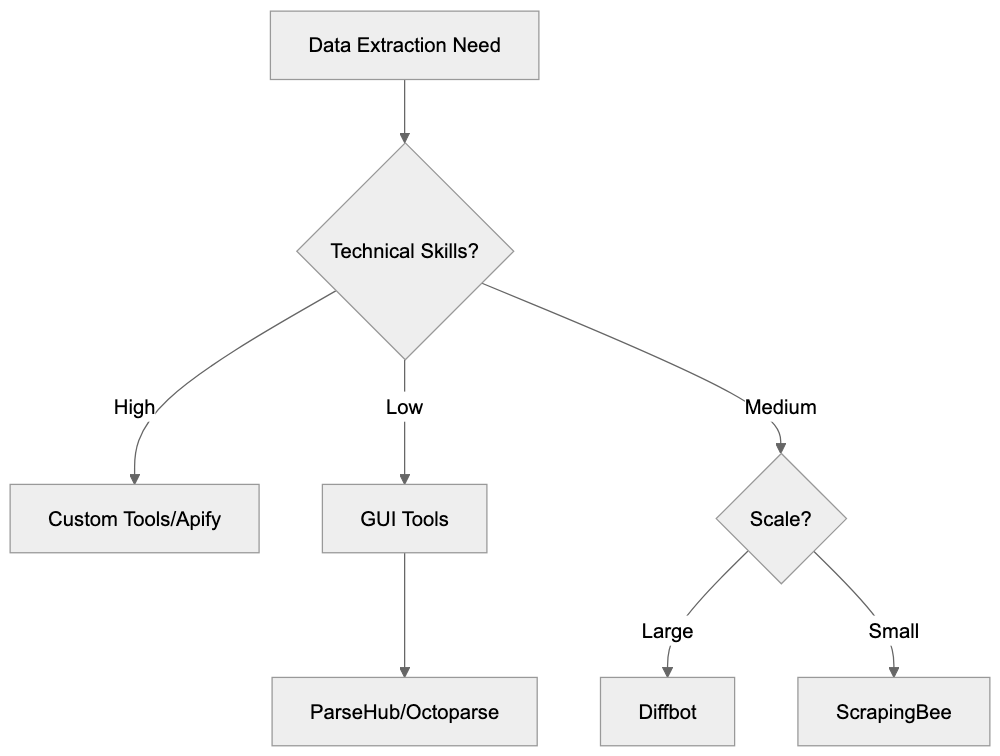
Various companies offer web scraping and data extraction services, each with strengths suited to different use cases and technical needs. Here’s a comparison of Diffbot and major alternatives.
| Tool | Approach | Best For | Key Difference |
|---|---|---|---|
| Diffbot | AI-powered visual extraction | General-purpose extraction across site types | Pre-trained models work without custom coding |
| ParseHub | Visual scraper with point-and-click | GUI-based setup | Desktop application with visual selector |
| Octoparse | Template-based extraction | Non-technical users needing common sites | Pre-built templates for popular websites |
| Apify | Custom scraper marketplace | Developers wanting ready-made scrapers | Community marketplace of pre-built scrapers |
| ScrapingBee | Headless browser API | Sites with heavy JavaScript | Focused on browser automation and proxies |
Diffbot excels at working across many sites without configuration. ParseHub requires teaching what to extract through its interface. Octoparse suits sites with existing templates. Apify offers flexibility through code but requires finding or building the right scraper. ScrapingBee handles JavaScript-heavy sites, but users must write extraction logic.
For structured data extraction at scale, Diffbot’s pre-trained models save development time, while custom scraper tools suit one-off projects or sites with unique structures. The Knowledge Graph is unique to Diffbot and unavailable with these alternatives.
Real World Applications for Businesses
Data companies use Diffbot to build products requiring current web data. A price comparison website might use the Product API to monitor prices across eCommerce sites without custom code for each retailer. Diffbot’s models adapt to layout changes without breaking code.
Marketing professionals use Diffbot for competitive analysis, monitoring competitor blog posts, content strategies, and trending topics. The Article API extracts publication dates and authors, aiding content team activity analysis. Some combine this with the Knowledge Graph to map industry relationships and identify influencers.
SEO experts use Diffbot for content research and link analysis. Extracting structured data from search results and web pages helps identify content gaps and opportunities. The ability to process large volumes of pages allows comprehensive competitive analysis. You can see topics competitors cover, content structure, and their emphasized products or services.
Small businesses with limited technical resources benefit from the API’s simplicity. Instead of hiring developers to build custom scrapers, a few API calls can enable data-driven features in your application. For instance, a local business directory could use Diffbot to automatically gather business information from company websites instead of manual data entry.
Technical Integration Considerations
Integrating Diffbot requires an API key obtained upon signing up. Authentication uses a token parameter in your API requests. Most programming languages feature HTTP libraries compatible with Diffbot’s REST API, returning JSON responses easy to parse and integrate into databases or applications.
Rate limits depend on your subscription tier, with overages leading to throttling or extra charges. Production applications need retry logic and error handling, as web scraping faces various issues. Websites might be temporarily down, block requests, or change structure, affecting extraction quality.
Data quality varies with website structure and content type. Diffbot excels on standard content types like articles, products, and discussions. Customized page layouts or unusual content structures might yield incomplete results. Testing on specific target sites before committing to production use is advised. APIs include confidence scores indicating extraction quality.
Privacy and Data Usage Policies
Web Scraping Tool Decision Flow:
When using Diffbot or similar data extraction tools, understand what happens to the URLs and data submitted. Diffbot processes submitted URLs through their APIs, with extracted content passing through their systems. Review their privacy policy and terms of service to understand data retention and usage practices.
For businesses extracting personal data, consider privacy regulations like GDPR or CCPA. Publicly available data on websites does not guarantee legal use. Marketing databases built from web scraping need compliance processes for data subject rights like deletion and access requests.
Some websites prohibit automated data collection in their terms of service. While robots.txt provides technical guidance, legal terms create binding agreements when using a site. Consult legal counsel if building commercial products relying on extracted web data. Web scraping legality varies by jurisdiction and use case.
End and Key Takeaways
Diffbot offers AI-powered data extraction through APIs converting web pages into structured data across many site types without custom coding. Key offerings include extraction APIs for articles, products, and discussions, plus the Knowledge Graph database of entities and relationships.
Businesses use Diffbot for price monitoring, competitive intelligence, content research, and data product creation. The API business model charges based on usage volume. Compared to alternatives, Diffbot’s strength lies in pre-trained models generalizing across websites. Website owners can block Diffbot through robots.txt and server configurations.
For developers and businesses needing web data at scale, Diffbot reduces engineering efforts compared to building custom scrapers. The tradeoff is less extraction logic control and dependence on their service. Understanding user agent strings, pricing structure, and requirements helps decide if Diffbot fits your data extraction needs.
Frequently Asked Questions
What types of data can I extract using Diffbot?
Diffbot offers several APIs tailored for extracting specific types of data, including articles, products, and discussions. For example, the Article API extracts text, images, authors, and publication dates, while the Product API retrieves product details like names and prices from eCommerce sites.
How does Diffbot handle websites with dynamic content?
Diffbot is equipped to handle dynamic single-page applications by rendering JavaScript content. This capability allows it to extract data even from visually heavy websites that traditional scrapers might struggle with.
What is the process for integrating Diffbot into my application?
To integrate Diffbot, you must sign up for an API key and use it in your HTTP requests to the Diffbot API. The API operates using REST principles and returns JSON responses, which can be easily parsed and used within your application.
Can I use Diffbot for real-time data extraction?
Yes, Diffbot is designed for real-time data extraction, allowing businesses to monitor changes across websites as they happen. However, keep in mind the rate limits based on your subscription plan, which may affect how frequently you can pull data.
How does Diffbot maintain the accuracy of extracted data?
Diffbot uses machine learning models that are continually trained on billions of web pages to improve the accuracy of data extraction. It also provides confidence scores with its responses to help users gauge the reliability of the extracted information.
What are the legal considerations when using Diffbot?
When using Diffbot, it's crucial to comply with privacy regulations such as GDPR or CCPA, especially if personal data is involved. Additionally, be aware of the terms of service of websites from which you are extracting data, as some may prohibit automated data collection.
Is there a trial version of Diffbot available?
Diffbot offers free trials with a limited number of API calls, allowing users to test its functionality before committing to a paid plan. This is beneficial for evaluating how well the service meets your data extraction needs.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.