Comprehensive Guide to webzio-extended: Webz.io's AI Crawler
Learn about webzio-extended crawler for AI training data, its purpose, user-agent details, blocking methods, and how it differs from Omgilibot.
Introduction
The webzio-extended crawler is a specialized web bot operated by Webz.io for collecting web data, crucial for AI training datasets. Part of Webz.io’s broader infrastructure, it provides structured web data to companies building AI models. Web crawlers like webzio-extended exist because AI models need massive amounts of text data to train effectively, as highlighted in Appen’s AI data collection services. These bots visit websites automatically, extracting content that later gets packaged into datasets for machine learning purposes. Specifically, the webzio-extended bot focuses on extended web data collection beyond the standard Omgilibot crawler’s tasks. Website owners and developers must understand how this crawler operates, what data it collects, and how to manage its access to their sites.
What is webzio-extended
webzio-extended is a web crawler bot managed by Webz.io, specializing in web data extraction and structuring. It crawls websites to collect publicly available content, which is then processed into structured datasets. These datasets are licensed to companies for various purposes, including AI model training.
The crawler identifies itself through a specific user-agent string that appears in web server logs, a practice common among web crawlers as discussed in Common Crawl’s methodology. Website administrators can detect and control this bot by recognizing its user-agent pattern. Unlike general search engine crawlers, which index content for search results, webzio-extended specifically targets data collection for commercial licensing purposes.
Webz.io Crawler Ecosystem:
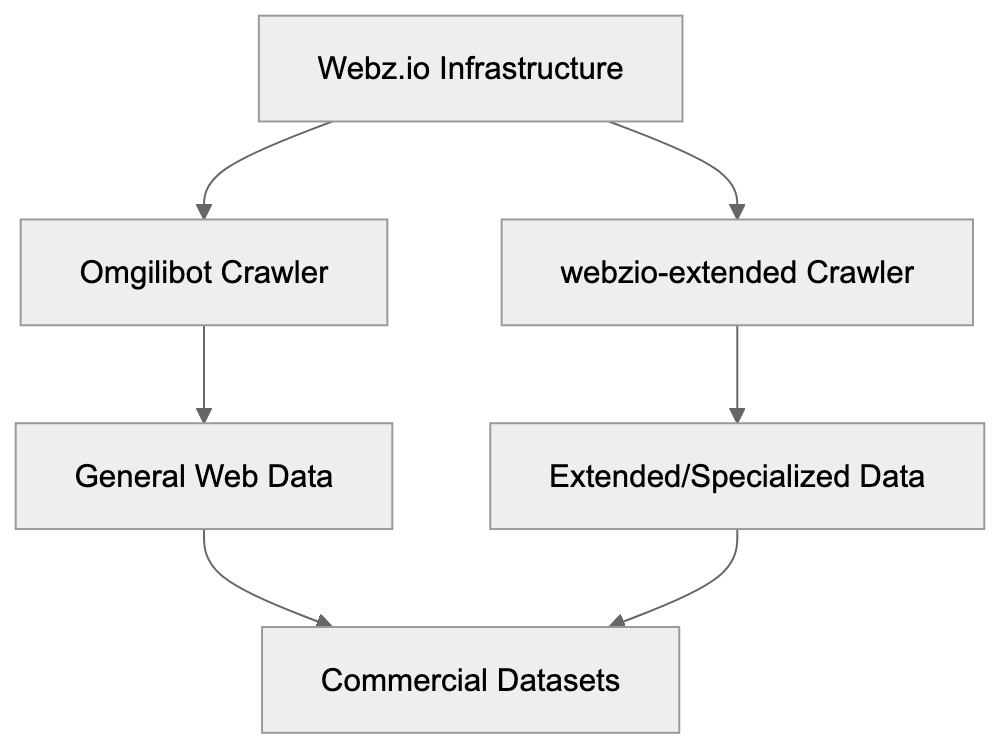
Webz.io operates this crawler alongside the Omgilibot crawler, but webzio-extended serves a different function. While Omgilibot centers on general web data collection, webzio-extended manages extended or specialized data gathering tasks. Webz.io markets their collected data as cyber threat intelligence feeds, news data, and web content datasets.
The bot respects properly configured robots.txt files, adhering to standard web protocols for crawler behavior. Site owners who want to block this crawler need to add specific rules to their robots.txt file. The user-agent string allows for easy tracking in server logs, facilitating the monitoring of its activity on websites.
User-Agent String and Technical Details
The webzio-extended crawler uses a distinctive user-agent string to be easily identifiable:
Mozilla/5.0 (compatible; webzio-extended/1.0; +http://webz.io/bot)This user-agent string contains essential components. The “Mozilla/5.0” prefix is standard for web crawlers to maintain web server compatibility. “Compatible” indicates adherence to standard web protocols. The “webzio-extended/1.0” clearly identifies the bot name and version number.
The included URL (http://webz.io/bot) provides documentation about the crawler, aiding website owners in making informed decisions about allowing or blocking the crawler.
The crawler operates from IP addresses owned or leased by Webz.io, which can change as the company scales its infrastructure. Relying solely on IP blocking is not recommended as the user-agent string provides a more reliable identification method.
In server logs, requests from webzio-extended appear alongside other bot traffic. The crawler makes GET requests to various site pages, with request frequency depending on the site’s size and update frequency. Many websites report seeing daily requests.
Why webzio-extended Exists and Its Purpose
Data Collection and Distribution Flow:

The webzio-extended crawler exists due to the high commercial demand for web data in training AI models. Companies building large language models, content recommendation systems, and other AI applications require vast amounts of text data. Collecting this data at scale demands specialized infrastructure and expertise.
Webz.io positions itself as a data provider handling the complex processes of web crawling, data extraction, and structuring. Instead of companies building their own crawlers and facing legal and technical challenges, they can license pre-collected datasets from Webz.io. This business model involves crawling public web content and selling access to that structured data.
The webzio-extended crawler handles extended or supplementary data collection beyond what the main Omgilibot crawler does. This may involve targeting specific content types, handling different data formats, or collecting data for specialized datasets. Webz.io offers multiple data products, and using separate crawlers for different tasks makes operational sense.
AI training requires varied data sources to create effective models. For instance, a language model trained solely on news articles would perform poorly in casual conversation. Therefore, data collectors like Webz.io crawl various website types, including forums, blogs, social media, news sites, and e-commerce platforms. The webzio-extended crawler likely targets specific site categories or content types.
The commercial data collection industry has grown significantly alongside AI development. Companies are willing to pay substantially for quality training data, which economically incentivizes companies like Webz.io to operate multiple specialized crawlers and continuously expand their data collection efforts.
How Companies and Users Utilize Data from webzio-extended
Companies license data collected by webzio-extended primarily for AI model training. Tech firms creating large language models need billions of words of text data to help models learn language patterns, factual information, and reasoning capabilities. This collected web data becomes part of the training datasets fed into neural networks.
Cybersecurity firms utilize Webz.io’s data for threat intelligence. The company markets datasets with information about cyber threats, data leaks, and security vulnerabilities discovered online. This data aids security teams in proactively identifying emerging threats and protecting systems.
Marketing and business intelligence teams use web data for competitive analysis and market research. By analyzing content from competitor websites and industry forums, companies gain insights into market trends and customer sentiment. Webz.io structures this data to make it searchable and analyzable at scale.
News organizations and media monitoring services license web data to track breaking news and trending topics. The structured data enables them to quickly identify significant stories emerging from numerous sources, maintaining competitiveness in fast-moving news cycles.
Research institutions sometimes use commercial web datasets for academic studies about online behavior, content trends, and information spread. However, licensing commercial data can be costly, limiting its use compared to freely available datasets.
Small businesses and individual developers typically cannot afford direct access to Webz.io’s products. The company targets enterprise customers with substantial budgets, but data collected by webzio-extended may end up in public AI models that small developers access through APIs.
Blocking webzio-extended and Data Collection Control
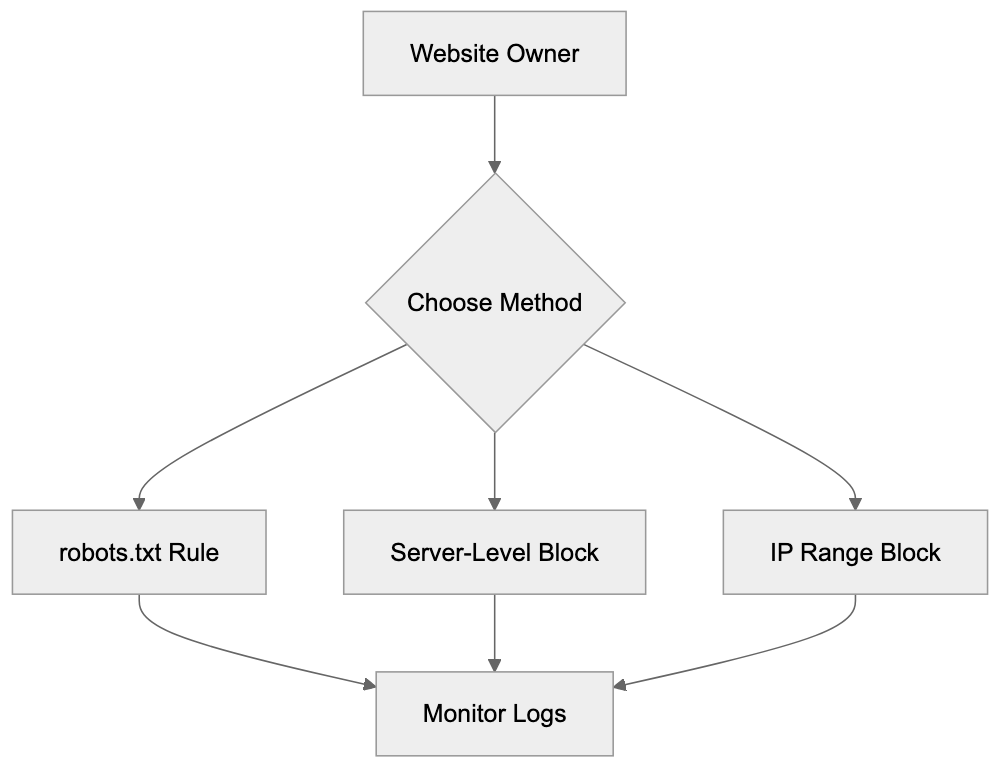
Website owners wishing to stop webzio-extended from crawling their sites have several options. The most straightforward method is using the robots.txt file to guide crawlers on which parts of the site to avoid.
To block webzio-extended specifically, add these lines to your robots.txt file:
User-agent: webzio-extended
Disallow: /This rule directs the webzio-extended crawler not to access any part of your site. While the crawler should respect this directive if it follows standard robots.txt protocols, some crawlers ignore these rules.
For more aggressive blocking, configure your web server to return 403 Forbidden responses to requests from the webzio-extended user-agent. This requires server-level configuration in Apache, Nginx, or similar software, with syntax depending on your server setup.
Some site owners block entire IP ranges associated with Webz.io, but this method needs ongoing maintenance as IPs change. User-agent based blocking is generally more reliable and easier to maintain.
If you want to allow the crawler but limit its access, use robots.txt to permit specific directories. For instance, allow crawling of your blog but block account pages, giving you granular control over collected data.
Monitor your server logs to ensure blocking measures are effective. Look for the webzio-extended user-agent string and confirm blocked requests receive appropriate error responses. If requests continue successfully after implementing blocks, adjustments to your configuration may be necessary.
Some content management systems and hosting platforms offer built-in bot management features. Check if your platform provides options to block specific crawlers without manual server adjustments. WordPress plugins and similar tools can simplify this process for non-technical users.
Comparison with Similar AI Training Crawlers
Blocking webzio-extended Process:
 The webzio-extended operates in a crowded market of web crawlers collecting data for AI training and commercial purposes. Understanding its comparison to alternatives helps website owners make informed decisions about crawler access.
The webzio-extended operates in a crowded market of web crawlers collecting data for AI training and commercial purposes. Understanding its comparison to alternatives helps website owners make informed decisions about crawler access.
| Crawler Name | Company | Primary Purpose | Respects robots.txt | Data Licensing |
|---|---|---|---|---|
| webzio-extended | Webz.io | Extended web data collection for AI training | Yes | Commercial licensing |
| Omgilibot | Webz.io | General web data collection | Yes | Commercial licensing |
| CCBot | Common Crawl | Building free web archive for AI training | Yes | Free public dataset |
| GPTBot | OpenAI | Training ChatGPT and GPT models | Yes | Internal use only |
| Google-Extended | Training Bard and AI models | Yes | Internal use only |
webzio-extended differs from Omgilibot despite being a Webz.io product. While Omgilibot manages primary web crawling operations, webzio-extended is meant for specialized or extended data collection tasks. Website administrators should block both crawlers if preventing all Webz.io data collection is their goal.
CCBot from Common Crawl employs a different model where collected data is freely available to researchers and developers, unlike Webz.io, which maintains proprietary data for commercial licensing.
GPTBot and Google-Extended are operated by major tech companies for internal AI model training. This differentiates them from Webz.io’s business model of data brokerage.
All these crawlers claim adherence to robots.txt directives, but enforcement varies. Some crawlers are more aggressive in terms of crawl frequency. webzio-extended generally receives fewer complaints about excessive crawling than other commercial data collectors.
The commercial data collection market includes multiple players beyond those listed. Firms like Diffbot and Import.io operate their crawlers, each with different technical characteristics and models. To prevent content from entering commercial datasets, multiple crawler blocks may be necessary.
Data Licensing and Legal Considerations
Webz.io operates a commercial data licensing business built on public webpage content crawling. It packages this content into structured datasets customers pay to access. This model exists in a complex legal landscape regarding web scraping and data rights.
In many jurisdictions, crawling publicly accessible web content is legal. Courts usually rule that automated access to public web pages does not violate computer fraud laws, but specifics and legal protections vary by country. Some website terms of service prohibit scraping, even if technically legal.
Website owners objecting to their content collection often have limited legal recourse. If content lacks authentication, data collectors argue they are allowed access. Some have successfully used technical measures and legal threats to halt unwanted crawling, but outcomes differ widely.
The EU’s database rights and copyright laws offer stronger protection for website owners compared to US law, providing additional legal tools to prevent unauthorized data collection, although enforcement remains challenging.
AI training introduces new copyright questions. Using copyrighted content to train AI models may qualify as fair use under some legal theories. Courts have yet to fully address these questions, with several lawsuits underway. Their outcomes will greatly impact the data collection industry.
Webz.io’s customers licensing data also face legal risks. If data contains copyrighted material or personally identifiable information, its use in AI training could result in liability. Responsible companies conduct legal reviews before licensing third-party datasets.
Concerned website owners should implement technical blocking measures instead of relying mainly on legal protections. Robots.txt files, user-agent blocking, and access controls provide immediate protection. Legal actions are usually last resorts for significant violations.
Monitoring and Managing Crawler Traffic
Website administrators should actively monitor crawler traffic to track bots accessing their sites and assess server resource consumption. webzio-extended and similar crawlers can generate significant traffic on larger websites, where monitoring aids in informed decisions about crawler access.
Server logs provide detailed records of requests made to a website, including the user-agent string. Regular log reviews reveal crawler traffic patterns, identifying webzio-extended activity by tracking the frequency and type of requests made.
Many web analytics tools and server monitoring platforms feature bot detection and reporting. These tools categorize traffic and offer dashboards displaying crawler activity trends, simplifying monitoring compared to manual log parsing.
High crawler traffic can impact website performance and hosting costs. If webzio-extended or other crawlers request excessively, they use server resources meant for human visitors. This is particularly problematic for websites on limited hosting plans with bandwidth caps or resource limits.
Some crawlers disregard politeness guidelines, crawling aggressively. A respectful crawler should limit its request rate and consider server capacity. If webzio-extended makes numerous requests within a minute, rate limiting or blocking might be necessary.
The robots.txt file can include crawl-delay directives, requesting crawlers to space out requests, although not all adhere to this. Implementation testing is needed to verify compliance.
Content Delivery Networks and DDoS protection services often have bot management features. Platforms like Cloudflare or Akamai can automatically challenge or block suspicious bot traffic, adding an extra layer of control beyond basic robots.txt rules.
For sensitive or proprietary content, implementing authentication requirements should be considered. Content behind login walls cannot be crawled by bots like webzio-extended, offering the strongest protection against unwanted collection, although it limits public visibility.
Conclusion
The webzio-extended crawler typifies the commercial aspect of web data collection for AI training. Operated by Webz.io alongside their Omgilibot crawler, it gathers publicly accessible web content packaged into licensed datasets. Website owners should recognize that allowing this crawler means potential inclusion of their content in AI models via Webz.io’s commercial licensing.
Blocking webzio-extended involves appropriate robots.txt rules or server-level blocks based on the user-agent string. The crawler usually respects robots.txt directives, simplifying control. However, active monitoring and management of crawler access are essential, as default settings may not protect interests.
The wider landscape of AI training crawlers includes many similar bots from various companies. webzio-extended is just one player in the growing market of commercial web data collection. Concerned website owners should consider blocking multiple crawlers and staying informed about emerging bots. The evolving legal and technical environment surrounding AI development will continue to influence data rights and fair use considerations.
Frequently Asked Questions
What types of data does the webzio-extended crawler collect?
The webzio-extended crawler collects a wide range of publicly available content from various websites. This includes text data from news articles, forums, blogs, social media, and e-commerce platforms, which is structured into datasets for licensing to companies.
How can I monitor the activity of webzio-extended on my website?
Website administrators can track the activity of the webzio-extended crawler by reviewing server logs where requests made by its user-agent string are logged. Additionally, using web analytics tools that provide bot detection features can simplify monitoring and reporting of crawler traffic.
Can the webzio-extended crawler be blocked effectively?
Yes, the webzio-extended crawler can be effectively blocked by using a properly configured robots.txt file or by returning 403 Forbidden responses to its user-agent. Monitoring server logs after implementing these blocks ensures that the measures are working as intended.
Is it legal to block crawlers like webzio-extended from accessing my website?
Yes, website owners have the right to block crawlers like webzio-extended from accessing their sites. Implementing technical measures such as using a robots.txt file to specify which parts of the site should not be crawled is a standard practice in web management.
What should I do if my website is experiencing high traffic from the webzio-extended crawler?
If high traffic from the webzio-extended crawler is impacting your website's performance, consider implementing rate limiting or blocking measures. You may also set crawl-delay directives in your robots.txt file to request that the crawler spaces out its requests.
How does webzio-extended differ from other crawlers?
While many crawlers gather web data, the webzio-extended crawler specializes in extended data collection specifically for commercial purposes, unlike general-purpose crawlers. It focuses on structuring data for licensing, primarily aimed at AI training and commercial intelligence.
What precautions should I take regarding the data collected by webzio-extended?
Website owners should implement technical measures to protect sensitive or proprietary content by requiring authentication, as this content cannot be crawled. Additionally, regularly reviewing legal rights and understanding data protection laws can be crucial in ensuring compliance with data usage in AI training.
Track Your AI Visibility
See how AI chatbots like ChatGPT, Claude, and Perplexity discover and recommend your brand.