ImagesiftBot Guide: Image AI Training Crawler Explained
Learn about ImagesiftBot's role in AI image training, its connection to The Hive, blocking methods, and what it means for your website content.
What is ImagesiftBot
ImagesiftBot is an image-focused web crawler operated by The Hive, designed to collect images from websites across the internet. This image training bot is specifically aimed at gathering visual content for AI model training purposes. Unlike general web crawlers, which index text and various content types, ImagesiftBot targets image files, similar to other AI data scrapers like imageSpider operated by ByteDance. It automatically visits websites, downloading images to build AI training datasets. These datasets are used to train computer vision models and other AI systems needing to understand visual information, a practice common among AI companies requiring massive amounts of image data for model training. Website owners should be aware that ImagesiftBot could be accessing their images without explicit permission, as it operates similarly to other AI data scrapers that systematically crawl websites to collect training data for machine learning models. Identified by a specific user agent string, it can be detected and blocked if desired, similar to other AI data scrapers that can be blocked using standard robots.txt rules. Understanding ImagesiftBot’s operation allows you to make informed decisions about including your visual content in AI training datasets.
Why ImagesiftBot Exists and Its Purpose
ImagesiftBot Operation Flow:
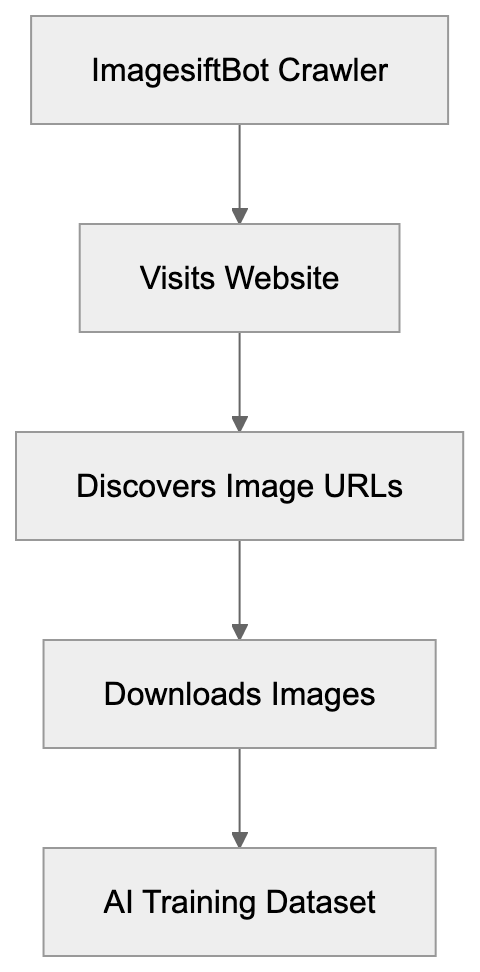
AI companies require massive amounts of image data to train their models. Whether for computer vision systems, image recognition tools, or generative AI models, vast quantities of example images are essential for learning patterns and features. Manually gathering this many images is unfeasible, making automated crawlers like ImagesiftBot necessary. The Hive uses this bot to compile extensive AI image data datasets for various machine learning projects. The goal is clear: acquire diverse visual content from the web to create training data. This data enables AI models to recognize objects, understand scenes, identify patterns, and generate new images. Without large image collections, modern AI vision systems would not function effectively. The bot crawls public websites to access a wide array of images, representing real-world visual diversity, in styles, contexts, and qualities, thus enhancing AI model performance.
How The Hive and Users Utilize ImagesiftBot
The Hive operates ImagesiftBot as part of its data collection infrastructure, running the crawler continuously to gather fresh image content. Once collected, images are processed into datasets that can be cleaned, categorized, and prepared for machine learning training. The Hive may use these datasets internally or license them to other companies building computer vision systems. Some dataset companies provide their collections to researchers and developers who cannot independently collect training data. While the crawler respects some technical signals like robots.txt files, it requires explicit blockage by website owners. Operating on scheduled intervals, it revisits sites to record new images. For businesses using The Hive’s services, these datasets offer ready-made training data, saving significant time and effort in AI development.
Technical Details and User Agent Information
ImagesiftBot identifies itself via a specific user agent string when making website requests, typically formatted as ‘Mozilla/5.0 (compatible; ImagesiftBot; +http://imagesift.com/crawler.html)’. This identification allows web servers and owners to detect the bot’s content access. Primarily making GET requests to image URLs, it also crawls HTML pages to discover new image links, focusing on common image formats like JPG, PNG, GIF, and WebP. Although it doesn’t typically overload servers with excessive requests, its crawling frequency aligns with The Hive’s data collection needs. To check ImagesiftBot’s access to your site, examine server logs for the bot’s user agent string. Originating from IP addresses linked to The Hive, the crawler may follow sitemap.xml files and can parse HTML img tags and CSS background images for visual content.
Blocking ImagesiftBot from Your Website
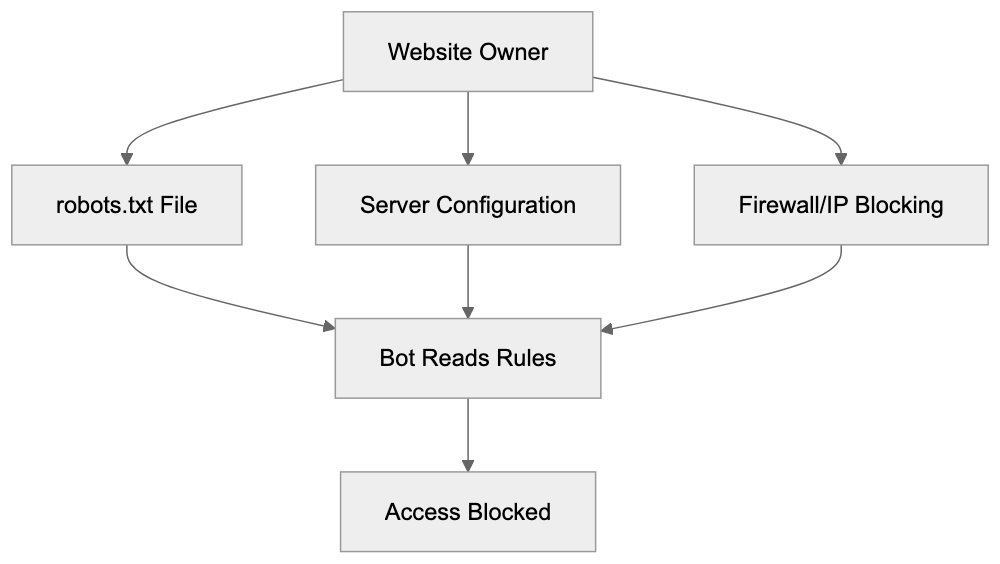
Website owners have several options for preventing ImagesiftBot from accessing their images. The most common method is using the robots.txt file, a standard for communicating crawling rules to bots. To block ImagesiftBot while allowing others, add specific directives to your robots.txt file:
User-agent: ImagesiftBot
Disallow: /This directive prevents the bot from crawling any part of your website. To block specific directories only, specify those paths, such as ‘Disallow: /images/’. Remember, robots.txt relies on voluntary compliance, so some bots may ignore these rules. For a more reliable block, use server-level blocking via .htaccess files on Apache servers or server configuration files on Nginx. Another option involves using firewalls or security tools to block IP addresses associated with ImagesiftBot, though this requires ongoing maintenance. Some content management systems offer bot-blocking features without needing direct configuration file edits.
Comparison with Alternative Image Crawlers
Blocking ImagesiftBot Methods:
ImagesiftBot isn’t alone in collecting images for AI training. Several companies operate similar bots:
| Crawler Name | Operated By | Primary Purpose | User Agent String | Blocking Difficulty |
|---|---|---|---|---|
| ImagesiftBot | The Hive | Image collection for AI training | ImagesiftBot | Easy via robots.txt |
| GPTBot | OpenAI | Content collection for ChatGPT training | GPTBot | Easy via robots.txt |
| Google-Extended | AI training data | Google-Extended | Easy via robots.txt | |
| CCBot | Common Crawl | General web archiving and AI datasets | CCBot | Easy via robots.txt |
| Bytespider | ByteDance | Content collection for AI products | Bytespider | Easy via robots.txt |
| ClaudeBot | Anthropic | Training data for Claude AI | ClaudeBot | Easy via robots.txt |
Each crawler serves similar functions for different organizations. ImagesiftBot focuses specifically on image content, while others may collect text and images. Blocking methods are similar, relying on robots.txt directives and user agent strings. Website owners concerned about AI training should consider blocking multiple crawlers, not just ImagesiftBot, as effectiveness depends on crawler operators respecting robots.txt.
Implications for Content Creators and Website Owners
When ImagesiftBot crawls your website, collected images may enter AI training datasets, raising questions about copyright, attribution, and control over your creative work. Images you created might be used to train models that generate similar content, potentially devaluing original work or enabling AI to replicate your style without compensation. Legal clarity on web scraping for AI training varies by jurisdiction, and the law has not fully caught up with AI advancements. Some creators block AI crawlers for protection, while others see contribution to AI advancement as inevitable. Businesses should consider brand control and competitive impacts, as their images could train AI systems used by competitors. Blocking decisions depend on your situation, content type, and views on AI development.
Privacy and Data Collection Considerations
Image Collection Privacy Concerns:
 Although ImagesiftBot collects publicly accessible images, privacy implications remain. Photos of identifiable people, private events, or sensitive locations could be included in datasets if found on public websites. User-generated content platforms face challenges as they host photos uploaded by individuals who may be unaware their content is scraped for AI training. Website owners should ensure privacy policies address third-party crawling and data collection. Regulations like Europe’s GDPR may apply, depending on the content and users involved. Additionally, face recognition models trained on scraped data raise privacy and consent issues. The Hive argues its data collection involves public information, but public doesn’t always mean consent. Website owners can employ techniques beyond blocking crawlers, such as watermarking images or using lower resolution versions to limit collection.
Although ImagesiftBot collects publicly accessible images, privacy implications remain. Photos of identifiable people, private events, or sensitive locations could be included in datasets if found on public websites. User-generated content platforms face challenges as they host photos uploaded by individuals who may be unaware their content is scraped for AI training. Website owners should ensure privacy policies address third-party crawling and data collection. Regulations like Europe’s GDPR may apply, depending on the content and users involved. Additionally, face recognition models trained on scraped data raise privacy and consent issues. The Hive argues its data collection involves public information, but public doesn’t always mean consent. Website owners can employ techniques beyond blocking crawlers, such as watermarking images or using lower resolution versions to limit collection.
Monitoring and Detecting ImagesiftBot Activity
You can monitor whether ImagesiftBot accesses your website by examining server logs, available through most hosting control panels. Look for entries with ImagesiftBot in the user agent field. Log analysis tools can help filter and count bot visits. Google Analytics often filters out bot traffic by default, so raw server logs provide a complete picture. If you find ImagesiftBot activity and wish to block it, implement blocking methods and monitor to ensure effectiveness. Sometimes bots don’t quickly respect robots.txt changes, making server-level blocks more immediate. Setting alerts for specific user agent access keeps you informed of crawler activity. Some security tools offer bot detection features, aiding resource management on high-traffic websites.
The Future of AI Image Crawlers
As AI technology advances, image collection for training is likely to continue and expand. With more companies developing computer vision systems and generative image models, demand for image datasets rises. Consequently, more crawlers like ImagesiftBot may emerge. Industry standards for ethical data collection and clearer content usage controls may evolve, potentially involving machine-readable rights declarations. Legal frameworks may change as copyright cases involving AI training progress through courts, affecting data collection practices. Website owners should stay informed about these developments. While tools for managing crawler access may improve, awareness and proactive management of crawler access remain crucial for those wishing to control their image usage.
Frequently Asked Questions
What kind of images does ImagesiftBot collect?
ImagesiftBot primarily targets publicly accessible images in formats such as JPG, PNG, GIF, and WebP. It crawls websites to gather a wide array of visual content to build datasets for training AI models.
Can website owners prevent ImagesiftBot from accessing their images?
Yes, website owners can block ImagesiftBot by adding specific directives to their robots.txt file or using server-level controls like .htaccess for Apache servers. For more comprehensive blocking, some may choose to restrict IP addresses associated with the bot.
What are the implications for creators if their images are used in AI training?
When authors' images are collected, they may be used in ways that could devalue original works or lead to unauthorized style replication by AI. There are also concerns regarding copyright and attribution, as legal interpretations can vary.
How can I monitor if ImagesiftBot is accessing my website?
You can check your server logs for entries indicating access by the ImagesiftBot user agent. Monitoring tools and alerts for specific user-agent activity may also help track bot visits efficiently.
What steps can I take if I find ImagesiftBot on my site?
If you discover ImagesiftBot accessing your site and wish to block it, you can modify your robots.txt file, implement server-level blocking, or utilize security tools to restrict its access. It's advisable to monitor the effectiveness of these measures.
What legal considerations should website owners keep in mind regarding ImagesiftBot?
Legal frameworks concerning web scraping and AI training are still evolving, with varying interpretations across jurisdictions. Compliance with privacy regulations like GDPR may also be relevant, particularly if identifiable individuals are photographed.
Is it possible for ImagesiftBot to collect images without consent?
Yes, since ImagesiftBot collects publicly available images, it may include content uploaded by users unaware it’s being scraped. This raises potential privacy concerns, especially in contexts where individuals expect their content to remain private.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.