Understanding Timpibot: Decentralized AI Crawler by Timpi
Discover Timpibot's role in decentralized AI data collection, including user-agent details and blockchain integration.
What is Timpibot and Why It Matters
Timpibot is a Web3 crawler created by Timpi, a decentralized search engine project. Unlike traditional web crawlers from companies like Google or Bing, Timpibot operates within the Web3 ecosystem, focusing on the collection of decentralized AI data. Web crawlers are automated programs visiting websites to gather data for building databases. Search engines and AI companies rely on these crawlers to gather AI training data. Timpibot distinguishes itself by combining blockchain AI technology with traditional web crawling methods. It is part of Timpi’s mission to create search infrastructures that aren’t controlled by a single company. Understanding Timpibot as developers and website owners helps in managing this new type of AI web crawler through robots.txt files and server configurations.
Technical Details of Timpibot Crawler
Timpibot in the Web3 Ecosystem:
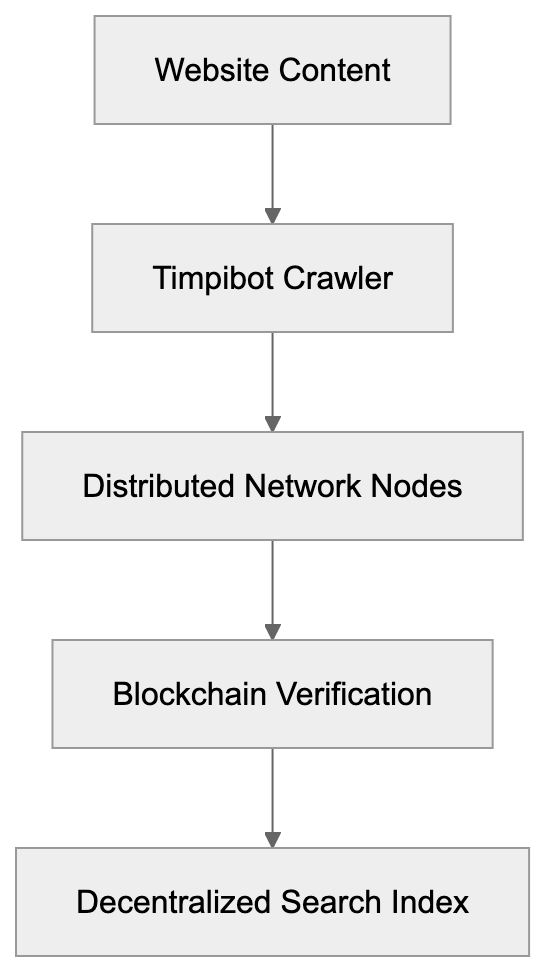
Timpibot identifies itself through a specific user-agent string when visiting websites, typically appearing as “Timpibot” in server logs, detectable in your web analytics. Website administrators can control Timpibot’s access using standard robots.txt protocols, akin to other crawlers. It respects crawl-delay directives and disallow rules when configured properly. Timpibot operates on a distributed network infrastructure instead of centralized data centers, meaning requests may come from various IP addresses linked to Timpi network nodes. The crawler focuses on indexing web content for Timpi’s decentralized search engine and potentially for Web3 AI training datasets. It follows links, processes text, and collects metadata like traditional search engine crawlers, but feeds collected data into a blockchain-based system instead of a single company’s database.
How Timpibot Works Within Web3 Infrastructure
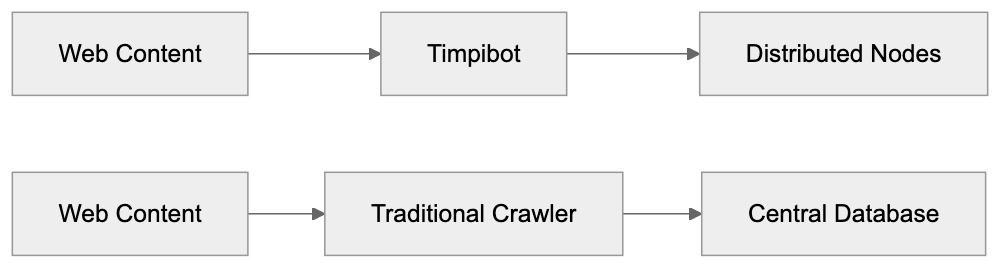
The Timpi ecosystem uses blockchain AI technology to distribute and verify collected web data. When Timpibot crawls websites, data is processed through a decentralized network of nodes. These nodes validate and store information instead of sending it to a central server. The project aims to create a verifiable, accessible search index. This fundamentally differs from how Google or Microsoft handles crawled data. Traditional crawlers feed data into proprietary databases controlled by single corporations. Timpibot’s architecture provides transparency in data collection. The blockchain component ensures an immutable record of data collection activities. Node operators in the Timpi network can earn rewards for participating in crawling and indexing, creating a different economic incentive structure than traditional crawler operations.
Traditional vs Decentralized Crawling Architecture:
Why Decentralized AI Crawlers Exist
Decentralized AI data collection addresses concerns regarding data monopolies in the AI industry. Currently, a few large tech companies control most web crawling infrastructure and datasets for AI training data. This concentration of power raises questions about bias, access, and control over information. Projects like Timpi aim to distribute this power across participant networks. Web3 AI initiatives suggest decentralizing data collection for fairer AI systems, reducing bias and censorship by removing single entity control over training data. Blockchain AI provides transparency on data collection and usage. Users and website owners may have more control over their data in decentralized systems. The economic model also differs, allowing participants to potentially earn for network contributions. These crawlers offer an alternative to traditional corporate structures in building AI training datasets.
Comparing Timpibot to Other AI Crawlers
Several AI companies operate crawlers to collect data for training purposes. They each have unique approaches, policies, and technical implementations. Understanding these differences helps website administrators make informed decisions about crawler access.
| Crawler Name | Organization | Type | Robots.txt Support | Blockchain Technology | Primary Purpose |
|---|---|---|---|---|---|
| Timpibot | Timpi | Decentralized | Yes | Yes | Decentralized search and AI |
| GPTBot | OpenAI | Centralized | Yes | No | AI model training |
| CCBot | Common Crawl | Non-profit | Yes | No | Open web archive |
| Googlebot | Centralized | Yes | No | Search indexing and AI | |
| Applebot-Extended | Apple | Centralized | Yes | No | AI training |
Timpibot stands out for its blockchain AI integration, unlike Common Crawl, which provides open datasets without blockchain verification. GPTBot and Applebot-Extended follow traditional corporate AI data collection approaches. All these crawlers respect robots.txt directives when configured correctly. Website owners can choose which crawlers to allow or block based on preferences. The decentralized nature of Timpibot means data distribution differs from centralized alternatives, but the crawling behavior is similar technically to other web crawlers.
Robots.txt Configuration for Timpibot:
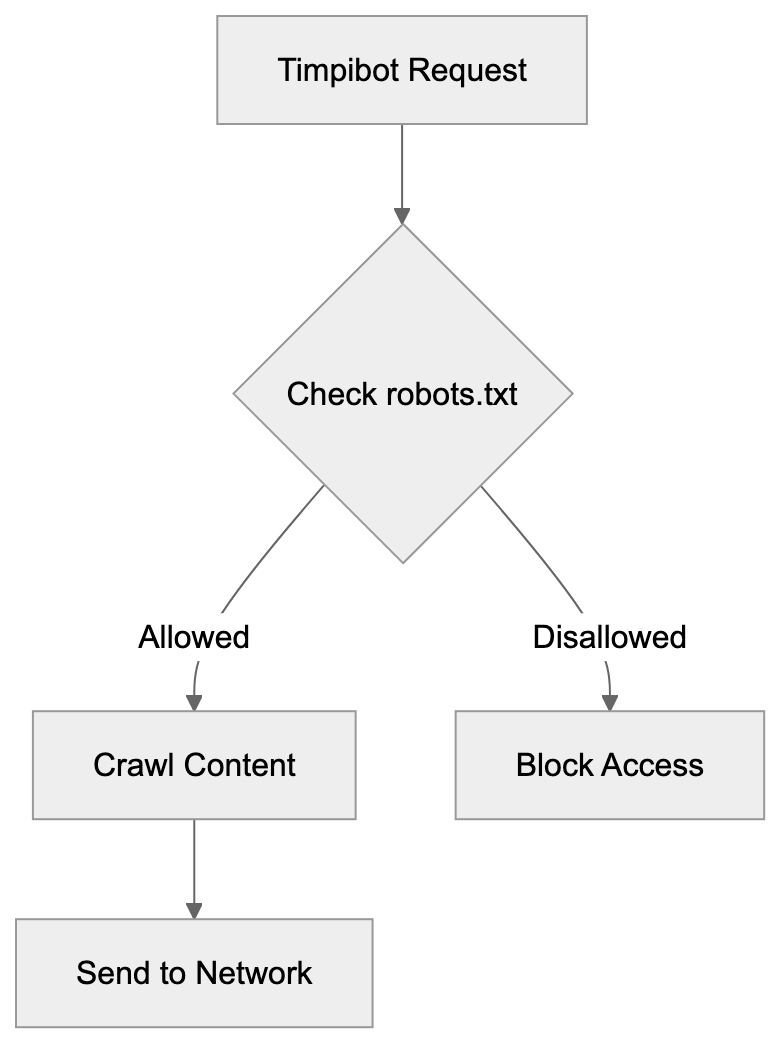
Managing Timpibot Access on Your Website
Website administrators can manage Timpibot through robots.txt configurations. To block Timpibot completely, add “User-agent: Timpibot” followed by “Disallow: /” in your robots.txt file. For partial access, specify which directories or pages the crawler can access. The crawler respects crawl-delay settings to limit request frequency. Timpibot’s decentralized nature means blocking might require additional consideration, as requests may come from multiple IP addresses rather than a single range. Rate limiting and monitoring tools can help manage the crawler’s impact on server resources. Some website owners may permit Timpibot to support decentralized web initiatives. Others may block all AI crawlers to prevent their content’s use in training datasets. The decision depends on your stance regarding AI training data and decentralized systems. Regularly check your server logs to monitor Timpibot activity if access is allowed.
Privacy and Data Usage Considerations
Timpibot collects publicly accessible web content like other crawlers, but its decentralized storage model means data is distributed across network nodes. This raises different privacy questions than centralized data storage. The blockchain AI component provides transparency on data collection but also means collected data may be harder to remove from the network. Traditional search engines can delete cached content upon request through proper channels. Decentralized systems might not offer the same removal capabilities due to their distribution. Website owners should consider these factors when deciding on Timpibot access. Public data you are comfortable with traditional search engines indexing may have different implications in decentralized systems. Timpi provides documentation on data handling and privacy policies. Review these materials if concerned about how your website content is used. Understanding the difference between centralized and decentralized data storage informs access decisions.
The Future of Decentralized Web Crawling
Decentralized AI crawlers represent an emerging approach to web data collection. The technology is still developing and faces challenges regarding scalability and adoption. Traditional crawlers have decades of improvement and infrastructure development behind them. Web3 crawlers like Timpibot need to demonstrate they can match this effectiveness while maintaining decentralization. These projects’ success depends on network participation and community support. More website owners and developers need to engage with decentralized systems for them to become viable alternatives. Blockchain technology continues evolving and might solve storage and verification limitations. The debate on AI training data ownership and control will likely drive interest in decentralized solutions. Regulatory changes may impact companies’ data collection and usage for AI, benefiting projects like Timpi under increased scrutiny of centralized data practices. However, they face their own regulatory and technical challenges as they scale.
Timpibot offers a novel approach to web crawling for AI and search applications. It combines traditional web scraping methods with blockchain technology and decentralized infrastructure. Unlike centralized crawlers from major tech companies, Timpibot distributes data across network nodes. Website administrators can manage Timpibot access through standard robots.txt configurations and server settings. The crawler complies with common web standards within a Web3 framework. Understanding Timpibot helps developers and website owners make informed decisions about crawler access. The decentralized model provides potential benefits in transparency and data control, but also introduces different considerations for privacy and data removal. As AI training data collection evolves, decentralized crawlers like Timpibot may play an increasingly important role. Whether you choose to allow or block this crawler depends on your views on decentralized systems and AI data collection. Monitoring crawler activity and staying informed of developments in this area helps you manage your web presence effectively.
Frequently Asked Questions
What types of data does Timpibot collect?
Timpibot collects publicly accessible web content, including text, links, and metadata, similar to traditional web crawlers. Its decentralized nature means that collected data is stored across a network of nodes rather than a single server, enhancing transparency and control.
How can I control Timpibot's access to my website?
You can manage Timpibot's access through your site's robots.txt file. To block Timpibot completely, use "User-agent: Timpibot" followed by "Disallow: /". For partial access, specify which sections of your website Timpibot is allowed to crawl.
What are the privacy implications of allowing Timpibot to crawl my site?
Allowing Timpibot may raise different privacy concerns compared to traditional crawlers. The decentralized storage model means that once data is collected, it may be harder to remove from the network. Ensure you review Timpi's documentation on data handling before allowing access.
Can I earn rewards by participating in Timpibot's network?
Yes, node operators in the Timpi network can earn rewards for contributing to crawling and indexing web data. This decentralized economic model incentivizes participation in the network, contrasting with traditional crawler operations.
How does Timpibot differ from traditional crawlers?
Timpibot utilizes blockchain technology to create a decentralized and verifiable data collection process, unlike traditional crawlers that feed data into proprietary databases. This new approach aims to reduce data monopolies and promote fairer AI systems by distributing power across participant networks.
What should I monitor if I allow Timpibot on my site?
If you permit Timpibot to crawl your website, it's important to regularly check your server logs to monitor its activity. This can help you evaluate the impact on your server resources and adjust configurations if necessary.
What challenges do decentralized crawlers like Timpibot face?
Decentralized crawlers encounter challenges such as scalability and user adoption. While traditional crawlers benefit from established infrastructure, decentralized systems like Timpibot must demonstrate their effectiveness and gain widespread support to succeed in the market.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.