Common Crawl Presence Guide: Check Your Site in AI Data
Learn how to check if your website is in Common Crawl's archive, understand CCBot crawling cycles, and decide if presence benefits your business.
Table of Contents
- How Common Crawl Works and Crawling Cycles
- Checking Your Common Crawl Presence
- Understanding CCBot and Blocking Options
- Common Crawl vs Alternative Web Archives
- How AI Models Use Common Crawl Data
- Strategic Considerations for Businesses
- Monitoring Your CCBot Activity
- The Reality of Content Removal
- Making an Informed Decision
- Conclusion
- How Common Crawl Works and Crawling Cycles
- Checking Your Common Crawl Presence
- Understanding CCBot and Blocking Options
- Common Crawl vs Alternative Web Archives
- How AI Models Use Common Crawl Data
- Strategic Considerations for Businesses
- Monitoring Your CCBot Activity
- The Reality of Content Removal
- Making an Informed Decision
- Conclusion
What is Common Crawl and Why It Matters
Common Crawl is a nonprofit organization that runs web crawlers to create a massive archive of web pages. This archive contains over 300 billion pages and is updated monthly, providing a comprehensive snapshot of the web. It has emerged as the primary source of AI training data for various language models, including GPT-3, Claude, and LLaMA, which utilize diverse datasets for training. These models use Common Crawl data during training, though not all versions necessarily rely on it.
The crawler, known as CCBot, regularly visits websites to record their content, adhering to web standards and protocols. After each monthly crawl, the data is added to their public archive, freely available for download, supporting research and development in AI and machine learning. This wide accessibility makes it invaluable for AI companies. Website owners should be aware that their content may already be part of the training data for several AI models.
Understanding your Common Crawl presence impacts whether AI systems learn from your content. If you publish industry expertise, product information, or specialized knowledge, being in Common Crawl means AI models might reference your content when answering related questions. However, some businesses may prefer to keep their information out of AI training datasets for competitive or privacy reasons.
How Common Crawl Works and Crawling Cycles
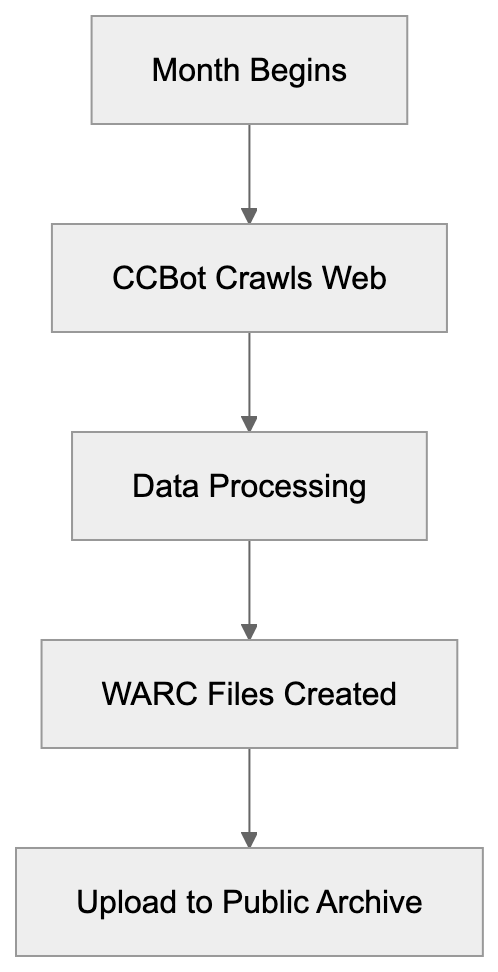
Common Crawl operates on a monthly cycle. Each month, CCBot visits billions of web pages to record their current state. It respects robots.txt files and crawl-delay directives but covers as much of the web as possible.
When CCBot visits your site, it downloads the HTML content and some linked resources. The data is processed and stored in WARC files, a standard format for web archives. These files are then uploaded to Amazon S3 for public access.
Common Crawl Monthly Cycle:
The crawls, starting in the first week each month, can take 3 to 4 weeks. The new dataset usually becomes available 4 to 6 weeks after the crawl commences. CCBot does not crawl every page monthly, prioritizing pages based on factors like change frequency, linking structure, and previous crawl history.
Checking Your Common Crawl Presence
You can check your Common Crawl presence by querying their index server. The Common Crawl Index Server API allows you to search specific URLs without downloading the entire dataset.
To check, construct a URL query including your domain name, using the pattern http://index.commoncrawl.org/CC-MAIN-YYYY-WW-index, where YYYY-WW denotes the year and week number. Alternatively, use the web interface at index.commoncrawl.org to see which crawls include pages from your site.
Developers can automate this process through API, sending a GET request with your URL, returning JSON data of that URL’s captures. Remember, crawling does not guarantee inclusion in the final dataset due to filtering of duplicates or low-quality pages.
Understanding CCBot and Blocking Options
CCBot identifies itself with the user agent string “CCBot/2.0,” making it easy to detect in server logs and analytics tools. You can block CCBot by adding directives to your robots.txt file:
User-agent: CCBot
Disallow: /This prevents future crawls, but not removal of already archived content. Once crawled, content remains permanently in the Common Crawl archive.
There is no official process for Common Crawl removal. The archive is a historical web record, and blocking CCBot now won’t affect past inclusions. Some try using noai or noarchive meta tags, but CCBot does not officially support these directives. The best prevention is proactive blocking.
Common Crawl vs Alternative Web Archives
Common Crawl differs from other web archives in purpose and policy:
| Archive | Size | Update Frequency | Primary Use | Removal Policy | Access |
|---|---|---|---|---|---|
| Common Crawl | 300+ billion pages | Monthly | AI training, research | No removal | Free, public |
| Internet Archive | 700+ billion pages | Continuous | Historical preservation | Removal on request | Free, public |
| Google Cache | Unknown | Continuous | Search indexing | Automatic expiration | Free, limited |
| Bing Cache | Unknown | Continuous | Search indexing | Automatic expiration | Free, limited |
| Archive.today | Unknown | On-demand | Permanent snapshots | No removal | Free, public |
Web Archive Comparison:
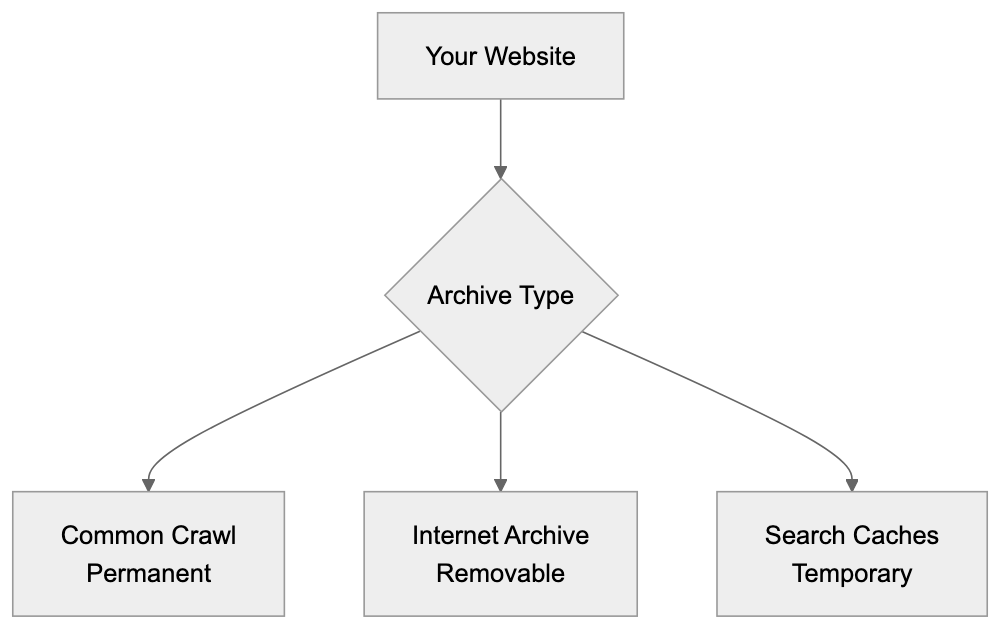
Internet Archive’s Wayback Machine allows exclusion-based content removal that Common Crawl does not. Google Cache and Bing Cache are temporary, unlike Common Crawl, which is crucial for research and LLM training data.
How AI Models Use Common Crawl Data
Most language models utilize Common Crawl during training. It provides diverse text data to help models learn language patterns and reasoning abilities.
AI Training Data Pipeline:

AI training involves downloading and filtering Common Crawl archives to remove low-quality or duplicate content, with remaining data tokenized and integrated into training pipelines.
Different models utilize various subsets of Common Crawl. GPT-3, for example, used 45TB of text data, with Common Crawl significantly represented. Monthly updates make new data regularly available, though retraining is costly, limiting models to specific snapshots.
AI companies may supplement with licensed or proprietary data, but Common Crawl remains foundational due to its size, accessibility, and update frequency.
Strategic Considerations for Businesses
Deciding on your Common Crawl presence involves aligning with business goals. For brand awareness, inclusion can reinforce industry expertise by having AI reference your content.
If your business relies on proprietary knowledge, public AI training datasets can diminish competitive advantages. Competitors might leverage AI models trained on your unique content.
Content creators face mixed incentives, balancing potential traffic reduction from AI with increased discovery and reach.
Blocking CCBot now can’t remove past content. Businesses might selectively block sensitive internal data while allowing broader public content.
Monitoring Your CCBot Activity
Tracking CCBot visits clarifies how often Common Crawl indexes your content. Most analytics tools can detect CCBot via its user agent string “CCBot/2.0.”
Review server logs by isolating CCBot requests to understand crawl frequency, which varies by site authority and content update rate.
Analyzing patterns in CCBot activity can inform strategic content adjustments, such as tailoring internal linking to guide archiving priorities.
The Reality of Content Removal
You cannot remove content already in Common Crawl. The archive is a permanent historical record, with no removal policy except in extraordinary legal circumstances.
This differs from Google or Internet Archive, which provide removal options. The legal landscape is evolving with privacy regulations like GDPR, but its application to nonprofit archives remains ambiguous.
To exclude content from future AI training datasets, block CCBot preemptively and understand AI companies’ exclusion processes, which are often lacking.
Making an Informed Decision
Your Common Crawl strategy should align with broader business goals. Start by checking your current presence using the index server and consider the potential impact.
Evaluate whether AI training data inclusion helps or hinders goals. For most, the impact is neutral to positive, with content contributing to AI knowledge bases.
If you choose to block CCBot, ensure correct implementation of robots.txt, confirm changes work, and monitor logs for compliance.
Remember, blocking CCBot doesn’t affect other crawlers. Separate rules for different user agents are necessary for comprehensive blocking. Consider timing, especially when launching proprietary content.
Conclusion
Common Crawl maintains a vast archive exceeding 300 billion pages, crucial for LLM training data. While CCBot crawls monthly and archives publicly, businesses must understand blocking only prevents future crawling and doesn’t remove existing content. Inclusion decisions depend on business models and goals, balancing the benefits of AI-crafted influence against risks of proprietary exposure. Most businesses find neutral to positive impacts, but informed strategies about Common Crawl check and management are vital.
Frequently Asked Questions
How can I check if my website is included in Common Crawl?
You can check your website's presence in Common Crawl by querying their index server. Use the URL pattern http://index.commoncrawl.org/CC-MAIN-YYYY-WW-index, replacing YYYY-WW with the year and week number, or visit the web interface at index.commoncrawl.org for a straightforward search.
What should I do if I want to prevent my site from being crawled by CCBot?
To prevent CCBot from crawling your website, you can add directives to your `robots.txt` file. Specifically, include 'User-agent: CCBot' followed by 'Disallow: /' to stop future crawls. However, this will not affect content already archived.
Can I remove content from Common Crawl once it has been archived?
No, once your content has been crawled and archived by Common Crawl, it cannot be removed. Common Crawl serves as a permanent historical record, and there is no official process for content removal except under specific legal circumstances.
What are the implications of my content being used in AI training datasets?
If your content is included in Common Crawl, it may be referenced by AI models in training data that can be used in various applications. This can enhance your brand's visibility but might expose proprietary information, which businesses should carefully consider before deciding to block CCBot.
How often does Common Crawl update its dataset?
Common Crawl updates its dataset on a monthly basis. Each month, CCBot visits billions of web pages, and new datasets usually become available 4 to 6 weeks after the crawls begin.
Is there a way to see how frequently CCBot visits my site?
Yes, you can monitor CCBot's activity by checking your server logs for requests from the user agent string 'CCBot/2.0'. This will help you understand how often CCBot indexes your content and can provide insights for strategic adjustments.
What is the difference between Common Crawl and other web archives?
Common Crawl differs from other web archives primarily in its update frequency, purpose, and removal policies. Unlike the Internet Archive, which allows content removal requests, Common Crawl's archival is permanent and primarily aims to support AI training and research with no removal options.