
Comprehensive Guide to 360Spider: The Qihoo Search Crawler
Explore 360Spider's role in Qihoo's search engine for indexing the Chinese web. Includes features, versions, and security integration options.
14 min read
Explore 360Spider's role in Qihoo's search engine for indexing the Chinese web. Includes features, versions, and security integration options.
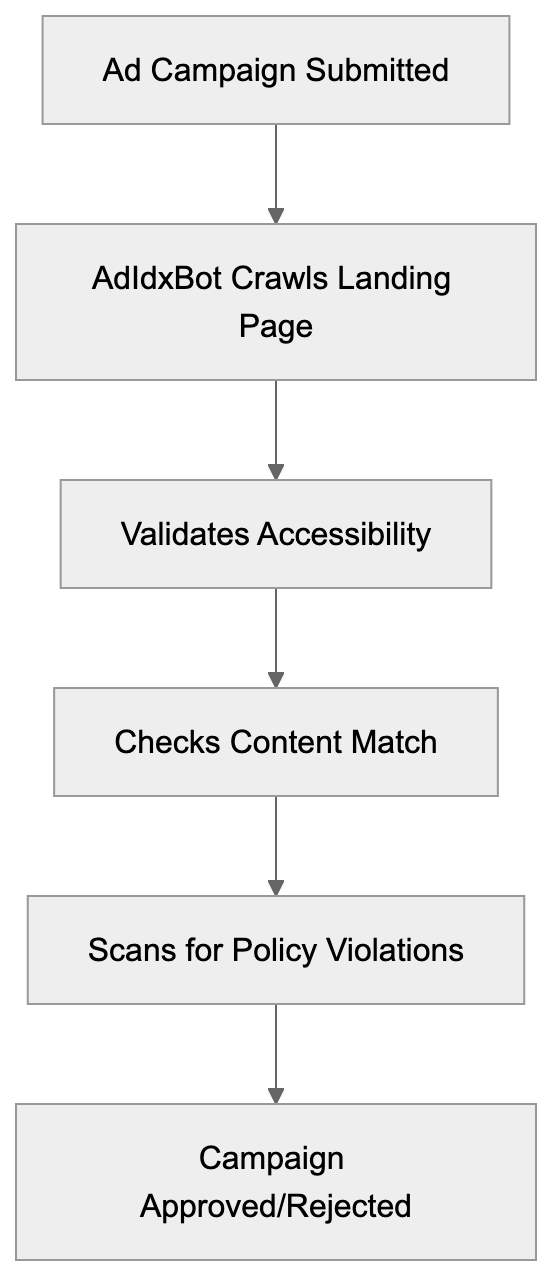
Learn how AdIdxBot validates landing pages and verifies ad quality for Microsoft Advertising campaigns. Technical details for developers.
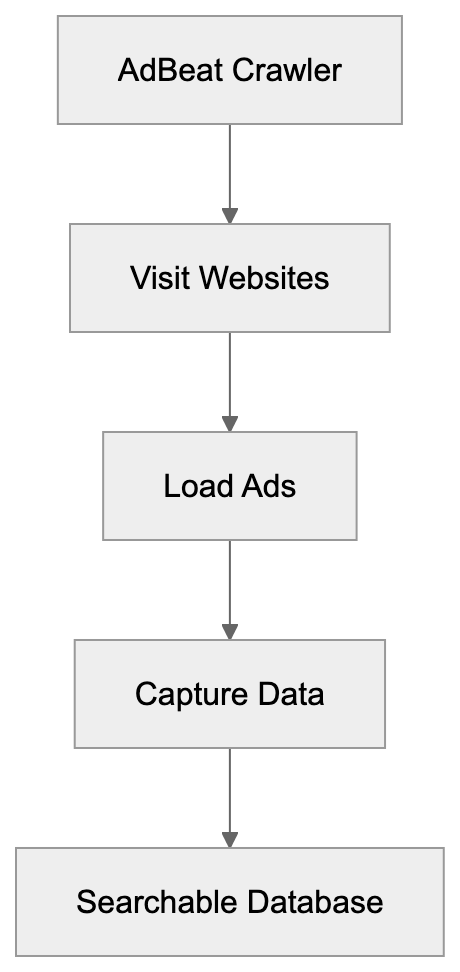
Learn about AdBeat's crawler for competitive ad analysis and tracking. Discover user-agent strings, use cases, and blocking options.
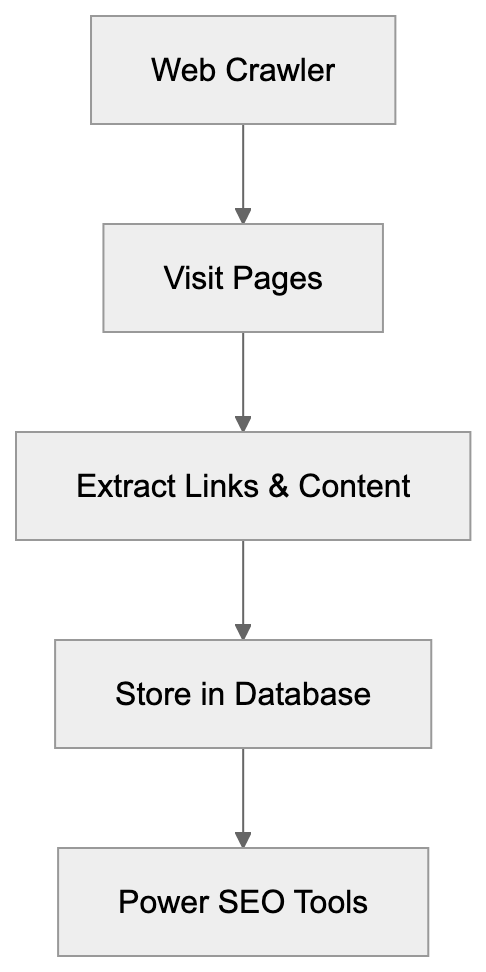
Learn what makes AhrefsBot one of the most active web crawlers in SEO. Covers backlink analysis, rate limiting, and SEO industry impact.
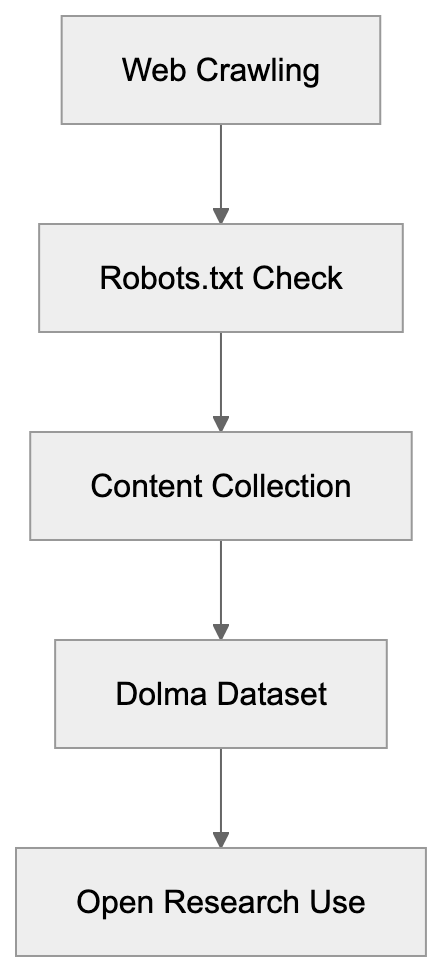
Explore the purpose and technology behind AI2Bot-Dolma, the crawler for the Dolma dataset by Allen AI, and its role in open AI data initiatives.
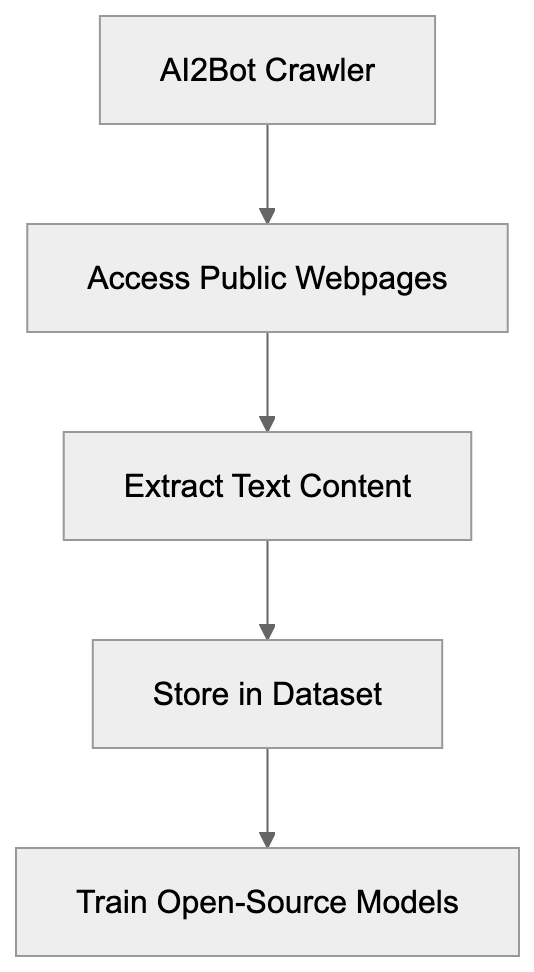
Learn about AI2Bot, Allen Institute's web crawler for open-source AI training. How it works, its purpose, and impact on AI research.
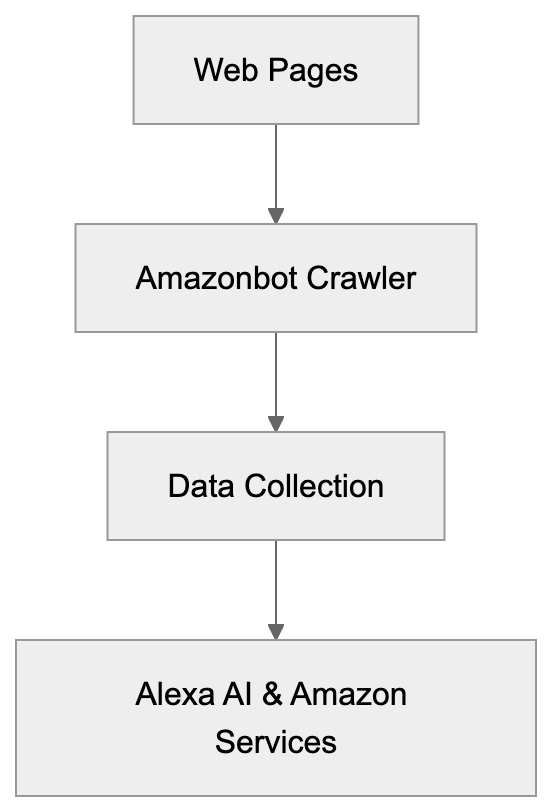
Learn about Amazonbot web crawler, its role in Alexa AI, user-agent details, and how to manage or block its crawling activities on your site.

Learn about the legacy Anthropic-AI crawler, its transition to ClaudeBot, user-agent strings, and how to block it in robots.txt files.
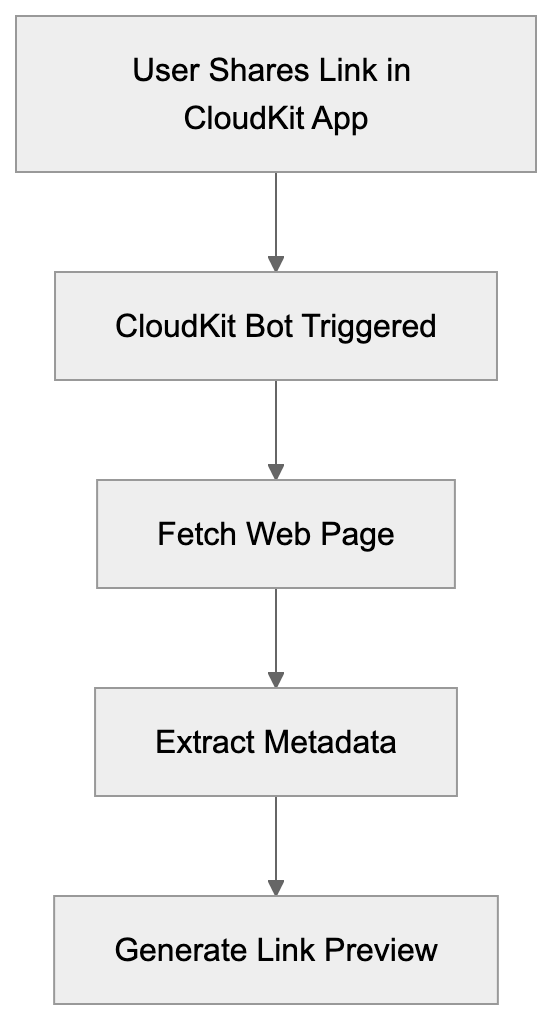
Learn about the Apple-CloudKit bot's purpose, user-agent string, developer features, and blocking considerations for web developers.