Google-CloudVertexBot: A Vertex AI Crawler Guide
Learn about Google-CloudVertexBot features, purposes, blocking methods, and Vertex AI Search integration for developers and businesses.
What is Google-CloudVertexBot
Google-CloudVertexBot is a web crawler operated by Google Cloud that collects web content specifically for Vertex AI services, enabling enterprises to build custom search experiences with AI enhancements. This bot crawls websites to gather data that powers Google’s enterprise AI platform known as Vertex AI. It identifies itself using a user-agent token when visiting websites. Website owners can manage access through standard web protocols like robots.txt files. The primary purpose is to enable grounding for Vertex AI applications with fresh web content. Grounding connects AI models to real-time web information, enhancing the accuracy and currency of AI responses. The bot is distinct from Google-Extended, which focuses on data collection for model training. Understanding this crawler is essential for developers building AI applications and website owners managing content access policies.
Why Google-CloudVertexBot Exists
Vertex AI is Google’s enterprise machine learning platform offering tools for building, deploying, and scaling AI models. Vertex AI Search, a feature of the platform, allows businesses to create AI-powered custom search experiences. To maintain relevant and current search results, the system requires web content access, facilitated by Google-CloudVertexBot. This bot continuously crawls websites to index content for Vertex AI Search applications. Without the crawler, Vertex AI Search would rely solely on content manually uploaded by users. The bot enables grounding with web content, allowing AI applications built on Vertex AI to provide factual and updated responses. This reduces hallucinations, benefiting enterprise customers with access to up-to-date web information. While Google-Extended collects data for model training, Google-CloudVertexBot serves a functional role in live applications.
How Businesses Use Google-CloudVertexBot
Businesses using Vertex AI leverage content crawled by Google-CloudVertexBot. A retail company, for instance, could create a customer service chatbot using Vertex AI Search that answers product questions by referencing crawled web content. A healthcare company might build an internal search tool that retrieves medical information from approved websites, with the crawler indexing such sites for relevant results. Marketing teams analyze web content trends aided by the crawler’s raw data. Software developers integrate Vertex AI Search into their applications, sourcing search results from crawled and indexed content. Website owners allowing the bot contribute to the Vertex AI ecosystem, making their content searchable through platform-built applications. Google Cloud customers configure which websites their Vertex AI applications should reference, and the bot crawls those sites on a schedule to keep the index updated. This setup differs from general web search, serving specific enterprise applications instead.
Vertex AI Content Flow:
Technical Details and User-Agent Token
Google-CloudVertexBot identifies itself with a specific user-agent string when requesting web pages. The user-agent token is formatted as:
Google-CloudVertexBot/1.0 (+https://cloud.google.com/vertex-ai/docs/generative-ai/learn/overview)
This token appears in server logs when the bot visits a website, adhering to standard web crawler conventions. Google might update the version number as the bot evolves. The URL in parentheses links to Vertex AI documentation. Website administrators can examine server logs for this user-agent to determine if the bot is crawling their site. The bot respects standard crawl delay directives and robots.txt rules, operating separately from Googlebot, which handles typical search indexing. This distinction is crucial because blocking one doesn’t block the other. The bot uses HTTPS when available and follows redirects like a typical browser. Crawl frequency depends on content changes and Vertex AI applications referencing the site. Although Google hasn’t disclosed exact crawl rate limits, the bot behaves similarly to other enterprise crawlers. Understanding the user-agent aids in access control and log analysis.
Relationship to Google-Extended
Google-Extended is another token used by Google for AI training data collection, controlling content use for training models. Google-CloudVertexBot and Google-Extended serve different purposes. Blocking Google-Extended prevents your content from training model data collection, while blocking Google-CloudVertexBot stops indexing for Vertex AI Search applications. They operate independently, allowing websites to block one and permit the other. Introduced in 2023 as an AI training opt-out mechanism, Google-Extended focuses on training future models with historical data, whereas Google-CloudVertexBot focuses on indexing current content for active applications. Both respect robots.txt directives, and website owners concerned about AI training should block Google-Extended. Those wary of their content in Vertex AI Search results should block Google-CloudVertexBot. Google provides distinct controls for each token in robots.txt files.
Google AI Crawler Comparison:
How to Block Google-CloudVertexBot
Website owners can block Google-CloudVertexBot through their robots.txt file placed in the root directory. Add these lines to block the bot completely:
User-agent: Google-CloudVertexBot
Disallow: /To block specific sections while allowing others:
User-agent: Google-CloudVertexBot
Disallow: /private/
Disallow: /internal/This blocks only the private and internal directories. The bot typically respects these rules within 24 hours. Check server logs to confirm the bot stops visiting after updating robots.txt. Some content management systems offer built-in tools for managing robots.txt rules, and WordPress plugins can handle this without manual file editing. Test the robots.txt file using validation tools to ensure the rules function correctly. Blocking the bot means content won’t appear in Vertex AI Search results used by enterprise applications, which might be desirable for proprietary content or internal documentation. Remember, blocking occurs at the crawler level, not the AI model level.
Vertex AI Search Integration
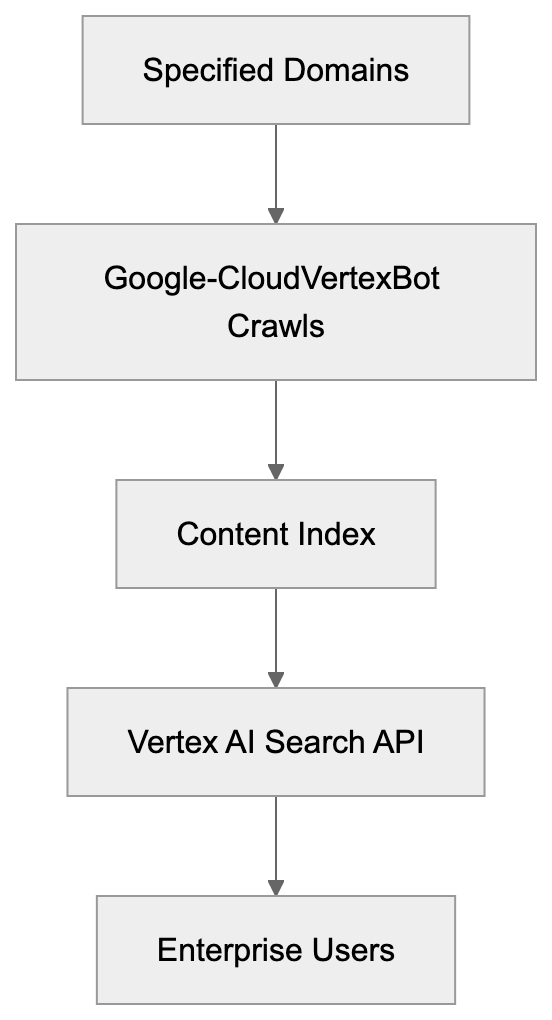
Vertex AI Search is a critical service relying on Google-CloudVertexBot, enabling enterprises to build custom search experiences with AI enhancements. The crawler feeds content into the search index, and when users query a Vertex AI Search application, results come from this indexed content. The process integrates through Google Cloud Console, where developers configure data sources for their search applications. Web crawling serves as one data source option alongside uploaded documents and database connections. Activating web crawling prompts Google-CloudVertexBot to start indexing specified domains. The indexed content becomes searchable via the Vertex AI Search API, providing result snippets, relevance scores, and metadata extracted during crawling. Natural language processing enhances search intent understanding, and grounding with web content improves answer quality compared to solely using uploaded files. Enterprise clients incur fees based on query volume and indexed content size, with the crawler running continuously to update the index. Developers can set crawl frequency and depth limits through the console, making Vertex AI Search more powerful than traditional search engines for specific business use cases.
Comparison with Similar AI Crawlers
| Crawler Name | Parent Company | Primary Purpose | Blocking Method | Relation to Training |
|---|---|---|---|---|
| Google-CloudVertexBot | Google Cloud | Vertex AI Search indexing | robots.txt User-agent | Operational use only |
| Google-Extended | AI model training data | robots.txt User-agent | Direct training use | |
| GPTBot | OpenAI | ChatGPT training data | robots.txt User-agent | Direct training use |
| CCBot | Common Crawl | Open dataset creation | robots.txt User-agent | Training data source |
| ClaudeBot | Anthropic | Claude model training | robots.txt User-agent | Direct training use |
| Amazonbot | Amazon | Alexa and search | robots.txt User-agent | Multiple purposes |
Google-CloudVertexBot differs from training-focused crawlers. GPTBot and ClaudeBot gather data to improve language models, while Google-CloudVertexBot indexes content for live search applications. Common Crawl’s CCBot provides public datasets for AI companies. Amazonbot caters to both search and AI needs. Despite respecting robots.txt, these crawlers have distinct uses. Website owners should consider each bot’s purpose when determining access policies. Blocking training bots protects content from model development, whereas blocking operational bots like Google-CloudVertexBot impacts live applications. The distinction matters for content strategy, as some sites allow operational crawlers while blocking training crawlers. Others block all AI-related bots. Understanding each bot’s function facilitates informed decisions.
Enterprise Use Cases
Enterprises utilize Vertex AI Search with Google-CloudVertexBot for various applications. Customer support teams build knowledge bases that draw from company websites and documentation, with the crawler automatically keeping this information current. E-commerce platforms design product search tools referencing manufacturer websites and reviews. Financial services companies develop research tools that index analyst reports and news sites. Healthcare organizations create medical reference systems crawling trusted health information sources. Legal firms build case law search tools indexing court websites and legal databases. The common theme is domain-specific search powered by curated web content. The bot handles indexing while developers focus on search logic and user experience. This approach outperforms general web search for specialized business needs. Companies control which sources feed their search applications, receiving fresh content without manual updates. Costs scale with usage, suiting both small and large deployments. Combining with other Google Cloud services allows building complete applications around search functionality.
Privacy and Data Handling
Google-CloudVertexBot operates under Google Cloud’s privacy policies, with crawled content stored in Google Cloud infrastructure. Access depends on Vertex AI application configurations, allowing only authorized users of a specific Vertex AI Search application to query its indexed content. The content isn’t used for general Google services or displayed in public search results. Data residency options let enterprises choose geographic storage locations for crawled content. Encryption secures data both in transit and at rest. Website owners retain copyright over their crawled content. The bot doesn’t execute JavaScript by default, limiting dynamic content capture. Personal information in crawled content remains subject to privacy regulations. Enterprises must comply with GDPR, CCPA, and other data protection laws, with Google providing data processing agreements for enterprise customers. The crawler respects standard privacy signals like robots.txt and meta tags. Website owners concerned about specific content should use technical controls to restrict crawling. The bot doesn’t bypass paywalls or login requirements, focusing on public content.
Monitoring and Managing Bot Access
Website administrators should monitor Google-CloudVertexBot activity through server logs, looking for the specific user-agent string in access logs. High crawl rates might indicate a misconfigured Vertex AI application. Contact Google Cloud support if crawl behavior seems abnormal. Server load from the bot should be minimal under normal conditions. Implement rate limiting if necessary to protect server resources. Use crawl-delay directives in robots.txt to control visit frequency:
User-agent: Google-CloudVertexBot
Crawl-delay: 10This requests a 10-second delay between requests. While not all crawlers honor crawl-delay, Google’s bots generally do. Analytics tools can track bot traffic separately from human visitors. Set up alerts for unusual crawl patterns. Document which site sections allow the bot for future reference. Review robots.txt rules periodically to ensure they align with current policies. Consider the business value of allowing the crawler versus protecting content. Some content benefits from wider distribution through Vertex AI applications, while others should remain restricted. The decision depends on business goals and content sensitivity. Managing bot access is ongoing as websites and policies evolve.
Future of Vertex AI Crawling
Vertex AI continues evolving as Google Cloud expands AI capabilities. The crawler will likely gain more sophisticated content handling abilities. Future versions might better interpret JavaScript-rendered content and multimedia. Google may offer more granular controls for website owners. The relationship between crawling and AI grounding will grow as enterprises embrace generative AI. Expect tighter integrations between Vertex AI Search and other Google Cloud services. The crawler might add support for more content types like PDFs and videos. Rate limiting and resource usage will improve as technology matures. Google will likely increase transparency about crawl schedules and behavior. Website owners might gain dashboards showing their content’s appearance in Vertex AI applications. The distinction between training crawlers and operational crawlers will become clearer. Regulations around AI and data collection will influence the bot’s operation. Enterprise demand for grounded AI responses will drive continued development. Understanding Google-CloudVertexBot now prepares website owners and developers for this evolving landscape.
Vertex AI Search Architecture:
Conclusion
Google-CloudVertexBot serves a specific role in the Vertex AI ecosystem, crawling websites to index content for Vertex AI Search applications used by enterprises. It differs from training-focused crawlers like Google-Extended and GPTBot. Website owners can control access through robots.txt directives using the specific user-agent token. Understanding the bot aids developers building on Vertex AI and website administrators managing content policies. The crawler enables AI grounding, improving response accuracy. As enterprise AI adoption grows, operational crawlers like Google-CloudVertexBot will become more common. Balancing content protection with potential benefits from appearing in AI-powered applications is crucial. Key points include understanding the bot’s function, how it contrasts with training crawlers, and how to manage its access to your content.
Frequently Asked Questions
How can I check if Google-CloudVertexBot is crawling my website?
You can monitor Google-CloudVertexBot's activity by checking your server logs for the specific user-agent string: Google-CloudVertexBot/1.0 (+https://cloud.google.com/vertex-ai/docs/generative-ai/learn/overview). Analyze the logs to see the frequency and timing of the bot's requests to ensure it's functioning as expected.
What should I do if Google-CloudVertexBot's crawling affects my website's performance?
If you experience high server load due to the bot, consider implementing rate limiting through the robots.txt file using the crawl-delay directive. You may also contact Google Cloud support to discuss unusual crawl patterns or request adjustments in crawling frequency.
Can I customize which content is indexed by Google-CloudVertexBot?
Yes, website owners can manage which content Google-CloudVertexBot crawls by editing the robots.txt file. You can specify which directories or files to block while allowing others, thereby controlling the content that appears in Vertex AI Search results.
Is it possible to block Google-CloudVertexBot without affecting other crawlers?
Yes, you can specifically block Google-CloudVertexBot using its user-agent token in your robots.txt file without impacting other crawlers like Googlebot. This allows you to control access for Vertex AI while keeping traditional indexing bots operational.
How does the content collected by Google-CloudVertexBot remain private?
Content collected by Google-CloudVertexBot is stored according to Google Cloud's privacy policies. Access is limited to authorized users of specific Vertex AI Search applications and the data is not used in general Google services or displayed in public search results.
What happens if I block Google-CloudVertexBot?
Blocking Google-CloudVertexBot means your content will not be indexed for use in Vertex AI Search applications. This can be beneficial for proprietary content or internal documentation that you prefer to keep private from AI applications.
Will Google-CloudVertexBot update its crawling frequency automatically?
Yes, Google-CloudVertexBot typically updates its crawl frequency based on content changes and Vertex AI application configurations. However, website owners can influence crawl frequency by adjusting settings within their Vertex AI Search configurations.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.