Understanding ia_archiver: The Legacy Internet Archive Crawler
Learn about ia_archiver, the legacy Internet Archive bot that powered the Wayback Machine and why it still appears in robots.txt files today.
What is ia_archiver and Why It Matters
The ia_archiver is a web crawler integral to the Internet Archive’s mission of web archiving. This Internet Archive bot was initially employed to collect and preserve web pages for the Wayback Machine. Web crawlers, like ia_archiver, are automated programs that visit websites and download content for indexing or archiving purposes. The Internet Archive created this legacy crawler to build a massive digital library of web content, capturing snapshots of websites over time. Since the late 1990s, this archive bot has played a pivotal role in preserving internet history by systematically crawling billions of web pages. Even though the Internet Archive has transitioned to newer technology like the Wayback Machine crawler, ia_archiver remains an important part of history. Many website owners still reference this web crawler in their robots.txt files to manage how their content is archived. Understanding ia_archiver helps web developers and site administrators make informed decisions about allowing or blocking archival activities on their websites.
The Purpose and History of ia_archiver
The Internet Archive launched the Wayback Machine in 1996 to preserve digital content and make it accessible to the public. The ia_archiver bot was developed to support this mission by automatically visiting websites and capturing their content. Its main purpose was creating historical snapshots of web pages, allowing researchers, historians, and the general public to access older website versions. The crawler followed links from page to page, downloading HTML content, images, stylesheets, and other resources, storing this data in the Internet Archive’s massive database, which now holds over 735 billion web pages. The ia_archiver documented the evolution of websites, captured content that might otherwise be lost, and provided a valuable resource for studying internet history. Website owners could use robots.txt files to control the bot’s access, allowing them to opt out of archiving if desired. The crawler respected these files and would skip pages marked as disallowed.
How ia_archiver Works and Technical Details
Web Crawler Operation Overview:
The ia_archiver identifies itself through a specific user agent string when making requests to web servers. This user agent appears as “ia_archiver” or variations, including version information in server logs. When visiting a website, the web crawler first checks the robots.txt file to see which pages it’s allowed to crawl. It sends HTTP requests to retrieve page content, following a politeness policy to avoid overloading servers. Typically, it waits between requests and limits the number of simultaneous connections to a single domain. The bot collects HTML documents, embedded resources like images and CSS files, and metadata about each page. This data gets timestamped and stored in the Internet Archive’s repository. It operated on a schedule, revisiting popular sites more frequently than obscure ones, using distributed systems to handle the massive scale required to archive billions of pages. Website administrators can see ia_archiver visits in their server logs and traffic analytics tools.
Why ia_archiver Still Appears in robots.txt Files
Despite the Internet Archive’s move to newer crawler technology, many websites still include ia_archiver directives in their robots.txt files. This is mainly due to legacy configuration and caution. Website owners who set up robots.txt rules years ago often keep them because they still work. Some administrators are unsure which Internet Archive crawlers are currently active, so they continue to block ia_archiver for safety. Although the Internet Archive uses “archive.org_bot” primarily now, ia_archiver might still be used for specific tasks. To ensure full coverage, some website owners block both crawlers. Robots.txt files also serve as documentation of a site’s crawling policies, and removing old entries can be postponed maintenance. Additionally, some sites copy robots.txt templates with ia_archiver blocks without fully understanding the current relevance of each crawler.
Comparing ia_archiver to Modern Web Crawlers
Understanding ia_archiver’s role and importance requires comparing it to modern web crawlers. Below is a table detailing different crawlers:
| Crawler | Purpose | Owner | Current Status | Respects robots.txt |
|---|---|---|---|---|
| ia_archiver | Web archiving | Internet Archive | Heritage, limited use | Yes |
| archive.org_bot | Web archiving | Internet Archive | Active | Yes |
| Googlebot | Search indexing | Active | Yes | |
| Bingbot | Search indexing | Microsoft | Active | Yes |
| CCBot | Dataset collection | Common Crawl | Active | Yes |
| Screaming Frog | SEO analysis | Screaming Frog | Active | Yes |
Internet Archive Crawler Evolution:

The ia_archiver differs from crawlers like Googlebot, whose purpose is search indexing and ranking, while ia_archiver focuses on preserving historical snapshots. The Internet Archive’s newer archive.org_bot offers similar functions with updated technology and performance. CCBot, for instance, creates datasets for research rather than maintaining a browsable archive. SEO tools like Screaming Frog are used on a smaller scale. All these crawlers respect robots.txt directives and identify themselves through user agent strings.
How Website Owners and Businesses Use Crawler Controls
Website administrators utilize robots.txt files to manage which crawlers can access their content and which pages should be excluded. Some businesses block ia_archiver for reasons such as preventing competitors from viewing historical pricing or avoiding easy access to old brand iterations. Websites with frequently changing content might see little value in archiving, while privacy concerns or data retention laws might prompt others to block it. Nonetheless, many allow archiving for its benefits, such as serving as backups and aiding research. The Internet Archive estimates archiving about 1 billion pages weekly across all its crawlers. Owners can use targeted robots.txt rules if they wish to allow general archiving while blocking specific sections.
robots.txt Access Control Flow:
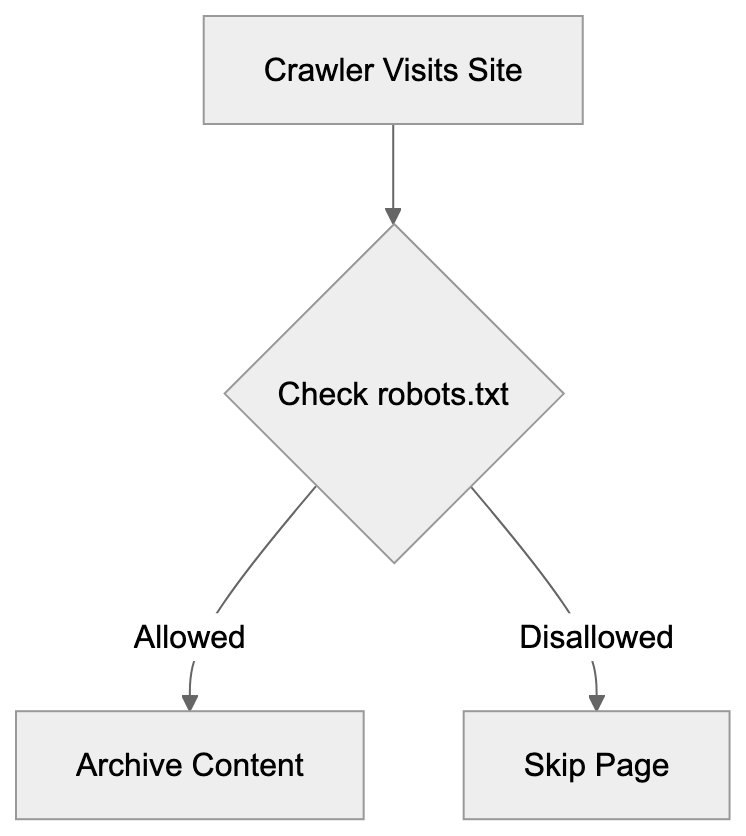
Managing ia_archiver Access Through robots.txt
Controlling ia_archiver access involves adding specific directives to your website’s robots.txt file. The file should be located at the root of your domain. To block ia_archiver entirely, add these lines:
User-agent: ia_archiver
Disallow: /This tells the crawler not to archive any pages on your site. To allow most content but block specific directories, use:
User-agent: ia_archiver
Disallow: /private/
Disallow: /admin/These rules permit archiving of most pages while excluding private and admin sections. If you want unrestricted archiving, omit ia_archiver from robots.txt, as the crawler assumes access is permitted by default. Note that robots.txt is advisory, not enforced. Reputable crawlers like ia_archiver respect these rules, but malicious bots might not. Blocking a page from archiving doesn’t remove existing archived versions; you need to contact the Internet Archive for removal. Many administrators also block the archive.org_bot using similar syntax for complete coverage. Testing your robots.txt file with a validator tool helps catch syntax errors that might accidentally allow or block unintended access.
The Current State of Internet Archive Crawling
The Internet Archive has significantly evolved its crawling infrastructure since the early days of ia_archiver. It now uses archive.org_bot as its primary crawler, featuring improved technology to handle modern web aspects like JavaScript-heavy sites. The Archive crawls roughly 1 billion pages weekly, storing over 735 billion web pages in total as of 2024. Besides automated crawling, the Archive also accepts direct submissions through the “Save Page Now” feature for immediate URL archiving. It partners with libraries and institutions to preserve digital collections, prioritizing important and frequently updated content, while still ensuring broad web coverage. The infrastructure relies on distributed systems and significant bandwidth. Website owners can verify Internet Archive crawlers accessing their sites by examining server logs for user agent strings. Shifting from ia_archiver to archive.org_bot reflects efforts to improve archiving quality.
Privacy and Legal Considerations for Web Archiving
Web archiving raises questions about privacy, copyright, and the right to be forgotten. The Internet Archive operates with the belief that preserving internet history serves the public interest, though some oppose having their content archived without permission. The Archive respects robots.txt directives and excludes content upon request. They maintain a process for removing archives when legally required or due to strong privacy concerns. European regulations like GDPR have affected how archiving services handle personal data, prompting some sites to block archiving for data protection compliance. Copyright holders sometimes request removal of archived content they believe infringes on their rights, and the Archive generally complies with legitimate requests. Archiving is considered fair use for preservation and research, though laws can vary by jurisdiction. Website owners should remember to submit separate removal requests for existing archives, as blocking future archiving doesn’t automatically delete past versions.
End
The ia_archiver represents an important chapter in internet history as one of the initial web crawlers dedicated to digital preservation. While the Internet Archive has moved to newer technology like archive.org_bot, ia_archiver’s legacy persists through continued references in robots.txt files and its role in building the extensive Wayback Machine archive. Understanding this crawler aids website administrators in making informed decisions on archival access to their content. The bot adhered to standard web crawling etiquette and respected robots.txt directives. Although today’s web archiving involves multiple crawlers, the core mission remains to preserve digital content for future generations. Website owners should update their robots.txt files to address heritage crawlers like ia_archiver and current ones like archive.org_bot. The Internet Archive’s efforts provide valuable services for researchers, historians, and others interested in tracking website evolution over time.
Frequently Asked Questions
What is the role of ia_archiver in web archiving?
ia_archiver is a web crawler created by the Internet Archive to collect and preserve web content for the Wayback Machine. It systematically crawls websites, downloading content to create historical snapshots that are accessible to researchers and the public.
How do I block ia_archiver from my website?
You can block ia_archiver by adding specific directives to your robots.txt file located at the root of your domain. For example, including 'User-agent: ia_archiver' followed by 'Disallow: /' will prevent the crawler from accessing any pages on your site.
Can I remove previously archived content from the Internet Archive?
No, blocking future access through robots.txt does not remove already archived pages. To have existing pages removed, you must submit a request directly to the Internet Archive.
What should website owners consider regarding privacy?
Website owners must be aware that archiving can raise privacy and copyright concerns. They should use robots.txt to manage access and comply with legal requirements, such as GDPR, by blocking archiving if necessary and submitting removal requests for sensitive content.
What distinguishes ia_archiver from modern crawlers?
ia_archiver primarily focuses on web archiving, capturing historical content, whereas modern crawlers like Googlebot optimize for search indexing and ranking. The newer archive.org_bot is designed to handle advanced web technologies more effectively than ia_archiver.
How often does the Internet Archive crawl websites?
The Internet Archive’s crawlers, including archive.org_bot, operate on a schedule, crawling approximately one billion pages weekly. The frequency of visits generally depends on the popularity and importance of the website.
How can website administrators monitor ia_archiver activity?
Website administrators can check their server logs for the user agent string associated with ia_archiver or the current archive.org_bot to monitor their crawling activities. Traffic analytics tools also typically provide insights into crawler visits.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.