Omgilibot: Webz.io's Data Resale Crawler Explained
Learn about Omgilibot by Webz.io, its data collection role, user-agent strings, and importance in data resale and licensing models.
What is Omgilibot and Why Does It Matter
Omgilibot is a web crawler operated by Webz.io, formerly known as Webhose.io. This bot, also termed the “omgili bot,” plays a crucial role in Webz.io’s data resale crawler ecosystem. It collects data from websites, forums, blogs, and other online sources. The purpose is straightforward: Webz.io collects this data and sells it to businesses for analysis, research, or AI training, a model known as data-as-a-service. By using this model, companies can access structured web data without the need for their own crawlers. Omgilibot powers this business model by gathering content from millions of web pages daily.
For website owners and developers, understanding this web crawler is vital since it might be presently accessing your site. The collected data can include post content, comments, metadata, and more, which Webz.io then packages into datasets and APIs for purchase. While data collection through bots is common, it raises questions about consent, bandwidth usage, crawl blocking, and proper attribution.
Understanding Webz.io’s Data-as-a-Service Business Model
Omgilibot’s Data Collection Process:
Webz.io functions as a data provider, selling access to web content. Instead of companies building their own web scraping infrastructure, they purchase data from Webz.io. The company crawls billions of web pages, structuring this information into usable formats. Their customers range from market research firms to financial institutions, AI companies, and cybersecurity teams, using the data for sentiment analysis, trend monitoring, competitive intelligence, and training machine learning models.
The pricing model typically involves subscriptions or API access fees based on data volume and features needed. Webz.io claims to crawl over 80 million new posts daily from various sources, including news sites, blogs, forums, and discussion boards. By processing this data, they save customers from the technical complexities and legal considerations of running their own Webz.io crawlers. The business model relies entirely on bots like Omgilibot to continuously gather fresh content from across the web. Without such constant data collection, Webz.io would have no product to sell.
How to Identify Omgilibot in Your Server Logs
Omgilibot is easily identifiable through specific bot user-agent strings when accessing websites. The most common user-agent string is “omgilibot/1.0 (+http://webz.io/bot)” or variations including “omgili-bot.” You can find these requests in your web server access logs. The bot typically respects standard crawling protocols and identifies itself clearly, making it easier to track compared to some scrapers that disguise themselves.
Webz.io Business Model:

The IP addresses used by Omgilibot can vary because Webz.io likely operates from multiple servers and locations. To verify traffic from Webz.io, check reverse DNS lookups on the IP addresses. Legitimate Webz.io crawlers should resolve to their infrastructure. The crawl frequency depends on your site’s update schedule and the perceived value of your content. High-traffic sites or frequently updated sources might experience daily or even hourly visits, while smaller sites might be crawled weekly or monthly. Understanding these patterns helps you decide whether to allow or block the data resale crawler.
Blocking Omgilibot: Methods and Considerations
Website owners have options to block Omgilibot if they don’t want content collected for resale. The most common method is using a robots.txt file. To block the crawler, add:
User-agent: omgilibot
Disallow: /While this file informs Omgilibot not to crawl any part of your site, it is merely a suggestion and compliance isn’t mandatory. More effective methods include blocking at the server level using .htaccess files or server configurations to restrict specific user-agent strings or IP ranges associated with Webz.io. Some content management systems and security plugins also offer bot blocking features.
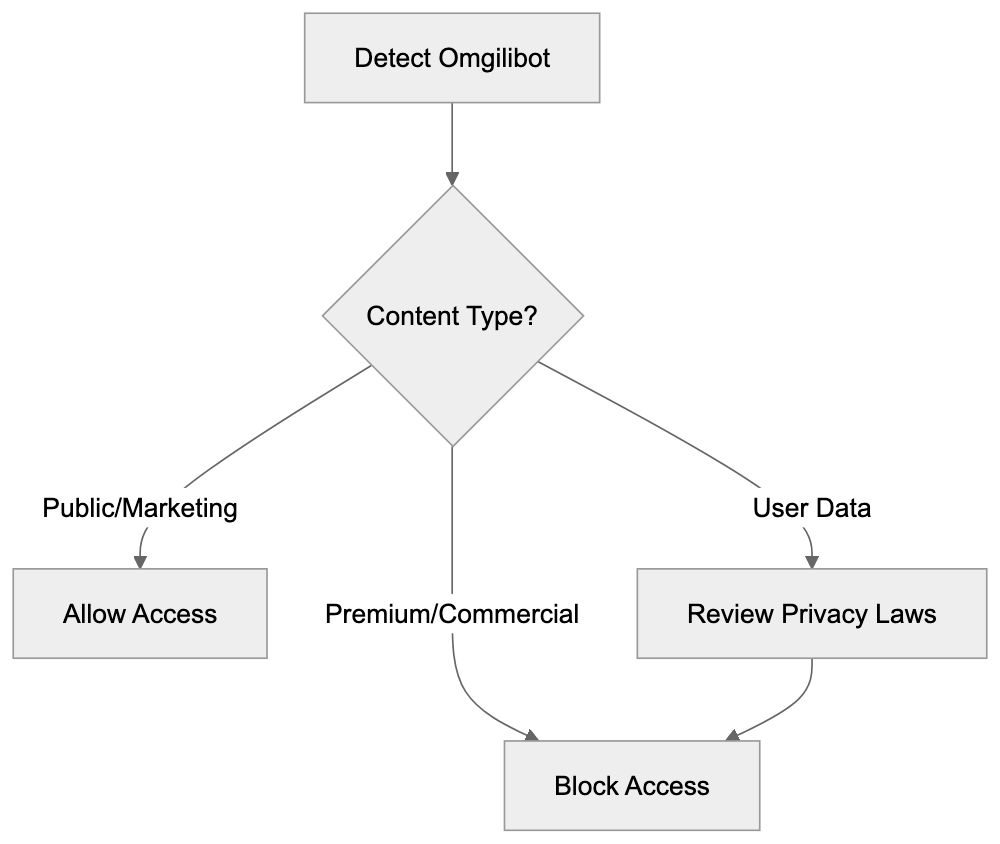
Before blocking Omgilibot, consider the tradeoffs. Public websites or blogs might benefit from increased visibility within Webz.io’s database. Some organizations want public statements and press releases included in such datasets. However, concerns about data licensing, bandwidth costs, or unauthorized content repackaging could justify blocking. Commercial sites selling premium content have strong reasons to block such data resale crawlers. The decision depends on your specific situation and content strategy.
Comparing Omgilibot to Other Data Collection Crawlers
Omgilibot operates in a competitive space alongside other data resale crawlers. Here’s how it compares to major alternatives:
| Crawler | Company | Primary Use | Respectfulness | Data Focus |
|---|---|---|---|---|
| Omgilibot | Webz.io | Data resale, APIs | Identifies clearly | Blogs, forums, news |
| CCBot | Common Crawl | Open datasets | Respects robots.txt | General web content |
| GPTBot | OpenAI | AI training | Blockable via robots.txt | Text content |
| Bytespider | ByteDance | Search, AI training | Mixed reports | General web |
| Amazonbot | Amazon | Search, product data | Generally respectful | Product pages, reviews |
While Webz.io distinguishes itself by offering commercial data rather than free public datasets like Common Crawl, its data is sold via subscriptions and API access, unlike open initiatives. Omgilibot collects content for diverse business applications, unlike bots like GPTBot that focus on AI training data. The key distinction with search engine crawlers like Googlebot is the purpose—data resale crawlers like Omgilibot sell packaged content to third parties, rather than indexing for search visibility. This distinction is crucial when deciding on crawl permissions. Each crawler’s compliance with blocking requests and business model can vary.
Bot Blocking Decision Flow:
Data Licensing and Legal Considerations
Navigating the legal landscape of web crawling and data resale can be complex. Webz.io operates under the assumption that publicly accessible web content can be collected and redistributed. However, legality and ethics of scraping vary by jurisdiction. Website terms of service often explicitly prohibit automated data collection or commercial reuse. Legal cases, like hiQ Labs v. LinkedIn in the United States, have explored scraping legality, often favoring access to public data. Still, legal interpretations and implications continue to evolve globally.
In Europe, GDPR adds another layer of complexity when personal data is involved. Webz.io claims to offer GDPR-compliant options, but website owners should be aware of their own legal obligations. If your site features user-generated content or personal information, selling that data without consent could breach privacy regulations. While the robots.txt protocol indicates crawling preferences, it has limited legal authority. Some argue that violating robots.txt could constitute unauthorized access under specific laws. To protect content from unauthorized resale, website owners should explicitly state terms of use, implement technical blocks, and consider legal action if boundaries are violated. Companies using data from services like Webz.io should ensure it was collected legally and adheres to relevant regulations.
Alternative Approaches to Web Data Collection
Businesses seeking web data have options beyond purchasing from data resale services like Webz.io. Building custom scrapers offers more control but requires technical expertise and infrastructure, including server management and data storage. This approach suits companies with specific data needs and technical capabilities.
Open datasets, like Common Crawl, provide free access to extensive web data, though they demand additional processing to extract useful information. Academic researchers often utilize this route. Some platforms, like Twitter or Reddit, offer API access with structured data and clear terms of service, although these may carry costs or rate limits.
Some businesses establish data partnerships or licensing agreements directly with content publishers, ensuring legal compliance at a higher cost than scraping services. Manual data collection or crowdsourcing can work for smaller datasets where automation isn’t warranted. Each approach differs in cost, legality, and technical demands. The choice hinges on data volume needs, budget, technical capabilities, and legal risk considerations.
Making Informed Decisions About Crawler Access
Website owners should actively manage crawler access to their content. Start by reviewing server logs to identify visiting bots. Many sites are unaware of the variety of crawlers accessing their pages daily. Create a robots.txt file if you don’t have one, explicitly listing allowed and disallowed bots. Avoid assuming defaults.
Consider your content type and business model. Public information sites might welcome broader indexing, while e-commerce and membership sites with premium content might be more selective. Monitor bandwidth usage since aggressive crawlers can impact performance and increase hosting costs. Blocking bots that consume excessive resources makes sense, regardless of other factors.
Stay informed about how data services use collected content. Read documentation from companies like Webz.io to understand their practices and check for opt-out mechanisms beyond robots.txt. Some data providers maintain exclusion lists for sites requesting removal. Document your decisions and policies to help address any inquiries about your content appearing in commercial datasets.
For businesses purchasing web data, verify the data provider’s collection methods and legal compliance. Inquire about their respect for robots.txt, terms of service compliance, and data licensing. Using data collected illegally can create liability, even if you weren’t involved in the scraping.
Conclusion
Omgilibot is Webz.io’s primary tool for collecting web content packaged into commercial data products. It operates openly with identifiable user-agent strings and typically respects standard crawling protocols. The data-as-a-service model allows companies to access structured web data without building their own scraping infrastructure. However, this business model raises questions for website owners about consent, bandwidth usage, and content licensing.
Understanding how Omgilibot functions aids informed decisions about allowing or blocking access. Comparisons with other data collection crawlers show that Webz.io is part of a broader industry ecosystem. Legal considerations around crawling remain complex and vary by jurisdiction. Website owners should manage crawler access through robots.txt, server-level blocking, and clear terms of service. Businesses using such data services should ensure legal compliance. Whether you’re protecting your content from unauthorized resale or evaluating data providers for business intelligence, knowing how crawlers like Omgilibot operate is increasingly crucial in the data-driven economy.
Frequently Asked Questions
How can I know if Omgilibot is accessing my website?
You can identify Omgilibot in your server logs by looking for its specific user-agent strings, such as "omgilibot/1.0 (+http://webz.io/bot)". Additionally, tracking its IP addresses through reverse DNS lookups can help confirm the presence of this bot on your site.
What are my options for blocking Omgilibot?
You can block Omgilibot using a robots.txt file by specifying appropriate directives, like when you add "User-agent: omgilibot\nDisallow: /". For more effective control, consider configuring server-level blocks using .htaccess files or IP restrictions.
What are the potential implications of blocking Omgilibot?
Blocking Omgilibot may reduce your visibility in commercial datasets, which could affect traffic to your website if your content would be valuable for data consumers. However, if you have concerns about unauthorized content resale or bandwidth usage, blocking might be a prudent choice.
Does Omgilibot always respect robots.txt rules?
Omgilibot identifies itself clearly and typically follows standard crawling protocols, including those outlined in robots.txt files. However, it is important to note that compliance with these guidelines is not legally mandatory for crawlers.
Are there legal risks in using data collected by Omgilibot?
Yes, there are legal implications when using data collected by Omgilibot, particularly pertaining to privacy laws such as GDPR. Ensure that the data you are acquiring is obtained in compliance with legal standards and does not violate any terms of service or privacy rights.
What should I consider before purchasing data from Webz.io?
Before purchasing data from Webz.io, inquire about their data collection methods, compliance with robots.txt, and adherence to local regulations. Understanding how they handle licensing and data rights is crucial to avoid potential legal entanglements.
How does Omgilibot compare to other crawlers in the industry?
Omgilibot differs from crawlers like Common Crawl and GPTBot by focusing on data resale rather than providing open datasets or being solely dedicated to AI training. Each crawler has its own terms of compliance, data focus, and intended use, making it essential to understand these distinctions when deciding on crawler access.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.