AI Crawlers: How They Work and Why They Matter
Learn what AI crawlers are, how they operate, and why they're essential for training AI models. Complete guide for developers and tech professionals.
What Are AI Crawlers
AI crawlers are automated programs that systematically browse the internet, collecting text, images, code, and various forms of data from websites. This data is essential for training large language models and other AI systems. Think of them as web crawlers with a focused objective: gathering training material for artificial intelligence.
Most major AI companies run these crawlers constantly. They scan billions of web pages to build extensive datasets. The crawlers follow links from page to page, similar to how you might browse the web, but at an immense scale and speed. Companies such as OpenAI, Google, and Anthropic operate their own bot crawlers. The data they collect is fundamental to AI training data for models like ChatGPT, Gemini, and Claude.
These tools exist because AI models require vast amounts of text and data to learn language patterns. Without crawlers, companies would need to manually compile machine learning data, an impossible task at the required scale. Web developers and site owners should comprehend how these bots work. They directly impact website traffic and server load. Marketing professionals also need to be aware, as AI crawlers affect how content is utilized by AI systems.
Why AI Crawlers Exist and Their Purpose
The primary purpose of AI crawlers is AI data collection for machine learning. Modern language models need terabytes of text data to function correctly. No single organization holds that much proprietary content, so companies develop crawlers to gather publicly available information across the internet.
AI Crawler Operation Overview:
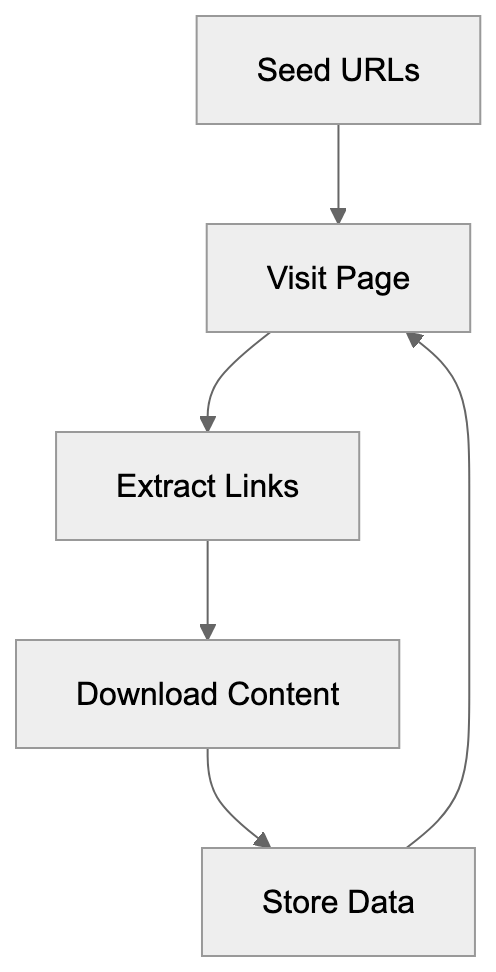
AI crawlers serve several functions:
- Collect varied language examples from different sources to help AI systems understand various writing styles and topics.
- Gather factual information that models can reference.
- Collect code examples from repositories and technical documentation to train AI coding assistants.
This crawling process is continuous, as new content appears online every second. AI companies aim to have their models trained on both current and diverse information. Consequently, crawlers run 24/7, scanning for new pages and updates. Although crawlers follow rules set in robots.txt files, not all adhere to these instructions equally.
Small business owners should be aware of this phenomenon. AI crawlers consume server resources; multiple bots visiting a site simultaneously can slow it down. SEO experts also need to understand crawler behavior and how robots.txt configurations affect whether AI companies can use your content for training. Some sites block AI crawlers entirely, while others allow them, hoping for better visibility in AI-generated responses.
How AI Crawlers Operate
AI crawlers begin with seed URLs, a list of starting points, and follow each link they find. This process, known as recursive crawling, results in a map of connections between pages.
Most crawlers identify themselves through their user agent string, a sort of name tag for bots. GPTBot represents OpenAI’s crawler, Google-Extended signifies Google’s AI training crawler, and Anthropic’s bot, ClaudeBot, is similarly identifiable. These identifiers appear in website logs when crawlers access pages.
Crawlers download page content, strip out HTML formatting, and extract text, and sometimes images and metadata. This raw data is stored in vast databases and subsequently goes through cleaning and filtering processes before becoming part of the training datasets.
Crawl frequency varies by site importance, with popular sites that frequently update being crawled more often. Smaller sites might experience weekly or monthly visits. The bots strive to be polite by spacing out requests, but errors may result in overwhelmed servers.
Web developers can manage crawler access using robots.txt configuration, adding specific rules about what bots can and cannot access. Here is how to block different bots:
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /AI Crawler Recursive Process:

This tells the named crawlers not to access any part of your site. However, not all crawlers respect these requests; some less reputable ones ignore robots.txt instructions entirely.
Real World Usage by Companies
OpenAI employs GPTBot for AI data collection for GPT models, visiting millions of websites daily. It searches for text that helps enhance ChatGPT’s knowledge and responses. OpenAI asserts that they filter out paywalled content and personally identifiable information, yet the crawler still amasses a vast amount of public data.
Google operates Google-Extended specifically for AI training, distinct from their search crawler. The bot feeds data into Gemini and other AI products, leveraging Google’s extensive web crawling infrastructure for search and AI development.
Anthropic runs ClaudeBot to train their Claude AI models, while Meta and Amazon utilize crawlers for LLaMA models and AWS AI services, respectively. Essentially, every major AI company operates crawlers, a standard practice within the industry.
Some businesses utilize third-party datasets, like Common Crawl, which maintains a free web crawl archive. Many AI researchers prefer Common Crawl data over running their own crawlers, leveraging its petabytes of collected web page data.
For content marketers, AI crawlers create a new reality. Published content may train AI models that later compete by generating content similar to yours. This scenario raises complex questions about content strategy and value.
Comparison of Major AI Crawlers
Different AI companies run crawlers with varying behaviors and policies. Here’s a comparison of the major ones:
| Crawler Name | Company | Respects robots.txt | Primary Use | Blocking Method |
|---|---|---|---|---|
| GPTBot | OpenAI | Yes | GPT model training | User-agent: GPTBot |
| Google-Extended | Yes | Gemini/Bard training | User-agent: Google-Extended | |
| ClaudeBot | Anthropic | Yes | Claude model training | User-agent: ClaudeBot |
| CCBot | Common Crawl | Yes | Public dataset creation | User-agent: CCBot |
| Applebot-Extended | Apple | Yes | Apple AI features | User-agent: Applebot-Extended |
Website Crawler Access Control:
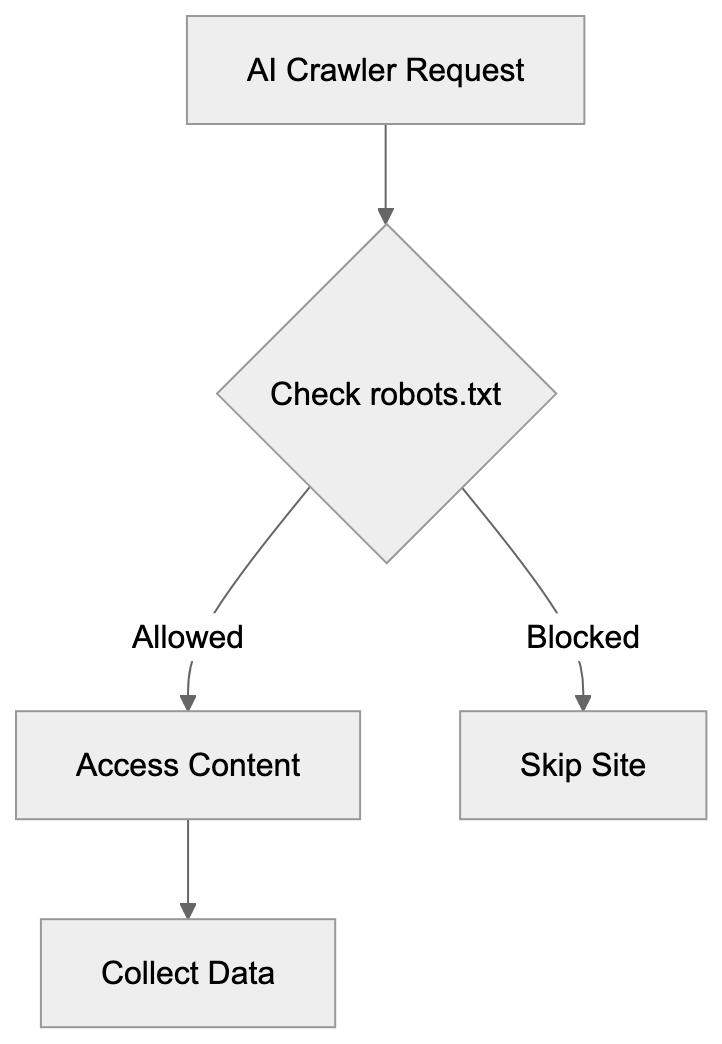
While all major crawlers claim to respect robots.txt directives, they also state they filter sensitive data and follow privacy guidelines—but enforcement varies, and website owners report different experiences with crawler behavior.
Crawl rates differ significantly; Google-Extended tends to be aggressive due to Google’s infrastructure, whereas operations like Anthropic’s crawl more slowly. Common Crawl conducts periodic rather than continuous crawls, publishing new datasets every few months.
Certain crawlers offer opt-out forms on company websites. OpenAI, for instance, provides a form to request GPTBot to cease crawling your domain, and Google offers similar options through Search Console. These alternatives are there if robots.txt blocking isn’t effective.
The SEO community debates whether blocking AI crawlers helps or hurts. Some argue that having content included in AI training data boosts brand visibility, while others aim to protect original content from reproduction. There’s no consensus on best practices yet.
Impact on Website Performance
AI crawlers use bandwidth and server resources. Each bot request consumes resources similar to a human visit, and simultaneous bot crawls can overextend servers. Small business owners using shared hosting might observe performance issues.
Server logs reveal crawler activity patterns, allowing analytics checks for user agents that match known AI bots. High crawler traffic might clarify unexpected bandwidth use, and some hosting providers may charge for bandwidth overages.
To limit crawler impact, apply rate limiting, configuring your server to allow only a specific number of requests per minute from individual bots. This prevents crawlers from overwhelming your infrastructure, even though most reputable crawlers implement their own rate limiting.
Caching reduces crawler load—cached pages serve faster, preserving processing power and database queries. Content delivery networks (CDNs) help by distributing crawler traffic across servers.
For web developers, monitoring crawler behavior is crucial. Alerts for unusual traffic patterns can indicate issues or mean an AI company added your domain to their crawl list.
Legal and Ethical Considerations
AI crawlers navigate a gray legal area by collecting publicly available data, which seems legal but raises questions about copyright and fair use. Content creators argue that using their work to train commercial AI violates their rights. Several lawsuits are ongoing.
Website terms of service sometimes prohibit automated web scraping, and AI companies argue that crawling for AI training data differs from competitive scraping. Courts have yet to fully resolve these issues, and the legal context continues to evolve.
Ethical concerns go beyond legality—should AI companies seek permission to use content for training? Some suggest opting-in instead of out. Others argue that the internet has always operated via automated crawling, hence the ongoing debate in tech communities.
Data privacy introduces additional issues, as crawlers might accidentally collect personal information from public pages. While AI companies claim to filter this out, errors occasionally occur, potentially embedding personal data in training sets and outputs.
Marketing professionals should weigh these factors when designing content strategies, recognizing that publishing online might contribute to AI training data. Some companies accept and optimize content for AI discovery, whereas others block crawlers to maintain content control.
Future of AI Crawlers
AI crawler technology is advancing continuously. Future crawlers may become more selective, targeting high-quality sources over quantity, therefore reducing server load while improving training data quality.
Multimodal crawlers, which gather images, videos, and audio alongside text, are emerging as future AI models learn to handle multiple content types. In response, crawlers must sophisticate their web page parsing abilities.
Crawler boundaries might improve with industry standards, as discussions about common frameworks for AI data collection continue. Standardized opt-out mechanisms could replace the current patchwork of solutions, benefitting both site owners and AI companies.
Increased transparency in crawler identification is plausible as companies face pressure to openly announce their crawling activities. Enhanced documentation aids website owners in making informed decisions—some advocate for mandatory crawler registries where companies must list their bots.
The relationship between content creators and AI companies is evolving. Some sites now negotiate terms for crawler access, potentially charging AI companies for training data, thus creating new revenue streams but possibly fragmenting information access.
Conclusion
AI crawlers are automated programs that collect web data essential for training machine learning models. Every major AI company operates these bots to gather the extensive datasets their systems require. These crawlers function by systematically browsing websites and extracting content—similar to regular web crawlers, but at a massive scale.
Understanding AI crawlers is crucial for web developers, business owners, and content creators. These bots consume server resources and utilize your published content for AI training. You can manage crawler access through robots.txt configuration and rate limiting. Different companies maintain different crawlers with unique behaviors and policies.
This technology poses significant questions about copyright, fair use, and content ownership, with legal frameworks around AI training data collection still developing. In the interim, AI crawlers continue as a standard part of AI operations. Website owners should monitor crawler activity and make informed decisions about allowing or blocking access, depending on their needs and concerns.
Frequently Asked Questions
What types of data do AI crawlers collect?
AI crawlers gather a wide array of data, including text, images, code examples, and metadata from websites. This diverse dataset helps train language models, enabling them to understand different writing styles, factual information, and code syntax.
How can I prevent AI crawlers from accessing my website?
You can control crawler access by configuring your site's robots.txt file to specify which bots are allowed or disallowed. For example, you can use specific commands to prevent crawlers like GPTBot or Google-Extended from accessing any part of your site.
Do all AI crawlers respect robots.txt directives?
While major AI crawlers claim to respect robots.txt directives, compliance can vary. Some less reputable crawlers may ignore these instructions entirely, so website owners should monitor their server logs for any unwanted bot activity.
How do AI crawlers impact website performance?
AI crawlers can consume significant server resources as each request is similar to a human visit. When multiple bots access a site simultaneously, it may slow down or overwhelm the server, particularly on shared hosting plans.
What are the legal implications of AI crawlers collecting data?
The legality of AI crawlers collecting publicly available data remains a gray area, with ongoing lawsuits addressing copyright and fair use issues. While crawling itself is generally accepted, the use of the data for commercial AI training raises concerns among content creators.
Can I limit the amount of data crawlers can collect from my site?
Website owners can limit crawler impact through techniques like rate limiting and caching. These approaches help manage the number of requests a crawler can make, ensuring they do not overwhelm your server.
What should content creators consider regarding AI crawlers?
Content creators should be aware that their published content may end up training AI models, impacting their content strategies. Some may choose to embrace this reality for increased visibility, while others may seek to block crawlers to maintain control over their original work.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.