MLBot Guide: ML Training Data Crawler Explained
Complete guide to MLBot machine learning crawler. Learn identification methods, user-agent strings, behavior patterns, and blocking options.
What is MLBot
MLBot is a web crawler designed specifically for collecting training data for machine learning models, a process known as data scraping. This machine learning crawler visits websites and scrapes content to build datasets that companies use to train their AI systems. MLBot gathers text, images, and other data to feed into machine learning algorithms, a process that has been regulated to protect website owners’ rights. Unlike search engine bots whose primary task is indexing content for search results, MLBot’s purpose is distinct and focuses on ML data collection, a practice that has raised ethical concerns.
MLBot Web Crawling Process:
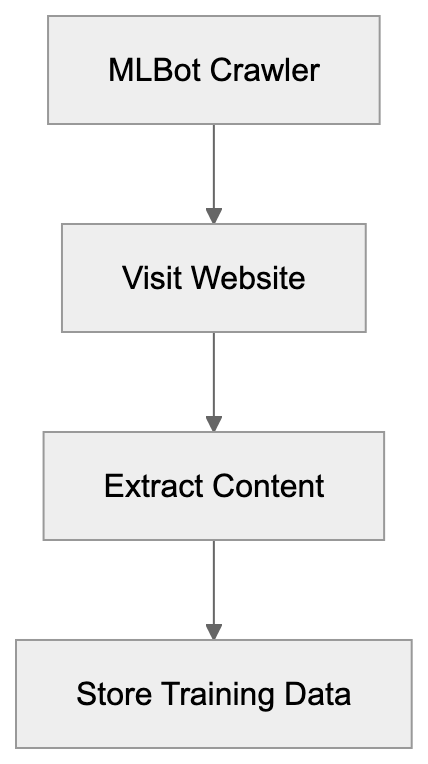
Web crawlers like MLBot have become increasingly common as the demand for ML training data bots has exploded. Companies need a vast amount of varied content to train language models, image recognition systems, and other AI technologies, leading to the development of robots.txt files to manage crawler access. MLBot automates this data collection process by systematically visiting web pages and extracting the information.
The bot operates by following links, much like search engines do. However, unlike Google or Bing bots, which most webmasters welcome, MLBot raises questions about data usage rights and website resource consumption. Understanding how MLBot works helps website owners make informed decisions about whether to allow or block this crawler.
Why MLBot Exists and Its Purpose
The primary purpose of MLBot is to solve the data collection problem that machine learning projects face. Training effective AI models requires enormous datasets. Manual collection of this data would be impossible at the required scale. Automated crawlers like MLBot make it feasible to gather millions or billions of data points.
Companies use bots like MLBot because publicly available datasets often lack diversity or specific content types they need. Custom crawling allows organizations to target particular websites, languages, or content formats. This targeted approach helps create more specialized and effective training datasets.
The bot exists in a legal gray area, though. While crawling public web content is generally permitted under US law, the ethical considerations are complex. Website owners pay for hosting and bandwidth. When bots consume these resources to collect data for commercial AI training, questions arise about fair use and compensation.
MLBot represents the infrastructure layer of the AI industry. Without data collection tools like this, the rapid advancement in machine learning would be much slower. However, website owners do not have to necessarily accept the resource costs and potential copyright concerns that come with these crawlers.
How MLBot is Used by Companies
ML Training Data Pipeline:

Companies deploy MLBot and similar crawlers to build proprietary training datasets. The process typically starts with defining target websites or content types. The bot then systematically visits these sites, extracts relevant content, and stores it in a structured format.
Some organizations use the collected data to train general-purpose language models, while others focus on specific domains like legal documents or medical literature. The crawler can be configured to prioritize certain content types or exclude others based on training objectives.
The data collection happens continuously in many cases. As new content appears on target websites, MLBot revisits and captures updates. This ensures training datasets remain current and reflect evolving language patterns and information.
Web developers and site administrators often find MLBot in their server logs. The bot identifies itself through its user-agent string, though not all ML crawlers are this transparent. Server logs show request patterns, visited URLs, and bandwidth consumption attributed to the bot.
Small business owners should be aware that their website content might be included in ML training datasets without explicit permission. While this is legal in most jurisdictions, it represents a use case many site owners never anticipated when publishing their content online.
Identifying MLBot in Server Logs
MLBot identifies itself through a specific user-agent string in HTTP requests. The exact format varies but typically includes “MLBot” or similar identifiers. Checking your server logs for this string reveals whether the crawler has visited your site.
Here’s what to look for in access logs:
- The user-agent string usually follows this pattern: “Mozilla/5.0 (compatible; MLBot/1.0; +http://example.com/mlbot)”. The exact version number and URL may differ. Some variants include additional information about the crawling organization or purpose.
- Server log analysis tools can filter requests by user-agent, making it easy to see how frequently MLBot visits, which pages it accesses, and how much bandwidth it consumes.
- Behavior patterns also help identify ML crawlers. These bots often make rapid sequential requests and may revisit the same pages periodically to record updates. The request rate is usually higher than human visitors but lower than aggressive scrapers.
- IP address ranges can provide additional identification clues, although distributed crawling systems may use rotating IPs, making this method less reliable.
Webmasters should monitor for both identified and unidentified bot traffic. Not all ML crawlers properly identify themselves. Suspicious patterns, like high request rates from non-search engine bots, warrant investigation.
Managing and Blocking MLBot Activity
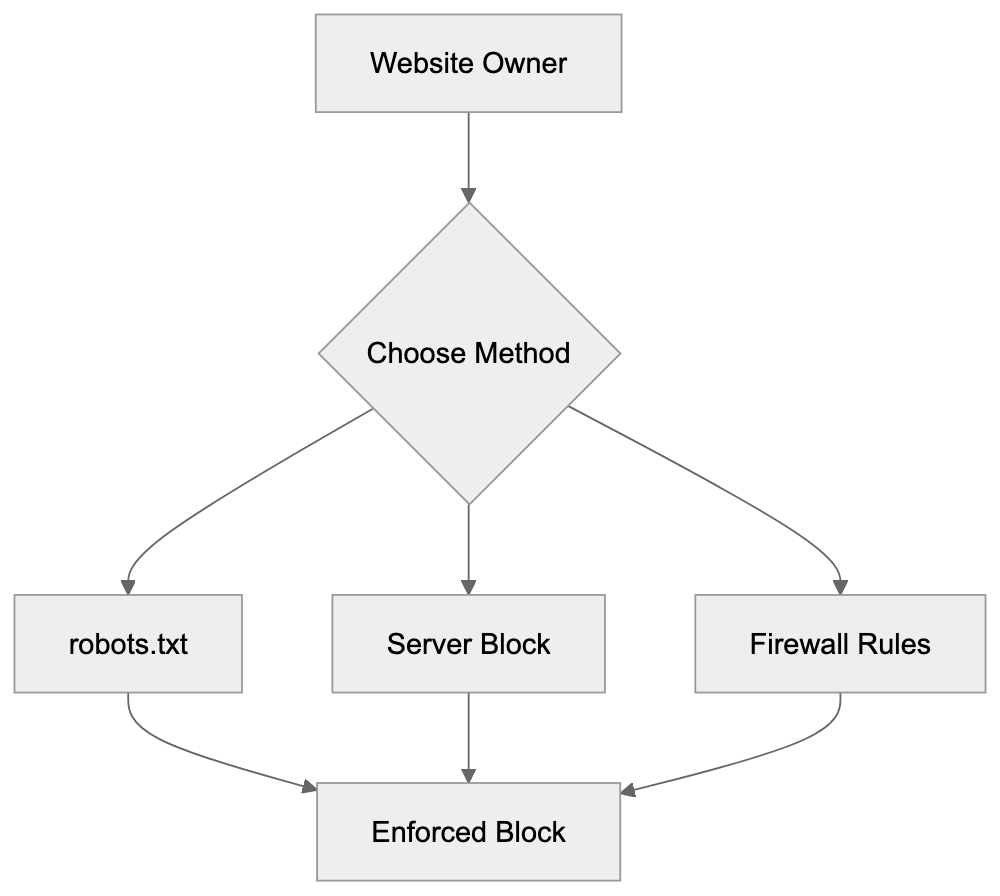
Website owners have several options for controlling MLBot access. The robots.txt file provides the standard method for communicating crawling preferences. Adding MLBot to your disallow rules tells the crawler not to access your site.
Here’s a basic robots.txt example:
User-agent: MLBot
Disallow: /This tells MLBot to stay away from all pages. You can also selectively block specific directories while allowing access to others, but robots.txt relies on voluntary compliance. Poorly configured or malicious crawlers may ignore these directives.
Server-level blocking provides more reliable control. Web server configurations can reject requests based on user-agent strings. Apache servers use .htaccess files for this purpose. Nginx requires modifications to the server configuration.
For Apache, add this to .htaccess:
RewriteEngine On
RewriteCond %{HTTP_USER_AGENT} MLBot [NC]
RewriteRule .* - [F,L]This returns a 403 Forbidden error to MLBot requests. Similar rules work for other bot user-agents you want to block.
Firewall rules offer another blocking layer. Cloud firewalls and CDN services can filter traffic before it reaches your server, reducing bandwidth consumption and server load from unwanted bots.
Some website owners choose to allow MLBot but implement rate limiting. This permits data collection while preventing resource abuse, ensuring the bot doesn’t overwhelm your server with too many simultaneous requests.
Comparing MLBot to Alternative ML Crawlers
Several machine learning crawlers operate on the web today, each with different behaviors, transparency levels, and purposes. Understanding these alternatives helps contextualize MLBot’s role in the AI training data ecosystem.
| Crawler Name | User-Agent Identifier | Primary Purpose | Opt-Out Method | Typical Behavior |
|---|---|---|---|---|
| MLBot | MLBot/version | General ML training | robots.txt, blocking | Moderate crawl rate |
| CCBot | CCBot/version | Common Crawl dataset | robots.txt | Complete crawling |
| GPTBot | GPTBot/version | OpenAI model training | robots.txt | Selective content |
| Google-Extended | Google-Extended | Google AI training | robots.txt | Follows Googlebot patterns |
| anthropic-ai | anthropic-ai | Claude model training | robots.txt | Respectful crawling |
CCBot stands out as one of the most active crawlers, building the Common Crawl dataset, a massive publicly available web archive used by many AI researchers. It visits billions of pages and respects robots.txt directives.
GPTBot, developed by OpenAI, specifically collects data for training ChatGPT and other models. OpenAI provides clear documentation about the bot and offers straightforward blocking instructions, operating with relative transparency about its crawling activities.
MLBot Blocking Methods:
Google-Extended represents Google’s approach to separating search indexing from AI training. Blocking Google-Extended prevents your content from being used in Bard and other Google AI products while still allowing regular Googlebot for search indexing.
Anthropic crawler gathers training data for Claude. Anthropic has published information about responsible crawling practices and respects standard exclusion methods while emphasizing compliance with robots.txt.
MLBot typically falls somewhere in the middle regarding transparency and behavior. It’s less documented than GPTBot or Google-Extended but is more identifiable than some proprietary crawlers. The crawl rate and resource consumption vary depending on the specific setup.
Technical Details for Developers
Developers managing web infrastructure should implement monitoring for ML crawler activity. Log aggregation tools can alert you when crawler traffic spikes or new bot user-agents appear, preventing unexpected bandwidth overages.
API rate limiting applies to ML crawlers just like any other automated traffic. If your site offers an API, implement authentication and rate limits to prevent abuse. Crawlers sometimes target APIs instead of HTML pages because structured data is easier to process.
Some developers choose to serve different content to identified bots. This technique, called cloaking, is generally discouraged for search engines but might be considered for ML crawlers. You could serve minimal content or watermarked text to preserve bandwidth while signaling your preferences.
Content Security Policy headers and other security measures don’t directly block crawlers but can limit what they extract. These headers control how browsers and some automated tools interact with your content.
Website owners concerned about ML training usage should consider adding explicit licensing information. Creative Commons licenses or custom terms of service can state your preferences about AI training use. While enforcement remains challenging, clear licensing creates a documented position.
Monitoring tools like Google Analytics won’t record most bot traffic since bots don’t execute JavaScript. Server-side logging provides the complete picture, with tools like GoAccess or AWStats available to help analyze raw server logs and identify bot patterns.
Legal and Ethical Considerations
The legal landscape around ML crawlers continues to evolve. Current US law generally permits crawling publicly accessible websites, but terms of service violations and potential copyright issues create uncertainty.
Some website owners view ML crawlers as theft of their intellectual property. They argue that using copyrighted content to train commercial AI models without permission or compensation violates their rights. Courts haven’t fully settled these questions yet.
Ethical considerations extend beyond legal requirements. Many content creators feel uncomfortable knowing their work trains AI systems that might compete with them. A photographer’s images used to train image generators or a writer’s articles feeding language models raise fairness questions.
Transparency varies widely among ML crawlers. Some organizations clearly identify their bots and provide opt-out mechanisms, while others operate less openly. This inconsistency makes it difficult for website owners to make informed decisions.
The bandwidth and server resource costs represent another concern. High-traffic websites might spend significant money on infrastructure that serves bot traffic. When bots consume resources to collect data for commercial purposes, questions arise about who should bear these costs.
SEO experts and content marketers face particular challenges. Their content needs visibility for search engines, but they may want to exclude ML training crawlers. The emergence of separate user-agents like Google-Extended helps, but not all crawlers offer this distinction.
Best Practices for Website Owners
Website administrators should develop a clear policy about ML crawler access, considering content type, business model, and philosophical stance on AI training data. This policy guides technical setup decisions.
Regularly review your robots.txt file. Add new ML crawler user-agents as they appear, keeping the file updated with current bot identifiers. Remember, robots.txt is publicly visible so anyone can see which bots you’re blocking.
Monitor your server logs monthly at minimum. Look for new unidentified bots and unusual traffic patterns, setting up alerts for traffic spikes that might indicate aggressive crawling. Early detection prevents resource problems.
Document your decisions and reasoning. If you choose to block ML crawlers, note why and when you implemented blocks. This documentation helps future administrators understand your choices.
Consider the trade-offs carefully. Blocking all ML crawlers might seem appealing but could have unintended consequences. Some research projects and beneficial AI applications rely on this data. Balance your concerns with potential positive uses.
For business websites, consult with legal counsel about terms of service. Explicitly stating that automated scraping for ML training is prohibited creates a stronger position if disputes arise, though enforcement remains challenging.
Communicate with your hosting provider about bot traffic. Some hosts offer bot management tools or can help implement blocking at the network level. Understanding your hosting plan’s bandwidth limits helps avoid overage charges from crawler activity.
Future of ML Crawlers and Data Collection
The ML crawler landscape will likely become more complex as AI development accelerates. More companies will deploy crawlers to gather training data, increasing activity that puts additional pressure on web infrastructure and intensifies copyright debates.
Regulatory changes might reshape how ML crawlers operate. The European Union and other jurisdictions are considering AI-specific regulations that could include requirements for transparency in training data collection or compensation mechanisms for content creators.
Technical standards for crawler identification may appear. Industry groups might develop best practices that responsible AI companies follow, making it easier for website owners to manage crawler access.
Some experts predict a shift toward licensed training data. Companies might negotiate directly with major content providers rather than relying on web crawling. This would address some ethical and legal concerns but could limit diversity in training datasets.
The tension between open access to information and content creator rights will continue. Website owners want control over how their content is used, and AI developers need access to varied data. Finding a balance between these interests remains an ongoing challenge.
Conclusion
MLBot represents one part of the broader machine learning data collection ecosystem. Understanding how these crawlers work helps website owners make informed decisions about access. The bot serves a clear purpose in gathering training data but raises valid questions about resource usage and content rights.
Website administrators have effective tools for managing MLBot activity. From robots.txt entries to server-level blocking, multiple methods exist for controlling access. The right approach depends on your specific situation and priorities.
The machine learning industry’s data needs won’t disappear. Crawlers like MLBot will continue operating as AI development progresses. Staying informed about these tools and implementing appropriate controls helps you maintain agency over your content and resources. Whether you choose to allow or block ML crawlers, making an active decision beats accepting the default by ignorance.
Frequently Asked Questions
What is the main purpose of MLBot?
MLBot is designed primarily for collecting training data for machine learning models. It gathers diverse datasets from websites to support the training of AI systems, ensuring access to varied types of content that may not be found in publicly available datasets.
How do I identify if MLBot has crawled my website?
You can identify MLBot by checking your server logs for its specific user-agent string, which typically includes "MLBot". Analyzing these logs will help you see how often it visits your site and which pages it accesses.
What measures can I take to block MLBot?
Website owners can block MLBot by using a robots.txt file to disallow its access or by implementing server-level rules, such as using .htaccess files on Apache servers. Additionally, applying firewall rules can help filter out unwanted crawler traffic effectively.
Are there legal implications of MLBot crawling my site?
While current US law generally allows crawling publicly accessible websites, the legality can become complex, especially regarding copyright and terms of service violations. Website owners may feel that their intellectual property rights are compromised if their content is scraped for commercial AI training.
Can I limit the impact of MLBot on my server resources?
Yes, you can implement rate limiting for MLBot to prevent it from overwhelming your server with requests. This way, you allow some data collection while controlling resource consumption and maintaining site performance.
What ethical concerns should I be aware of regarding MLBot?
Ethical concerns revolve around content creators' rights and the perception that their work is used to train commercial AI systems without consent or compensation. Transparency in how data is sourced and efforts to respect creators' preferences are crucial in addressing these issues.
How is MLBot different from other ML crawlers?
MLBot differs from other crawlers in its primary focus on general machine learning data collection. While some crawlers have specific purposes, like building large-scale datasets or adhering to strict ethical guidelines, MLBot operates within a legal gray area regarding data usage and site resource consumption.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.