Understanding MojeekBot: UK's Independent Search Crawler
Complete guide to MojeekBot covering UK origins, independent search indexing, functionality, and privacy-focused approach compared to alternatives.
What MojeekBot Is and Why It Matters
MojeekBot is the web crawler that powers Mojeek, a UK-based independent search engine. As a rare independent search crawler, MojeekBot builds its index from scratch, unlike other engines relying on Google or Bing. This makes it a key player in decentralized search indexing. MojeekBot visits websites, reads their content, and adds this information to Mojeek’s search database. For web developers and SEO experts, MojeekBot is a new search bot that operates differently from major tech crawlers. Small business owners can benefit by gaining search visibility outside the Google ecosystem. The privacy search approach ensures no tracking of user searches, catering to ethical alternatives sought by content marketers. MojeekBot signifies a shift toward independent crawlers and data independence.
The Purpose Behind MojeekBot
Search engines like Mojeek exist to challenge the dominance of major players like Google, which holds over 90% of the global search market share. This concentration affects website owners, users, and the open web. When one company dominates search, it influences what information people find and how websites adapt their content. MojeekBot’s mission is to offer an independent search index while avoiding integration with Google’s or Microsoft’s systems. This independence fosters competition and offers privacy-respecting options, as Mojeek does not track users or build advertising profiles. Website owners gain a new path to discovery beyond major search engines. MojeekBot aims to preserve the open web and decentralize search. For developers and SEO professionals, understanding MojeekBot can unlock new traffic and indexing opportunities.
How MojeekBot Actually Works
MojeekBot Crawling Process:
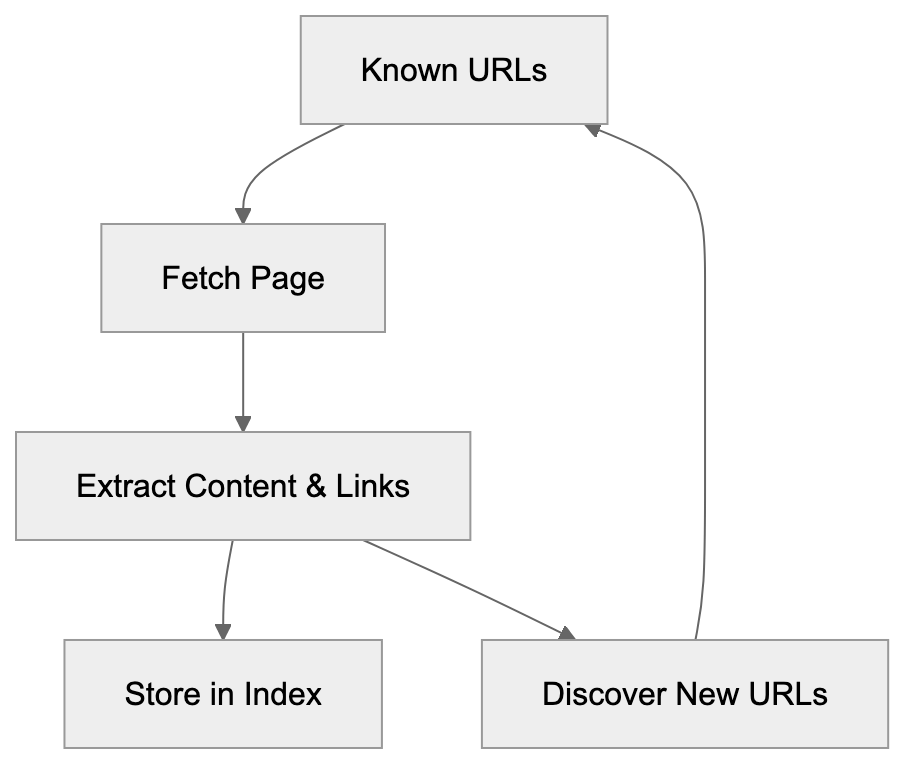
MojeekBot operates like other web crawlers but with distinct features. The bot starts with known URLs and follows links to discover new content. It reads HTML, extracts text and links, and stores this in Mojeek’s database. The bot respects robots.txt files and crawl-delay directives, giving website owners control over its access. MojeekBot identifies itself clearly in server logs with the user agent string “MojeekBot”. Primarily operating in the UK and Europe, it doesn’t use JavaScript rendering by default, similar to older web crawlers. HTML-source content is necessary for proper indexing. Crawl frequency varies by site size, update frequency, and crawl budget allocation. Popular sites get crawled more frequently. MojeekBot focuses purely on indexable content and does not gather personal data.
Who Uses Mojeek and Why
Mojeek attracts users seeking search results free from surveillance or filter bubbles. It doesn’t track searches or clicks, appealing to privacy-conscious individuals and organizations with strict data policies. Internet censorship concerns also drive usage in some regions. Marketing professionals use Mojeek to evaluate content performance in a non-personalized environment. SEO experts monitor MojeekBot to ensure their sites’ discoverability. Some businesses optimize specifically for Mojeek to tap into its user base and diversify traffic sources. The search engine is popular in the UK and parts of Europe due to strict data privacy regulations. Small business owners sometimes find improved visibility on Mojeek compared to Google. Content marketers researching search diversity include Mojeek in their multi-platform strategies. Mojeek also offers search API services for developers to integrate privacy search features into their applications.
Key Facts About MojeekBot
Founded in 2004, Mojeek is one of the earliest independent search engines. Based in the UK, it maintains full control over its search technology. MojeekBot has indexed billions of pages, although the exact number is less than Google’s index. Operating under a clear privacy policy, it prohibits personal data collection from websites. Mojeek is ad-free, relying on alternative revenue models. It uses proprietary ranking algorithms, not licensing from larger competitors. MojeekBot’s user agent string is “Mozilla/5.0 (compatible; MojeekBot/0.6; +https://www.mojeek.com/bot.html)”. Website owners can manage MojeekBot through robots.txt protocols. The crawler respects noindex tags and standard SEO directives. Mojeek avoids data-sharing agreements with ad networks or tech giants. The search index updates continuously as MojeekBot discovers and re-crawls pages. While response time to new content varies, key pages usually get indexed within days or weeks.
Comparing MojeekBot to Alternative Independent Crawlers
Several independent crawlers, each with unique approaches, operate alongside MojeekBot. Understanding these alternatives aids web developers and SEO experts in prioritizing them and optimizing sites.
Independent Search Ecosystem Comparison:
| Crawler | Origin | Index Size | Key Feature | Privacy Focus |
|---|---|---|---|---|
| MojeekBot | UK | Billions of pages | Fully independent index | Very high |
| YaCy Bot | Germany | Decentralized network | Peer-to-peer search | Very high |
| Gigablast | USA | Billions of pages | Open source technology | Medium |
| RightDAO | France | Millions of pages | European focus | High |
| Seekport | Multiple | Aggregated results | Meta-search approach | Medium |
MojeekBot stands out by building a truly independent index, unlike meta-search engines. YaCy employs a decentralized peer-to-peer approach, less consistent for SEO. Gigablast offered open-source technology but ended in 2022. RightDAO focuses on European content and privacy compliance. Seekport ceased in 2009 and aggregated results from multiple sources. MojeekBot offers reliable independent indexing beyond the Google-Bing duopoly. Its clear policies and consistent operation make it preferable to some alternatives. Privacy-focused users favor Mojeek for its independence, as it avoids querying other search providers prone to tracking.
How to Work With MojeekBot
Privacy-Focused Data Flow:
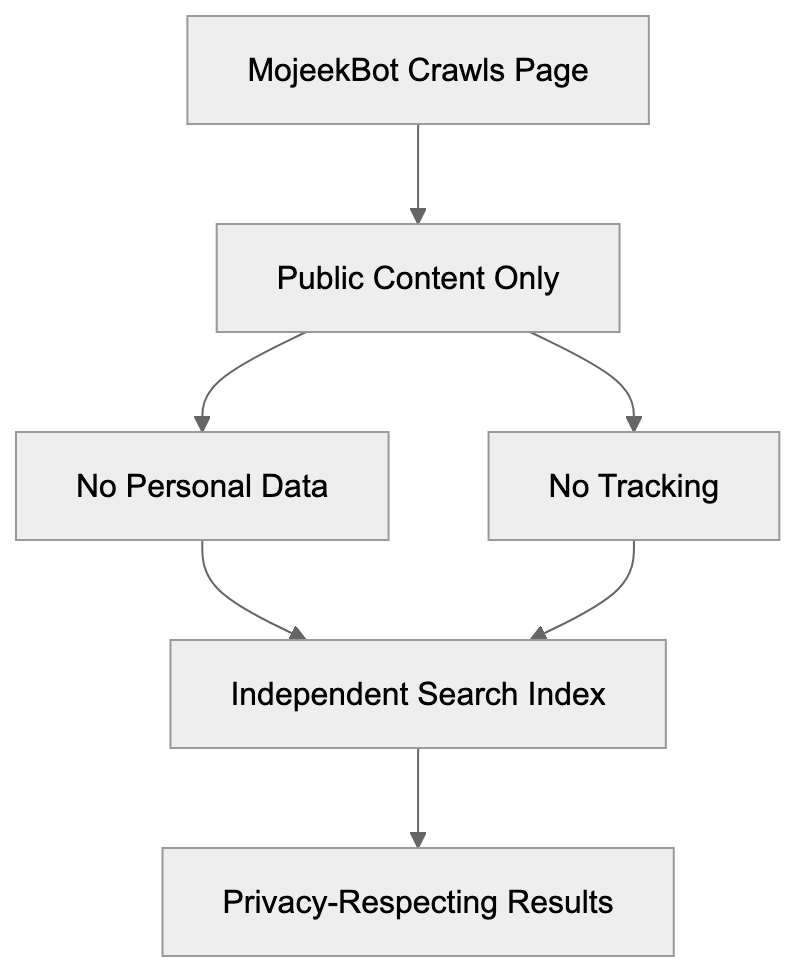
To optimize for MojeekBot, use standard SEO practices with specific considerations. Ensure your robots.txt file permits MojeekBot access. Identify as “MojeekBot” in user agent strings. Ensure vital content is available in HTML, as the bot doesn’t execute JavaScript by default. Utilize clear site structure and XML sitemaps to assist the crawler in finding your pages. Submit your sitemap through available webmaster tools. Ensure your server handles crawler requests without timing out or blocking. MojeekBot respects crawl-delay directives for servers needing slower access. Use standard meta tags and structured data to clarify content. While Mojeek employs proprietary algorithms, structured signals aid understanding. Monitor server logs to track MojeekBot visits. This data informs crawl budget and indexing status. Focus on quality content that serves user needs, as Mojeek values straightforward helpful content over algorithm gaming.
Privacy and Data Handling
Mojeek’s privacy approach extends throughout its operations, including MojeekBot’s data collection. The bot doesn’t gather personal information or track user behavior. When visiting a page, MojeekBot reads public content and avoids accessing private data. The search engine doesn’t build ad profiles or sell data, unlike major engines integrating crawler data with tracking systems. For website owners, MojeekBot respects visitor privacy. Mojeek avoids the behavioral ad ecosystem funding most search engines. Users experience a neutral search environment without personalized results influenced by history. Developers working with sensitive content appreciate MojeekBot’s strict data handling. Operating under GDPR and European regulations, Mojeek is ideal for privacy-conscious audiences. Understanding this appeals to marketers targeting such users.
Technical Specifications for Developers
MojeekBot supports standard HTTP and HTTPS protocols and follows 301 and 302 redirects. It respects canonical tags to identify duplicate content’s preferred versions. The bot reads meta robots tags like noindex, nofollow, and noarchive. Its IP addresses primarily stem from UK and European data centers. Verify legitimate requests via reverse DNS lookups against published IP ranges. The user agent string clearly identifies the crawler, providing a link to documentation. MojeekBot doesn’t render JavaScript, challenging single-page and JavaScript-heavy sites. Server-side rendering or static generation ensures proper indexing. The crawler handles common CMSs like WordPress, Drupal, and Joomla without special settings. It processes XML sitemaps detected via robots.txt or common paths. Structured data is processed, though schema support specifics aren’t fully documented. Respecting bandwidth limits, MojeekBot won’t overwhelm servers. Typical crawl rates depend on site size and importance but remain reasonable.
Future of Independent Search Crawling
Independent search crawlers face opportunities and challenges ahead. MojeekBot and similar entities counterbalance major search monopolies with fewer resources. The rise of privacy regulations benefits privacy-focused search alternatives as users grow aware of mainstream engines’ surveillance concerns. This awareness drives adoption of options like Mojeek, despite the technical challenge of crawling the entire web. Google and Bing’s billion-dollar infrastructure presents a resource gap. Independent indexes may remain smaller and potentially less complete. Yet for developers and SEO professionals, supporting independent crawlers is wise as part of a diversified strategy. Sole reliance on Google creates vulnerability if its algorithms change or traffic from it wanes. MojeekBot offers alternative indexing that could gain importance as search evolves. Small business owners benefit from competition provided by independent engines, reducing dependence on a single platform. Future search landscapes will likely blend dominant players with smaller independent alternatives.
End
MojeekBot is an essential part of independent search infrastructure, operating outside the Google-Bing duopoly. The UK-based search bot builds its own index while respecting user privacy and website preferences. By understanding MojeekBot, web developers can ensure their content is discovered through multiple channels. SEO experts can check non-personalized rankings and reach privacy-conscious users. Small business owners gain an alternative path to search visibility. Marketing professionals can learn from the growing independent search ecosystem. Using standard protocols, MojeekBot offers a privacy-focused alternative to surveillance-based search. As the web evolves, multiple independent crawlers like MojeekBot will be pivotal in maintaining an open and varied internet. Technical setup and content improvement support these alternatives, contributing to a healthier search ecosystem for everyone.
Frequently Asked Questions
How can I ensure my website is optimized for MojeekBot?
To optimize for MojeekBot, ensure your robots.txt file allows its access, identify it in user agent strings, and provide essential content in HTML format. A well-structured website with clear XML sitemaps also aids the crawler in finding and indexing your pages.
What are the privacy benefits of using Mojeek compared to major search engines?
MojeekBot does not track user behavior or collect personal data, creating a neutral search environment free from personalized results. This focus on privacy is ideal for users concerned about surveillance and data profiling by larger search engines.
Can Mojeek help small businesses improve their search visibility?
Yes, small businesses can benefit from Mojeek's independent search index, often finding improved visibility compared to larger platforms. By utilizing Mojeek, they can diversify their traffic sources and reach new audiences without relying solely on Google.
How does MojeekBot differ from other independent crawlers?
MojeekBot builds a fully independent index, unlike meta-search engines that rely on other sources. Additionally, it prioritizes user privacy and operates under strict data handling policies, offering a unique position in the independent search ecosystem.
Is there a specific audience that prefers using Mojeek?
Mojeek attracts users who prioritize privacy and wish to avoid the filter bubbles created by major search engines. This includes privacy-conscious individuals, organizations with strict data policies, and users in regions experiencing internet censorship.
How frequently does MojeekBot crawl websites?
Crawl frequency depends on various factors, including site size, update frequency, and crawl budget allocation. Typically, more popular sites are crawled more often, while newer or less prominent sites may experience longer indexing times.
What should developers know about working with MojeekBot?
Developers should be aware that MojeekBot respects standard SEO practices, such as canonical tags and meta robots tags. Additionally, it does not render JavaScript, so ensuring proper server-side rendering or static pages is crucial for effective indexing.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.