Understanding ISSCyborg: The Advanced ISS Technology Crawler
Discover the ISSCyborg web crawler's purpose, behavior, and how to manage its data collection effectively.
What is ISSCyborg and Why It Exists
ISSCyborg is a web crawler bot operated by ISS Technology. As a web crawler, ISSCyborg, also known as a web data collection bot, systematically browses websites to collect data for various purposes. These bots are essential tools in the modern internet ecosystem because they help organizations gather information, monitor web content, and build datasets.
The ISS crawler functions similarly to other web crawlers. It visits websites, reads their content, and stores information for later use. You’ll recognize it in your server logs by its distinctive user-agent string, which identifies itself as ISSCyborg.
Web crawlers exist because manual data collection from thousands or millions of web pages would be impossible. They automate the process of visiting websites and extracting information. Companies use this data for market research, competitive analysis, content aggregation, or building search indexes.
Web Crawler Basic Function:
ISSCyborg appears in website access logs alongside other common crawlers like Googlebot or Bingbot. However, unlike major search engine crawlers, there is less public documentation about ISSCyborg’s specific purposes and data usage practices.
How to Identify ISSCyborg in Your Server Logs
The ISSCyborg web crawler identifies itself through its user-agent string. When it visits your website, it sends this identifier in the HTTP request headers. Website administrators can check their server logs to see if ISSCyborg has been accessing their content.
The typical user-agent string for ISSCyborg looks like this: Mozilla/5.0 (compatible; ISSCyborg). This string may vary slightly depending on the version or configuration, but it will always contain the ISSCyborg identifier.
Checking your server logs is straightforward. Most web hosting control panels provide access to raw server logs or analytics tools. Look for entries containing ISSCyborg in the user-agent field. You can also use log analysis tools to filter and count ISSCyborg visits.
The frequency of ISSCyborg visits varies by website. Some sites report daily crawls, while others see it less frequently. The crawl rate depends on factors like your site’s size, update frequency, and how ISS Technology prioritizes different domains.
Crawling Behavior and Data Collection Patterns
ISSCyborg follows standard web crawling practices in most cases. It respects the robots.txt file, which tells crawlers which parts of a website they can or cannot access. Website owners can use this file to control ISSCyborg’s behavior on their domains.
The ISS crawler typically requests pages at a moderate rate to avoid overloading servers. Responsible crawlers implement delays between requests and respect server resources, but the exact crawl speed and patterns used by ISSCyborg are not publicly documented.
Like other web crawlers, ISSCyborg collects various types of data from websites. This can include page content, metadata, links, images, and other publicly accessible information. The specific data points collected and how they’re used remain largely undisclosed by ISS Technology.
Website owners should know that any publicly accessible content on their site can potentially be crawled and collected. This includes text, images, structured data, and links. Password-protected or login-required content is typically not accessible to crawlers.
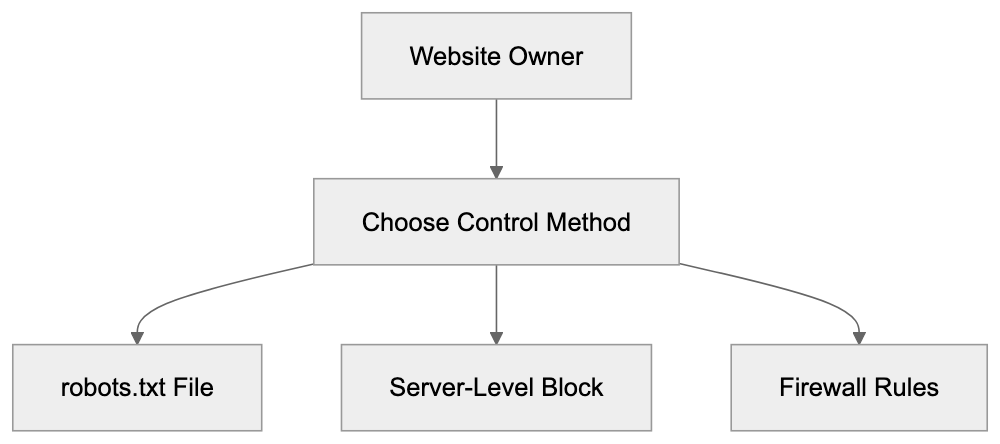
How to Block or Control ISSCyborg Access
If you want to prevent ISSCyborg from crawling your website, you have several options. The most common method is using the robots.txt file. This file sits in your website’s root directory and provides instructions to web crawlers.
To block ISSCyborg completely, add these lines to your robots.txt file:
User-agent: ISSCyborg
Disallow: /This tells ISSCyborg not to crawl any part of your website. If you only want to block specific sections, replace the / with the path to those directories. For example, Disallow: /private/ would block only that folder.
Another option is blocking ISSCyborg at the server level using .htaccess files (for Apache servers) or Nginx configuration. This method actively prevents the crawler from accessing your site rather than just requesting it to stay away, but it requires more technical knowledge to implement correctly.
You can also use firewall rules or security plugins to block requests from ISSCyborg’s IP addresses. This approach works but requires maintaining an updated list of IP ranges used by the crawler. Keep in mind that sophisticated crawlers can rotate IP addresses.
Limited Public Documentation and Transparency
One challenge with ISSCyborg is the limited amount of public information available about it. Unlike major search engine crawlers, which provide extensive documentation, ISS Technology has not published detailed information about ISSCyborg’s purposes or data usage.
This lack of transparency makes it difficult for website owners to make informed decisions about allowing or blocking the crawler. You cannot easily verify what happens to the data ISSCyborg collects or how it might be used commercially.
The absence of clear contact information or an official website specifically for ISSCyborg adds to this opacity. Website administrators who want to request their data be excluded or ask questions about crawling practices may struggle to find appropriate channels.
This situation is not unique to ISSCyborg. Many commercial web crawlers operate with minimal public documentation, but the trend in recent years has moved toward greater transparency, with more crawler operators providing clear information about their bots.
Comparing ISSCyborg to Other Web Crawlers
To understand ISSCyborg better, it helps to compare it with other web crawlers. Different bots serve different purposes and operate with varying levels of transparency and documentation.
| Crawler | Primary Purpose | Public Documentation | Robots.txt Compliance | Owner |
|---|---|---|---|---|
| ISSCyborg | Data collection (specifics unclear) | Limited | Yes (typically) | ISS Technology |
| Googlebot | Search indexing | Extensive | Yes | |
| Bingbot | Search indexing | Extensive | Yes | Microsoft |
| Semrushbot | SEO data collection | Moderate | Yes | Semrush |
| Ahrefsbot | Backlink analysis | Moderate | Yes | Ahrefs |
Crawler Access Control Methods:
Googlebot and Bingbot are the most well-documented crawlers because they power major search engines. They provide detailed technical documentation, verification tools, and clear contact methods. Website owners generally want these crawlers to index their content.
SEO tool crawlers like Semrushbot and Ahrefsbot collect data for competitive analysis and backlink research. They offer moderate documentation and usually respect robots.txt directives. Users of these services benefit from the data collected across the web.
ISSCyborg falls into a category of commercial crawlers with less public information. While it appears to respect robots.txt files, the lack of documentation about its data usage puts it at a disadvantage compared to more transparent alternatives.
Making Decisions About ISSCyborg on Your Website
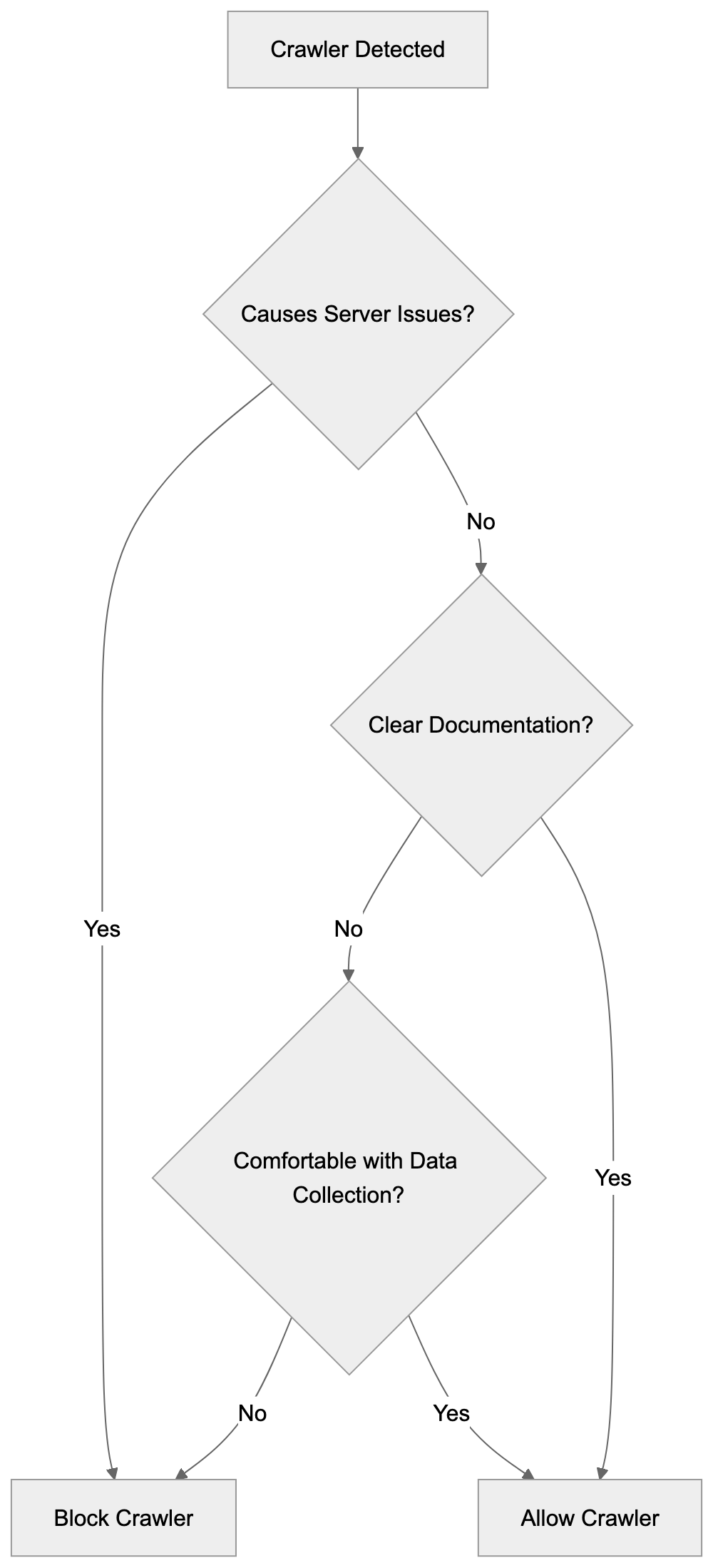
Deciding whether to allow or block ISSCyborg depends on your specific circumstances and concerns. There’s no universal right answer, but several factors can guide your decision.
If your website relies on search engine visibility and organic traffic, blocking legitimate crawlers generally makes sense only when they cause problems. However, ISSCyborg is not a search engine crawler, so blocking it will not affect your search rankings.
Consider your server resources and bandwidth. If ISSCyborg or any crawler creates excessive load on your server, blocking it becomes more justified. Monitor your server logs to see if the crawler’s activity impacts performance.
Privacy and data usage concerns are valid reasons to block crawlers with unclear documentation. If you’re uncomfortable with unknown entities collecting your website’s content without clear disclosure of how they’ll use it, blocking is reasonable.
Some website owners take a permissive approach and allow all crawlers unless they cause specific problems. Others prefer a restrictive approach, only allowing well-documented crawlers with clear purposes. Your choice should match your website’s goals and your comfort level with data collection.
Technical Considerations for Managing Crawler Traffic
Managing web crawler traffic requires some technical understanding, but most website owners can implement basic controls. The robots.txt file is the simplest starting point because it requires no server configuration knowledge.
Create or edit your robots.txt file using any text editor. Upload it to your website’s root directory where yoursite.com/robots.txt will display it. Test the file using online robots.txt validators to ensure proper syntax.
Decision Framework for Blocking Crawlers:
 For more advanced control, server-level blocking provides stronger enforcement. Apache servers use .htaccess files with directives like:
For more advanced control, server-level blocking provides stronger enforcement. Apache servers use .htaccess files with directives like:
SetEnvIfNoCase User-Agent "ISSCyborg" bad_bot
Deny from env=bad_botNginx servers require editing the configuration file with similar logic. These methods actively reject requests rather than relying on crawlers to honor robots.txt directives.
Monitoring tools help you track crawler activity over time. Log analysis software can show you which crawlers visit most frequently, how much bandwidth they consume, and which pages they access. This data helps you make informed decisions about crawler management.
Data Collection Practices and Website Owner Rights
Website owners have rights regarding how their content is accessed and used. While publicly accessible web content can legally be crawled in most jurisdictions, you still control access to your server and can set terms of use.
The robots.txt file represents a widely accepted standard for communicating your preferences to crawlers. Reputable bots respect these directives even though robots.txt is not legally binding. It functions as a technical and ethical guideline.
Some countries have implemented or are considering regulations around web scraping and data collection. These laws vary significantly by jurisdiction. Website owners concerned about data collection should consult local regulations and potentially seek legal advice.
Terms of service on your website can explicitly prohibit certain types of automated access or data collection. While enforcement can be challenging, clear terms provide a legal foundation for your preferences regarding bot access.
The balance between open web access and website owner control continues to evolve. As a website owner, staying informed about your options and implementing appropriate controls helps you maintain autonomy over your content.
Conclusion
ISSCyborg is a web crawler operated by ISS Technology that collects data from publicly accessible websites. Like other commercial crawlers, it systematically visits web pages and gathers information, though the specific purposes and data usage remain unclear due to limited public documentation.
Website owners can identify ISSCyborg through its user-agent string in server logs. The crawler typically respects robots.txt directives, giving you control over what it can access. You can block it entirely or restrict access to specific sections using robots.txt, server configurations, or firewall rules.
The lack of transparency around ISSCyborg’s operations makes it different from well-documented crawlers like Googlebot or Bingbot. This opacity may influence your decision about whether to allow it on your website. Consider factors like server resources, data privacy concerns, and your comfort level with unclear data collection practices when making this choice.
Frequently Asked Questions
What is the purpose of ISSCyborg?
ISSCyborg is a web crawler operated by ISS Technology designed to collect data from publicly accessible websites. It helps organizations gather information for various applications such as market research, competitive analysis, and content aggregation.
How can I identify ISSCyborg visits on my website?
You can identify ISSCyborg by checking your server logs for its user-agent string, which typically appears as "Mozilla/5.0 (compatible; ISSCyborg)." Most web hosting platforms offer tools to help you access these logs easily.
Can I block ISSCyborg from crawling my site?
Yes, you can block ISSCyborg by using the robots.txt file in your website's root directory. You can add "User-agent: ISSCyborg" followed by "Disallow: /" to prevent it from accessing any part of your site.
Does ISSCyborg respect robots.txt files?
ISSCyborg typically respects the directives outlined in robots.txt files, similar to many other web crawlers. This allows website owners to specify which parts of their website can or cannot be accessed by the crawler.
What data does ISSCyborg collect from websites?
ISSCyborg collects various types of publicly available data, which may include page content, metadata, links, and images. However, the specifics of the data it collects and how it is used remain largely undisclosed by ISS Technology.
Is there any public documentation available for ISSCyborg?
Public documentation for ISSCyborg is limited, which can make it challenging for website owners to understand its purposes and data usage. Unlike major search engine crawlers, there is minimal information provided by ISS Technology regarding this crawler.
What should I consider when deciding to allow or block ISSCyborg?
When deciding whether to allow ISSCyborg, consider factors such as your website's reliance on search engine visibility, server load, and privacy concerns. Assessing these elements will help you decide whether to permit or block the crawler's access to your site.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.