Understanding SeznamBot: AI-Driven Web Crawler Guide
Learn about SeznamBot, the AI-enhanced web crawler from Seznam.cz. Covers purpose, features, user-agent strings, and blocking options.
What is SeznamBot and Why It Matters
SeznamBot is the web crawler used by Seznam.cz, the largest Czech search engine. This AI web crawler scans websites to index content for the Czech Republic search results. Web crawlers like SeznamBot are essential tools enabling search indexing by finding and cataloging web pages. This helps users access relevant information when they search online.
Though most are familiar with Google’s crawler, regional search engines like Seznam.cz maintain their own search engine bots to better serve local markets. SeznamBot emphasizes Czech language content and websites pertinent to Czech users. For website owners and developers targeting Czech audiences, understanding how SeznamBot operates is crucial for search visibility in this market. The crawler uses AI technologies for better content understanding, quality evaluation, and determining what appears in search results.
Understanding Web Crawlers and Their Purpose
Web crawlers are automated programs systematically browsing the internet. They visit web pages, read content, follow links, and relay this information to their search engine’s database. Without crawlers, search engines wouldn’t comprehend what content exists online or how to rank it.
SeznamBot operates like other search engine crawlers. It begins with known URLs, follows links, downloads HTML content, processes JavaScript, and extracts text, images, and metadata. This data is analyzed and stored in Seznam’s index, powering their search engine results.
Web Crawler Operation Flow:
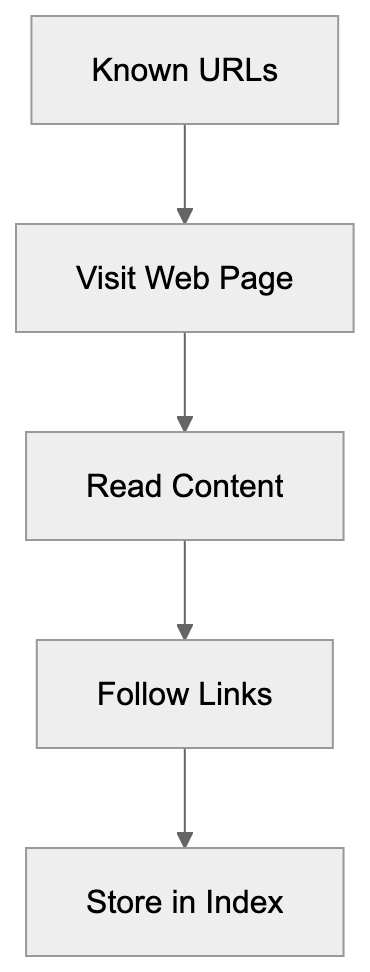
SeznamBot’s AI helps better understand content context than older methods. Modern crawlers must evaluate content quality, detect spam, understand user intent, and identify duplicate content. Seznam has invested in making their bot smarter to provide better results for Czech users.
How SeznamBot Identifies Itself
All web crawlers identify themselves through a user-agent string, indicating to your web server the type of visitor. SeznamBot uses specific user-agent strings visible in server logs.
The main SeznamBot user-agent string looks like this:
Mozilla/5.0 (compatible; SeznamBot/4.0; +http://napoveda.seznam.cz/seznambot-intro/)
Seznam operates several different bots, each with its own user-agent string:
SeznamBot Identification Process:

- SeznamBot - Main crawler for web search indexing
- SklikBot - Crawler for their advertising platform Sklik
- Snapshot - Takes screenshots of web pages for search results
- ContentBot - Analyzes page content quality
The user-agent string includes a link to Seznam’s documentation to verify the bot’s legitimacy. This is crucial as some malicious bots pose as legitimate crawlers. You can verify a real SeznamBot by performing a reverse DNS lookup on the IP address, ensuring it resolves to a seznam.cz domain.
How Businesses and Website Owners Work with SeznamBot
Website owners aiming for inclusion in Seznam search results must allow SeznamBot to crawl their sites. It respects standard web protocols like robots.txt files, dictating which parts of a site crawlers can access.
For businesses targeting Czech customers, optimizing for SeznamBot is sensible, as Seznam holds about 10-15% of Czech Republic search traffic. While Google dominates globally, many Czech users prefer Seznam for local searches, news, and services.
Webmasters can submit sites to Seznam via their webmaster tools, featuring similar functionalities to Google Search Console. They can monitor crawl activity, resolve indexing issues, and observe site performance in search results. Seznam offers guidelines on content structuring for better indexing.
SeznamBot respects meta tags like noindex and nofollow, allowing you to specify which pages to skip in robots.txt or HTML. Sites primarily serving non-Czech audiences often block SeznamBot to conserve server resources, as the traffic benefit is minimal.
Blocking or Controlling SeznamBot Access
Several methods control how SeznamBot interacts with your website, with robots.txt being the most common. Place it in your site’s root directory.
To block SeznamBot entirely, insert these lines in your robots.txt:
User-agent: SeznamBot
Disallow: /To block only specific sections while allowing the rest:
User-agent: SeznamBot
Disallow: /admin/
Disallow: /private/Use meta tags in individual page headers to prevent indexing:
<meta name="robots" content="noindex, nofollow">Or specifically for SeznamBot:
<meta name="SeznamBot" content="noindex, nofollow">Some website owners employ server-level blocking by checking the user-agent string and issuing specific HTTP status codes. A 403 Forbidden or 429 Too Many Requests status informs the bot it cannot access the resource, though robots.txt is generally preferred as it’s clearer and follows web standards.
Crawler Comparison Overview:
Rate limiting is another factor. If SeznamBot crawls too aggressively, impacting server performance, you can request a slower crawl rate via Seznam’s webmaster tools. Most legitimate search bots respect these requests and adjust their crawling speed.
SeznamBot Compared to Other Search Engine Crawlers
Different search engines use varying crawlers with distinct capabilities and focuses. Here’s how SeznamBot compares to other major web crawlers:
| Crawler | Search Engine | Primary Region | AI Features | Crawl Frequency |
|---|---|---|---|---|
| SeznamBot | Seznam.cz | Czech Republic | Content quality analysis, spam detection | Medium, focuses on Czech sites |
| Googlebot | Global | Advanced NLP, image recognition, quality scoring | High, frequent recrawling | |
| Bingbot | Microsoft Bing | Global | AI-powered ranking, content understanding | Medium to high |
| YandexBot | Yandex | Russia, CIS countries | Machine learning for relevance, language processing | High in target regions |
| DuckDuckBot | DuckDuckGo | Global | Privacy-focused, minimal tracking | Lower frequency |
SeznamBot is specifically improved for Czech language content, understanding local context better than global crawlers. It recognizes Czech grammar, slang, and regional variations. The bot also prioritizes Czech domains and local businesses.
Compared to Googlebot, SeznamBot crawls less frequently and covers fewer total pages since it focuses on a smaller market. However, for Czech-specific content, SeznamBot may provide better local visibility than Google.
The crawler’s AI capabilities include spam detection, content quality evaluation, and understanding semantic relationships, helping Seznam filter low-quality content and rank useful pages higher. While SeznamBot may not be as advanced as Google’s systems, it continues to improve with regular updates.
Technical Considerations for Developers
Developers should consider several technical factors concerning SeznamBot. The crawler can process JavaScript but may not execute it as fully as modern browsers. If your site heavily relies on JavaScript for content rendering, ensure important content is in the initial HTML or use server-side rendering.
SeznamBot follows redirects but issues may arise with excessive redirect chains. Keep redirects to one or two hops maximum. The bot respects canonical tags, aiding in preventing duplicate content issues if the same content appears at multiple URLs.
Page load speed is important to SeznamBot, just as for user experience. Improve performance by optimizing images, minimizing CSS and JavaScript, and using caching effectively.
Structured data markup helps SeznamBot better understand your content. While Seznam doesn’t support all schema types like Google, basic markup for articles, products, and local businesses can enhance content appearance in search results.
For sites with numerous pages, XML sitemaps aid SeznamBot in finding content more effectively. Submit your sitemap through Seznam’s webmaster tools and keep it updated with page additions or removals. Your sitemap should list important URLs and indicate change frequency.
HTTPS is important for all search engines, including Seznam. Sites employing secure connections may receive ranking benefits. SeznamBot crawls both HTTP and HTTPS but favors the secure version.
Regional Focus and Market Position
Seznam.cz launched in 1996, becoming the dominant search engine in the Czech Republic before Google’s market entry. While Google has gained a significant share globally, Seznam remains a key player in Czech search.
The search engine offers more than web search, like email, maps, news aggregation, and other services popular with Czech users, retaining users who might otherwise entirely switch to Google.
SeznamBot’s regional focus means it crawls Czech websites more thoroughly than global crawlers. Local business websites, Czech news sites, and community forums often receive better coverage from SeznamBot. It understands Czech-specific TLDs like .cz and prioritizes them properly.
For international businesses expanding into Czech markets, allowing SeznamBot access and optimizing for Seznam search can enhance local visibility. The search engine’s user base is loyal, valuing local content and services.
Seznam has invested in AI and machine learning to keep their search quality competitive, employing local engineers understanding Czech language and market details, offering advantages in serving local searches.
Privacy and Data Collection
Like other search engine crawlers, SeznamBot collects publicly available web content to build its search index. The bot reads page content, metadata, and follows links but doesn’t interact with forms or login systems unless specifically configured to.
Seznam operates under European data protection regulations, including GDPR. The company has published privacy policies explaining data collection and usage. Concerned website owners can use robots.txt or meta tags to control what SeznamBot accesses.
The crawler respects the noarchive meta tag, preventing Seznam from caching copies of your page. Use it if you don’t want Seznam to store snapshots of your content:
<meta name="robots" content="noarchive">Seznam doesn’t share raw crawl data with third parties, using it internally to power their search engine and related services. Their privacy stance emphasizes local data storage and European regulation compliance.
Conclusion
SeznamBot is the web crawler for Seznam.cz, the leading Czech search engine. Understanding how this AI web crawler works is vital for anyone targeting Czech audiences online. The crawler identifies itself through specific user-agent strings and respects standard web protocols for access control.
Website owners can manage SeznamBot through robots.txt files, meta tags, and webmaster tools from Seznam. While it operates similarly to other search bots, its regional focus and Czech language improvements make it particularly crucial for local market visibility. Developers should ensure their sites are accessible to SeznamBot for inclusion in Seznam search results.
Compared to global crawlers like Googlebot, SeznamBot has a narrower focus but a deeper understanding of Czech content and user needs. It continues to improve with AI enhancements for content quality evaluation and spam detection. For businesses serving Czech markets, optimizing for SeznamBot alongside other search engines offers the best overall search visibility.
Frequently Asked Questions
What should I do to optimize my website for SeznamBot?
To optimize for SeznamBot, ensure your site is accessible by allowing it to crawl your pages. Utilize the robots.txt file to manage access, submit your sitemap through Seznam's webmaster tools, and follow their content guidelines to improve your chances of being indexed effectively.
How can I check if SeznamBot is crawling my site?
You can review your server logs to see SeznamBot's user-agent string in action. Additionally, use Seznam's webmaster tools to monitor crawl activity and identify any potential indexing issues.
Is it necessary to allow SeznamBot to crawl my website if I am targeting a non-Czech audience?
If your primary audience is not in the Czech Republic, you may choose to block SeznamBot to conserve server resources. However, if you want to reach Czech users in the future, allowing access could be beneficial.
What happens if I block SeznamBot?
Blocking SeznamBot means your website will not appear in Seznam.cz search results, which could limit visibility among Czech users. You must ensure that any access restrictions do not impede beneficial web crawlers from indexing your content.
How does SeznamBot compare to Googlebot?
While both are web crawlers, SeznamBot focuses specifically on Czech websites and content, offering better indexing for local material. Googlebot has broader global reach and advanced AI features but may not understand Czech cultural nuances as effectively as SeznamBot.
Can I control the crawl rate of SeznamBot?
Yes, if SeznamBot is crawling your site too aggressively and affecting performance, you can adjust the crawl rate through Seznam's webmaster tools. Most legitimate bots, including SeznamBot, will respect your request for a slower crawl.
What privacy measures does SeznamBot observe?
SeznamBot complies with European data protection laws, including GDPR. It gathers publicly available content for indexing purposes and respects directives in robots.txt and meta tags to control access, ensuring privacy for site owners.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.